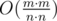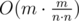572A - Массивы
In this problem one need to check whether it's possible to choose k elements from array A and m elements from array B so that each of chosen element in A is less than each of chosen elements in B. If it's possible then it's possible to choose k smallest elements in A and m largest elements in B. That means that in particular, k-th smallest element of A is less than m-th largest element in B. So, if A[k] < B[n - m + 1] then the answer is "YES" and if not, then the answer is "NO".
Problem author: zeliboba.
Problem developers: riadwaw, Kostroma.
Solution code: 12873382.
572B - Биржевые заявки
First of all the problem may be solved for buy orders and sell orders separately.
The easiest soultion is to use structure like std::map or java.lang.TreeMap. To aggregate orders we just add volume to the corresponding map element: aggregated[price] += volume.
After that we should extract lowest (or largest) element from map s times (or while it's not empty).
Complexity of this solution is O(nlogn).
It is also possible to solve the problem without data structres other than an array. You should just maintain at most s best orders in sorted order and when adding another order you insert it in appropriate place and move worse elements in linear time of s. Complexity of this solution is O(sn).
Problem authors and developers: ArtDitel, yarrr.
Solution code: 12873385.
571A - Удлинение палочек
Let's count the number of ways to form a triple which can't represent triangle sides, and then we subtract this value from 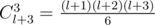 — the total number of ways to increase the sticks not more than l in total. This number is obtained from partition of l into 4 summands (la + lb + lc + unusedl = l), or can be counted using a
— the total number of ways to increase the sticks not more than l in total. This number is obtained from partition of l into 4 summands (la + lb + lc + unusedl = l), or can be counted using a for loop.
Now we consider triples a + la, b + lb, c + lc, where la + lb + lc ≤ l, la, lb, lc ≥ 0. Fix the maximal side, for example it would be a + la. We'll have to do the following algo for b + lb and c + lc in the same way. The triple is not a triangle with maximal side a + la if a + la ≥ b + lb + c + lc. If we iterate over la between 0 and l, we have the following conditions on lb, lc:
lb + lc ≤ a - b - c + la, lb + lc ≤ l - la, lb, lc ≥ 0. So, non-negative integers lb, lc should be such that lb + lc ≤ min(a - b - c + la, l - la). If we denote this minimum as x than we can choose lb, lc in 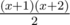 different ways (again we divide x into three summands: lb, lc and some unused volume). Also when we fix lb, there are x - lb + 1 ways to choose lc, so the overall number of pair lb, lc is
different ways (again we divide x into three summands: lb, lc and some unused volume). Also when we fix lb, there are x - lb + 1 ways to choose lc, so the overall number of pair lb, lc is
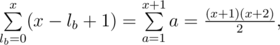
so we obtain the same formula.
To sum up, we need to iterate over the maximal side and over the addition to that side, then write these formulas, and subtract the result from the total number of different additions to the sides. The complexity of the solution is O(l).
Problem author: Kostroma.
Problem developers: Kostroma, riadwaw.
Solution code: 12873406.
571B - Минимизация
We can divide all indices [1;n] into groups by their remainder modulo k. While counting 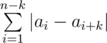 , we can consider each group separately and sum the distances between neighbouring numbers in each group.
, we can consider each group separately and sum the distances between neighbouring numbers in each group.
Consider one group, corresponding to some remainder i modulo k, i.e. containing aj for 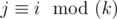 . Let's write down its numbers from left to right: b1, b2, ..., bm. Then this group adds to the overall sum the value
. Let's write down its numbers from left to right: b1, b2, ..., bm. Then this group adds to the overall sum the value
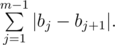
We can notice that if we sort b1, ..., bm in non-decreasing order, this sum will not increase. So, in the optimal answer we can consider that numbers in each group don't decrease. Furthermore, in that case this sum is equal to |bm - b1|.
Now consider two groups b1, ..., bm and c1, c2, ..., cl, both sorted in non-decreasing order. We claim that either b1 ≥ cl or bm ≤ c1, i.e. segments [b1, bm] and [c1, cl] can have common points only in their endpoints.
Why is this true? These groups add |bm - b1| + |cl - c1| to the overall sum. We consider the case c1 ≥ b1, the other is symmetric. If c1 < bm, then swapping c1 and bm will not increase the values these groups add to the answer, since the right border of b group moves to the left, and the left border of c group moves to the right. So, c1 ≥ bm in that case, and the assertion is proved.
Now we know that the values in each group should from a continuous segment of the sorted original array. In fact, we have 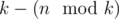 groups of size
groups of size 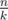 (so called small groups) and
(so called small groups) and 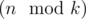 groups of size
groups of size 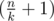 (so called large groups). Consider the following dynamic programming: dp[L][S] — the minimal sum of values added to the answer by L large groups and S small groups, if we choose the elements for them from the first
(so called large groups). Consider the following dynamic programming: dp[L][S] — the minimal sum of values added to the answer by L large groups and S small groups, if we choose the elements for them from the first 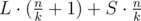 elements of the sorted array A. There are no more than O(k2) states, and each transition can be made in O(1): we choose large or small group to add and obtain the number it adds to the sum by subtracting two elements of the sorted array. The answer for the problem will be in
elements of the sorted array A. There are no more than O(k2) states, and each transition can be made in O(1): we choose large or small group to add and obtain the number it adds to the sum by subtracting two elements of the sorted array. The answer for the problem will be in 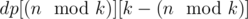 .
