Hi again!
If you notice typos or errors, please send a private message.
Solution
Let's find out for each row of the given matrix if it is completely consisting of ones or not. Make another array canWin, and set canWini equal to one if the i-th row consists at least one zero. Then the problem is to find the maximum subsegment of canWin array, consisting only ones. It can be solved by finding for each element of canWin, the closest zero to it from left. The complexity of this solution is O(nd), but the limits allow you to solve the problem in O(nd2) by iterating over all possible subsegments and check if each one of them is full of ones or not.
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const int N = 202;
int a[N][N];
int main()
{
int n = in(), d = in();
int ans = 0, cur = 0;
for(int i = 0; i < d; i++)
{
string s;
cin >> s;
bool iff = 0;
for(int j = 0; j < n; j++)
iff |= (s[j] == '0');
if(iff)
cur++;
else
cur = 0;
ans = max(ans, cur);
}
cout << ans << endl;
}
Python coden, d = map(int, raw_input().split())
cur = 0
ans = 0
for i in range(d):
s = raw_input()
if (s == '1' * n):
cur = 0
else:
cur += 1
ans = max(ans, cur)
print ans
Hint
Try to characterize even-length palindrome numbers.
Solution
For simplifications, in the following solution we define lovely integer as an even-length positive palindrome number.
An even-length positive integer is lovely if and only if the first half of its digits is equal to the reverse of the second half.
So if a and b are two different 2k-digit lovely numbers, then the first k digits of a and b differ in at least one position.
So a is smaller than b if and only if the first half of a is smaller than the the first half of b.
Another useful fact: The first half of a a lovely number can be any arbitrary positive integer.
Using the above facts, it's easy to find the first half of the n-th lovely number — it exactly equals to integer n. When we know the first half of a lovely number, we can concatenate it with its reverse to restore the lovely integer. To sum up, the answer can be made by concatenating n and it's reverse together.
The complexity of this solution is  .
.
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const long long N = 2002;
int main()
{
string s;
cin >> s;
cout << s;
reverse(s.begin(), s.end());
cout << s << endl;
}
Python codes = raw_input()
print s + ''.join(reversed(s))
Challenge
What if you were asked to find n-th positive palindrome number? (1 ≤ n ≤ 1018)
Hint
Try to use all of the vertices. Then look at the two vertex covers together in the graph and see how it looks like.
Solution
Looking at the two vertex covers in the graph, you see there must be no edge uv that u and v are in the same vertex cover. So the two vertex covers form a bipartition of the graph, so the graph have to be bipartite. And being bipartite is also sufficient, you can use each part as a vertex cover. Bipartition can be found using your favorite graph traversing algorithm(BFS or DFS). Here is a tutorial for bipartition of undirected graphs.
The complexity is O(n + m).
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const int N = 120021;
vector <int> vc[2];
vector <int> g[N];
int mark[N];
bool dfs(int v, int color = 2)
{
mark[v] = color;
vc[color - 1].push_back(v);
for(int u : g[v])
{
if(!mark[u] && dfs(u, 3 - color))
return 1;
if(mark[u] != 3 - color)
return 1;
}
return 0;
}
int main()
{
int n, m;
cin >> n >> m;
for(int i = 0; i < m; i++)
{
int u = in() - 1;
int v = in() - 1;
g[u].push_back(v);
g[v].push_back(u);
}
for(int i = 0; i < n; i++)
if(!mark[i])
{
if(g[i].empty())
continue;
if(dfs(i))
{
cout << -1 << endl;
return 0;
}
}
for(int i = 0; i < 2; i++)
{
cout << vc[i].size() << endl;
for(int v : vc[i])
cout << v + 1 << " ";
cout << endl;
}
}
Challenge
In the same constraints, what if you were asked to give two disjoint edge covers from the given graph? (The edge covers must be edges-disjoint but they can have common vertex.)
Hint
Assume the answer of a test is No. There must exist a pair of integers x1 and x2 such that both of them have the same remainders after dividing by any ci, but they differ in remainders after dividing by k. Find more facts about x1 and x2!
Solution
Consider the x1 and x2 from the hint part. We have x1 - x2 ≡ 0 (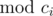 ) for each 1 ≤ i ≤ n.
) for each 1 ≤ i ≤ n.
So:
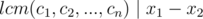
We also have 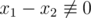 (
(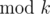 ). As a result:
). As a result:
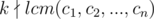
We've found a necessary condition. And I have to tell you it's also sufficient!
