


Throughout the last several weeks I have tried to invent and solve, a generalization of segment trees (although now it doesn't fit to name it "segment trees"... see for yourself). The results are very few (and not good, if you ask me), but the problem was very appealing and fun to think about.
The purpose of this blogpost is to share my experience with this problem, in order to provide curiousity to at least a few people, and also to let bright-minded users tackle this problem together, and hopefully achieve better results. Since I want to share my experience, I will also put some possibly challenging parts under spoilers, if you want to attempt it yourself.
So, there is no tl;dr. Sorry :)
The Motivation and The Problem
As the title suggests, the motivation was from inspection of segment trees. Define the following problem, which we will try to solve throughout this post:
Given $$$n$$$ elements $$$a_0, \ldots, a_{n-1}$$$, initially $$$0$$$, and $$$m$$$ subsets $$$S_i \subseteq [n]$$$ (where $$$[n] = \lbrace 0, \ldots, n-1 \rbrace$$$), we need to support the following:
- Update $$$(i, x)$$$: add $$$x$$$ to $$$a_i$$$.
- Query $$$v$$$: return $$$\sum_{i \in S_v} a_i$$$.
Segment trees define the $$$m = \binom{n+1}{2}$$$ subsets implicitly — as ranges. For some "magical" reason, when we have ranges, we can define $$$n' = O(n)$$$ elements, and subsets $$$S_i, T_i \subseteq [n']$$$, such that an update $$$(v, x)$$$ requires adding $$$x$$$ to all $$$a_j, j \in S_v$$$, and a query $$$v$$$ is equal to $$$\sum_{j \in T_v} a_j$$$ — but with the bonus that $$$|S_i|, |T_i|$$$ are all $$$O(\log n)$$$, so all operations can be done in $$$O(\log n)$$$.
The construction is just setting $$$n'$$$ as the number of nodes in the segment tree, setting $$$S_i$$$ for every element as the set of $$$O(\log n)$$$ ranges that include it, and setting $$$T_i$$$ for every range as the set of ranges that cover it.
I wanted to figure out whether there is a generalization that allows such optimizations for problems where we don't have ranges. Analysis of cases where the subsets are too many and implicit, was too difficult to me. So the problem is as above, where the subsets $$$S_i$$$ are all given explicitly, and then queries and updates are made. So the input size is $$$O(n + \sum |S_i|)$$$.
Note: Segment trees also support different associative operations, such as minimum instead of sum. It was convenient to think about sums, and a lot of the following can be generalized to other operations, with perhaps an additional log factor. We can also generalize to "laziness", as subset updates and subset queries, but this generalization is much slower (perhaps it would be interesting to attempt this as well?). Anyway, both of these are left as an exercise to the reader.
Interpreting as a Graph
We can define a similar problem, and see that it's equivalent (up to a constant): Given an undirected graph, each node has a value $$$a_i$$$, initially $$$0$$$. An update requires us to add to a node's value, and a query $$$v$$$ asks for the sum of values of all neighbors of $$$v$$$.
The reduction from this problem to the aforementioned problem is simple — just define every subset as the set of neighbors of a node. In the opposite direction, given subsets we can define a bipartite graph of size $$$n + m$$$, where each of the $$$m$$$ vertices on one side, has neighbors on the other side corresponding to each of the $$$m$$$ subsets.
I found that, by interpreting the problem as a graph, I was able to make progress.
Solving for a tree
Suppose the graph is a tree. Can we solve this problem efficiently? You can attempt this yourself before reading.
That was awesome, let's try a general graph
Let's analyze what happened here
The tree solution is significantly better than the general graph solution. Applying the general solution to a tree gives us $$$O(\sqrt{V})$$$ instead of $$$O(1)$$$. So what was this magic in trees that allowed us to cheat like this?
The magic boils down to relating vertices and their parents. Let's generalize this to any graph:
We direct every edge in our graph in some direction. Define for every vertex, the vertices to which it has an outgoing edge, as $$$T_v$$$. Think of it as $$$v$$$'s "parents". The sum of neighbors of a vertex can be split to the sum of outgoing neighbors, and the sum of incoming neighbors. Now, the tree solution is generalizable:
Maintain $$$a_v$$$ for every vertex as usual, and maintain $$$b_v$$$ for every vertex, as the sum of its incoming neighbors. Then on an update $$$(v, x)$$$ we add $$$x$$$ to $$$a_v$$$, and to $$$b_u$$$ for all $$$u \in T_v$$$. On a query $$$v$$$, we compute $$$b_v$$$ + $$$\sum_{u\in T_v} a_u$$$.
The time complexity becomes $$$O(\max |T_i|)$$$. While this result doesn't improve our situation in dense graphs, it can be useful in different ones — for example, trees.
Minimizing $$$\max |T_i|$$$
Given a graph, let's say we want to find the minimum value of $$$\max |T_i|$$$ among all possible ways to direct the edges. Turns out that it is computable in polynomial time!
Another interesting fact is that there is a relatively simple formula that expresses the minimum achievable $$$\max |T_i|$$$:
To finish with what I covered into this area — the main issue is that, in the case where we first compute this directioning, and then start the queries and updates, this algorithm might be too slow. So, here is a linear time algorithm that directs all of the edges s.t the maximum outgoing degree is at most $$$2d(G)$$$ — asymptotically optimal.