.
The overall complexity of the solution is 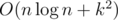 . We can note that in pretests was quite small, and some slower solutions could pass, but they failed on final tests.
. We can note that in pretests was quite small, and some slower solutions could pass, but they failed on final tests.
Problem author: zeliboba.
Problem developers: Kostroma, riadwaw.
Solution code: 12873418.
571C - КНФ-2
Firstly let's assign values to variables occurring in our fomula only with negation or only without negation. After that we can throw away the disjuncts which contained them, since they are already true, and continue the process until it is possible. To make it run in time limit, one should use dfs or bfs algorithm to eliminate these variables and disjuncts.
So now we have only variables which have both types of occurrences in disjucnts. Let's build a graph with the vertices corresponding to disjuncts, and for each varible a make an edge between the disjuncts that contain a and !a. Now we should choose the directions of edges in this graph in such a way that every vertex has at least one incoming edge.
We can notice that if some connected component of this graph is a tree, the solution is not possible: on each step we can take some leaf of this tree, and we have to orient its only edge to it, and then erase the leaf. In the end we'll have only one vertex, and it'll not have any incoming edges.
Otherwise, take some cycle in the component and orient the edges between neighbouring vertices along it. Then run dfs from every vertex of the cycle and orient each visited edge in the direction we went along it. It is easy to easy that after this process every vertex will have at least one incoming edge.
So, we should consider cases with the variables which values can be assigned at once, than construct a graph from disjuncts and variables and find whether each connected component has a cycle. If so, we also should carefully construct the answer, assigning the remaining variables their values, looking at the directions of the edges in the graph. The overall complexity is O(n + m).
Problem author: zeliboba.
Problem developers: Kostroma, zeliboba, yarrr.
Solution codes: 12873432 (linear solution), 12873446 (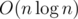 ), 12873456 (matching solution).
), 12873456 (matching solution).
571D - Кампус
Let's suppose for each dormitory from Q query we already know the last raid moment.
When task will be much easier: we can throw away M and Z queries and to get right answer we should subtract two values: people count in dormitory right now and same count in a last raid moment.
On this basis, we have such plan:
- For each Q query let's find the last raid moment using M and Z queries.
- Find people count in two interesting moments using U and A queries.
- Calculcates the final answer.
Let's try to solve the first part.
We want to make such queries on disjoint sets:
- Merge two sets (M query).
- Assign value time for all elements in particular set (Z query).
- Get value for a particular element (Q query).
To solve this task we'll use a well-known technique: "merge smaller set to bigger".
We'll maintain such values:
- elements — set elements.
- set_id — for each element their set id.
- last_set_update_time — last moment when assign operation has occurred for each set.
- last_update_time — last moment when assign operation has occurred for each element.
- actual_time — moment of time when last_update_time was actually for the element.
Let's focus on actual_time value.
It's obvious that when we merge two sets each element can have a different last assign moment. But after first assignment all elements from any set will have the same value. So the answer for Q query for element i from set s: If last_set_update_time[s]=actual_time[i] then last_update_time[i] else last_set_update_time[s]
For each Z query you should just update last_set_update_time array.
It's easy to maintain this values when you merge two sets:
Let's suppose we want to merge set from to set to. For each element from set from we already know last assign time. So just update last_update_time with this value and actual_time is equal of last assign operation for set to.
The second part of the solution is the same as first one.
O(n * lg(n) + m) time and O(n + m) memory.
Problem author: ArtDitel.
Problem developers: yarrr, gchebanov, Kostroma.
Solution codes: 12873477 (solution, described in the editorail), 12873469 (solution with treaps).
571E - Геометрические прогрессии
If intersection of two geometric progressions is not empty, set of common elements indexes forms arithmetic progression in each progression or consists of not more than one element. Let's intersect first progression with each other progression. If any of these intersections are empty then total intersection is empty. If some of these intersection consist of one element, then we could check only this element. Otherwise one could intersect arithmetic progressions of first progression indexes and take minimal element of this intersection. The remaining question is how intersect two geometric progression? Let's factorise all numbers in these two progressions and find set of appropriate indexes for every prime factor in both progressions. These progressions one need intersect both by values and by indexes.
Problem author: zeliboba.
Problem developers: zeliboba, yarrr, gchebanov.
Solution code: 12873480.









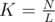 .
.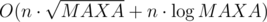 time.
time. . Base for
. Base for 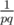 , that is
, that is  , that's we wanted to prove.
, that's we wanted to prove.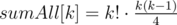 . The prove is simple: let's change in permutation
. The prove is simple: let's change in permutation 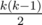 , and our conversion of the permutation is a biection.
, and our conversion of the permutation is a biection.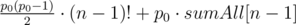 inversions.
inversions.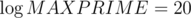 intervals, because for each
intervals, because for each 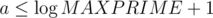 . Practically there is no more than
. Practically there is no more than 

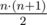 , which doesn't fit in
, which doesn't fit in 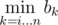 . All that minimums can be found in a single pass through
. All that minimums can be found in a single pass through 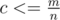 . We call the set of the vertices who are connected with
. We call the set of the vertices who are connected with 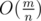 vertices and
vertices and