Assume , we are going to prove there exists x1, x2 such that x1 - x2 ≡ 0 () (for each 1 ≤ i ≤ n), and ().
A possible solution is x1 = lcm(c1, c2, ..., cn) and x2 = 2 × lcm(c1, c2, ..., cn), so the sufficiency is also proved.
So you have to check if lcm(c1, c2, ..., cn) is divisible by k, which could be done using prime factorization of k and ci values.
For each integer x smaller than MAXC, find it's greatest prime divisor gpdx using sieve of Eratosthenes in 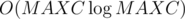 .
.
Then using gpd array, you can write the value of each coin as p1q1p2q2...pmqm where pi is a prime integer and 1 ≤ qi holds. This could be done in 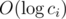 by moving from ci to
by moving from ci to 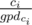 and adding gpdci to the answer. And you can factorize k by the same way. Now for every prime p that
and adding gpdci to the answer. And you can factorize k by the same way. Now for every prime p that 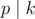 , see if there exists any coin i that the power of p in the factorization of ci is not smaller than the power of p in the factorization of k.
, see if there exists any coin i that the power of p in the factorization of ci is not smaller than the power of p in the factorization of k.
Complexity is 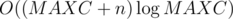 .
.
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const long long N = 1200021;
int cntP[N], isP[N];
int main()
{
for(int i = 2; i < N; i++)
if(!isP[i])
for(int j = i; j < N; j += i)
isP[j] = i;
int n = in(), k = in();
for(int i = 0; i < n; i++)
{
int x = in();
while(x > 1)
{
int p = isP[x];
int cnt = 0;
while(x % p == 0)
{
cnt++;
x /= p;
}
cntP[p] = max(cntP[p], cnt);
}
}
bool ok = 1;
while(k > 1)
{
ok &= (cntP[isP[k]] > 0);
cntP[isP[k]]--;
k /= isP[k];
}
cout << (ok ? "Yes\n" : "No\n");
}
And a nice implementation by Reyna: 18789803
Hint
Use dynamic programming.
Solution
Let dpi, j, k be true if and only if there exists a subset of the first i coins with sum j, that has a subset with sum k. There are 3 cases to handle:
- The i-th coin is not used in the subsets.
- The i-th coin is used in the subset to make j, but it's not used in the subset of this subset.
- The i-th coin is used in both subsets.
So dpi, j, k is equal to dpi - 1, j, k OR dpi - 1, j - ci, k OR dpi - 1, j - ci, k - ci.
The complexity is O(nk2).
C++ code // - -- --- ---- -----be name khoda----- ---- --- -- - \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const int N = 505;
bool dp[2][N][N];
int main()
{
int n, k;
cin >> n >> k;
dp[0][0][0] = 1;
for(int i = 1; i <= n; i++)
{
int now = i % 2;
int last = 1 - now;
int x = in();
for(int j = 0; j <= k; j++)
for(int y = 0; y <= j; y++)
{
dp[now][j][y] = dp[last][j][y];
if(j >= x)
{
dp[now][j][y] |= dp[last][j - x][y];
if(y >= x)
dp[now][j][y] |= dp[last][j - x][y - x];
}
}
}
vector <int> res;
for(int i = 0; i <= k; i++)
if(dp[n % 2][k][i])
res.push_back(i);
cout << res.size() << endl;
for(int x : res)
cout << x << " ";
cout << endl;
}
Challenge
In the same constraints, output the numbers you can never not make! Formally, the values x such that for every subset of coins with the sum k, there exists a subset of this subset with the sum x.
Unfortunately, our mistake in setting the constrains for this problem made it possible to get Ac with O(qm) solution. We hope you accept our apology.
Hint
Consider the following algorithm to answer a single query: Sort the edges and add them one by one to the graph in decreasing order of their weights. The answer is weight of the first edge, which makes an odd cycle in the graph. Now show that there are only O(n) effective edges, which removing them may change the answer of the query. Use this idea to optimize your solution.
Solution
First, let’s solve a single query separately. Sort edges from interval [l, r] in decreasing order of weights. Using dsu, we can find longest prefix of these edges, which doesn’t contains odd cycle. (Graph will be bipartite after adding these edges.) The answer will be weight of the next edge. (We call this edge “bottleneck”).
Why it's correct? Because if the answer is w, then the we can divide the graph in a way that none of the edges in the same part have value greater than w. So the graph induced by the edges with value greater than w must be bipartite. And if this graph is bipartite, then we can divide the graph into two parts as the bipartition, so no edge with value greater than w will be in the same part, and the answer is at most w.
Let's have a look at this algorithm in more details. For each vertex, we keep two values in dsu: Its parent and if its part differs from its parent or not. We keep the second value equal to "parity of length of the path in original graph, between this node and its parent". We can divide the graph anytime into two parts, walking from one vertex to its parent and after reaching the root, see if the starting vertex must be in the same part as the root or not.
In every connected component, there must not exist any edge with endpoints in the same part.
After sorting the edges, there are 3 possible situations for an edge when we are adding it to the graph:
The endpoints of this edge are between two different components of the current graph. Now we must merge these two components, and update the part of the root of one of the components.
The endpoints of this edge are in the same component of the current graph, and they are in different parts of this component. There is nothing to do.
The endpoints of this edge are in the same component of the current graph, and they are also in the same part of this component. This edge is the "bottleneck" and we can't keep our graph bipartite after adding it, so we terminate the algorithm.
We call the edges of the first and the third type "valuable edges".
The key observation is: If we run above algorithm on the valuable edges, the answer remains the same.
Proof idea: The edges of the first type are spanning trees of connected components of the graph, and with a spanning tree of a bipartite graph, we can uniquely determine if two vertices are in the same part or not.
So if we can ignore all other edges and run our algorithm on these valuable edges, we have O(n) edges instead of original O(n2) and the answer is the same.
We answer the queries using a segment tree on the edges. In each node of this tree, we run the above algorithm and memorize the valuable edges. By implementing carefully (described here), making the segment tree could be done in 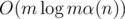 .
.
Now for each query [l, r], you can decompose [l, r] into segments in segment tree and each one has O(n) valuable edges. Running the naive algorithm on these edges lead to an  solution for each query, which fits in time limit.
solution for each query, which fits in time limit.
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const int N = 2002, M = (1 << 20), Q = 1001, S = 2 * M;
#define rank PAP
struct Edge
{
int u, v, w;
Edge(int u = 0, int v = 0, int w = 0):v(v), u(u), w(w) { }
bool operator <(const Edge &e) const { return w < e.w; }
};
struct Segment
{
int l, r;
Segment(int l = 0, int r = 0): l(l), r(r) { }
};
typedef vector <Edge> Edges;
int n, m, q;
Edge es[M];
Edges seg[S];
Segment range[S];
int par[N], cost[N], rank[N];
Segment merge(Segment l, Segment r) { return Segment(l.l, r.r); }
void clear(Edges &es)
{
for(Edge e : es)
{
par[e.v] = par[e.u] = -1;
cost[e.v] = cost[e.u] = 0;
rank[e.v] = rank[e.u] = 1;
}
}
int root(int v)
{
if(par[v] == -1)
return v;
int u = root(par[v]);
cost[v] ^= cost[par[v]];
return par[v] = u;
}
int parity(int v)
{
root(v);
return cost[v];
}
int merge(Edge e)
{
if(rank[root(e.u)] > rank[root(e.v)])
swap(e.u, e.v);
if(root(e.u) == root(e.v))
{
if(parity(e.u) == parity(e.v))
return 2;
return 0;
}
int u = root(e.u);
int v = root(e.v);
cost[u] ^= (parity(e.u) ^ 1 ^ parity(e.v));
par[u] = root(v);
rank[v] += rank[u];
return 1;
}
bool hasOddCycle;
Edges merge(Edges &a, Edges &b)
{
Edges c;
merge(a.begin(), a.end(), b.begin(), b.end(), back_inserter(c));
clear(c);
Edges res;
for(int i = c.size() - 1; i >= 0; i--)
{
int x = merge(c[i]);
if(x)
res.push_back(c[i]);
if(x == 2)
{
hasOddCycle = 1;
break;
}
}
reverse(res.begin(), res.end());
return res;
}
void make()
{
for(int i = S - 1; i; i--)
{
if(i >= M)
{
range[i] = Segment(i - M, i - M + 1);
if(i - M < m)
seg[i].push_back(es[i - M]);
}
else
{
range[i] = merge(range[i * 2], range[i * 2 + 1]);
seg[i] = merge(seg[i * 2], seg[i * 2 + 1]);
}
}
}
int solve(Segment s)
{
Edges es;
hasOddCycle = 0;
for(int l = s.l + M, r = s.r + M; l < r; l /= 2, r /= 2)
{
if(l % 2)
es = merge(es, seg[l++]);
if(r % 2)
es = merge(es, seg[--r]);
}
if(hasOddCycle)
return es[0].w;
return -1;
}
int main()
{
cin >> n >> m >> q;
for(int i = 0; i < m; i++)
{
es[i].u = in() - 1;
es[i].v = in() - 1;
es[i].w = in();
}
make();
while(q--)
{
int l = in() - 1, r = in();
cout << solve(Segment(l, r)) << "\n";
}
}
Hint: What the actual problem is
Looking at the code in the statement, you can see only the first edge in neighbors of each node is important. So for each vertex with at least one outgoing edge, you have to choose one edge and ignore the others. After this the graph becomes in the shape of some cycles with possible branches, and some paths. The number of dfs calls equals to 998 × ( sum of sizes of cycles ) + n + number of cycles.
Solution
The goal is to minimize the sum of cycle sizes. Or, to maximize the number of vertices which are not in any cycle. Name them good vertices.
If there exists a vertex v without any outgoing edge, we can make all of the vertices that v is reachable from them good. Consider the dfs-tree from v in the reverse graph. You can choose the edge 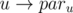 from this tree as the first edge in
from this tree as the first edge in neighbors[u], in order to make all of these vertices good.
Vertices which are not in the sink strongly connected components could become good too, by choosing the edges from a path starting from them and ending in a sink strongly connected component.
In a sink strongly connected component, there exists a path from every vertex to others. So we can make every vertex good except a single cycle, by choosing the edges in the paths from other nodes to this cycle and the cycle edges.
So, every vertices could become good except a single cycle in every sink strongly connected component. And the length of those cycles must be minimized, so we can choose the smallest cycle in every sink strongly connected component and make every other vertices good. Finding the smallest cycle in a graph with n-vertex and m edges could be done in O(n(n + m)) with running a BFS from every vertex, so finding the smallest cycle in every sink strongly connected component is O(n(n + m)) overall.
C++ code // . .. ... .... ..... be name khoda ..... .... ... .. . \\
#include <bits/stdc++.h>
using namespace std;
inline int in() { int x; scanf("%d", &x); return x; }
const int N = 5005;
int comp[N], bfsDist[N], bfsPar[N];
vector <int> g[N], gR[N];
bool mark[N], inCycle[N];
bool dfs(int v, vector <int> *g, vector <int> &nodes)
{
mark[v] = 1;
for(int u : g[v])
if(!mark[u])
dfs(u, g, nodes);
nodes.push_back(v);
}
int findSmallestCycle(vector <int> vs)
{
vector <int> cycle;
for(int root : vs)
{
for(int v : vs)
{
bfsDist[v] = 1e9;
bfsPar[v] = -1;
}
bfsDist[root] = 0;
queue <int> q;
q.push(root);
bool cycleFound = 0;
while(q.size() && !cycleFound)
{
int v = q.front();
q.pop();
for(int u : g[v])
{
if(u == root)
{
cycleFound = 1;
int curLen = bfsDist[v];
if(cycle.empty() || curLen < cycle.size())
{
cycle.clear();
for(; v != -1; v = bfsPar[v])
cycle.push_back(v);
}
break;
}
if(bfsDist[u] > bfsDist[v] + 1)
{
bfsDist[u] = bfsDist[v] + 1;
bfsPar[u] = v;
q.push(u);
}
}
}
}
return cycle.size();
}
int main()
{
int n, m;
cin >> n >> m;
for(int i = 0; i < m; i++)
{
int u = in() - 1;
int v = in() - 1;
g[u].push_back(v);
gR[v].push_back(u);
}
vector <int> order;
for(int i = 0; i < n; i++)
if(!mark[i])
dfs(i, g, order);
fill(mark, mark + n, 0);
fill(comp, comp + n, -1);
int inCycle = 0, nCycle = 0;
for(; order.size(); order.pop_back())
{
int v = order.back();
if(mark[v])
continue;
vector <int> curComp;
dfs(v, gR, curComp);
bool isSink = true;
for(int u : curComp)
comp[u] = v;
for(int u : curComp)
for(int k = 0; k < g[u].size(); k++)
if(comp[g[u][k]] != v)
isSink = false;
if(isSink)
{
int x = findSmallestCycle(curComp);
if(x > 0)
{
nCycle++;
inCycle += x;
}
}
}
cout << 999 * inCycle + (n - inCycle) + nCycle << endl;
}
Challenge
What if the target function is reversed? It means you have to choose a single outgoing edge from every node with at least one outgoing edge, and maximize the sum of cycle sizes in the chosen graph.
I thought about this one a lot but can't find any solution. Do you have any idea?











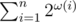 is
is 
 :(
:(