Before I found this algorithm, I had a different one, with a complex proof that it also gets a constant factor approximation. The algorithm consists of an arbitrary initial direction to every edge. Then observe that we can flip an edge and update our data in $$$O(1)$$$. For every vertex we get a query/update on, flip all of its outgoing edges and then operate on it. You can attempt to prove its amortized complexity if you want.
Random Dense Graphs
I'll have to address the issue that we still don't have anything good for dense graphs. Of course, for large $$$n$$$, we're probably not going to get explicitly a dense graph, but still it would be interesting to analyze this.
Let's backtrack to the initial problem (not the graph formulation) — up until now, we were given $$$n$$$ elements and our $$$m$$$ "query subsets" as input, while all of our strategies consist of choosing a new $$$N$$$ (for instance, in a tree we had $$$N = 2n$$$ since we also initialized another array $$$b$$$), constructing $$$n$$$ "update subsets" and $$$m$$$ "query subsets", so that every update requires adding in a subset and every query requires computing the sum over a subset.
Let's prove a depressing $$$\Omega \left( \frac{n}{\log n} \right)$$$ lowerbound for this approach.
Furthermore, I believe that any algorithm can be transformed via linear algebra to an algorithm that constructs update subsets and query subsets, but I was unable to prove it.
Anyway, there is also an $$$O\left( \frac{n}{\log n} \right)$$$ construction, so we hit our limit it seems. This follows the pattern that many algorithms use to remove a log factor off complexity, like RMQ.
As a final note, this means that I also don't know how to do $$$o \left( \frac{d(G)}{\log n} \right)$$$ for any graph $$$G$$$ (following the definition of $$$d(G)$$$ from before). Can we use this trick to reduce the time complexity below $$$d(G)$$$? (when it is bigger than $$$\log n$$$).
Implicit Subsets
Since I did feel like I covered enough ground on explicit inputs, it might be time to select some interesting implicit cases. I didn't spend a lot of time on this, so I don't have any results.
For implicit subsets as ranges, segment trees work :). Here's an interesting implicit case that I have no clue how to solve: We are given the subsets in the input, except that every given subset is either a pair of indicies, or a union of two previously given subsets. Maybe we can provide solutions based on small "depth" of subsets?
An interesting application of this would be reachability queries in a DAG.
Applications
All my work was purely theoretical, but since some people enjoy a new topic only if it leaves the "sweet flavor of applications", I guess I have to make up some.
You begin with $$$n,k$$$ and an empty set. In an update you insert or erase an element in $$$[0, 2^n)$$$ from your set, and in a query you are asked for the minimum bitwise OR that can be made by choosing $$$k$$$ elements from the current set. If we construct $$$2^n$$$ elements, and $$$2^n$$$ subsets such that $$$S_i$$$ contains all $$$j$$$ whose bits are included in $$$i$$$'s bits, then we have $$$3^n$$$ edges in this graph. The average degree of the graph is $$$1.5^n$$$, and I believe that $$$d(G)$$$ is also $$$O(1.5^n)$$$, so this problem is solvable in $$$O(1.5^n \cdot n)$$$ per query, instead of $$$O(2^n \cdot n)$$$.
Given $$$n$$$, we can construct a bipartite graph with $$$n$$$ vertices on each side, and connect $$$(i, j)$$$ if $$$i$$$ divides $$$j$$$. Then using this graph we can solve a problem of inserting/removing a value $$$x \in [1, n]$$$ from a set and querying for the number of values that divide $$$x$$$ / are multiples of $$$x$$$. $$$d(G)$$$ of this graph I think has to do with highly composite numbers — choose some number $$$k$$$, on one side take all divisors of $$$k$$$ and on the other take all multiples of $$$k$$$. The density of this subgraph is $$$\frac{n\cdot \sigma_0(k)}{n + k\sigma_0(k)}$$$, where $$$\sigma_0$$$ is the divisor counting function. Choosing some highly composite $$$k$$$ such that $$$k \cdot \sigma_0(k)$$$ is about $$$n$$$, feels like it hits the upperbound, and I think it leads to quite a small density. If I recall correctly, running the greedy approximation algorithm on $$$n = 200000$$$ gave around $$$50$$$ maximum outdegree, which is not bad.
You can probably find applications that are more interesting, but I don't find it important right now. I think we should try to:
- Disprove my proof of optimality on dense graphs.
- Prove or disprove that any algorithm can be transformed into one where we construct update subsets and query subsets.
- Try to make up implicit inputs and solve them — this might be the most interesting road to obtain new results.





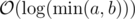 .
.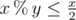 . This is due to:
. This is due to: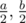 respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most
respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most 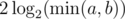 , which implies
, which implies 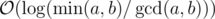
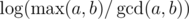 , and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum;
, and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum; 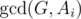 . The known time complexity analysis gives us the bound of
. The known time complexity analysis gives us the bound of 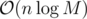 , for computing gcd
, for computing gcd 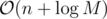 (for practical values of
(for practical values of  ). Why is that so? again, we can determine the time complexity more carefully:
). Why is that so? again, we can determine the time complexity more carefully: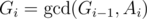
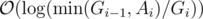 , which is worstcase
, which is worstcase 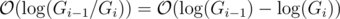 , so we will assume it's the latter.
, so we will assume it's the latter.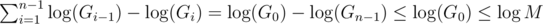
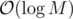 .
.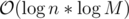 per query or update. We can use (1) to give
per query or update. We can use (1) to give 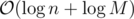 ; an update consists of a starting value, and repeatedly for
; an update consists of a starting value, and repeatedly for  steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
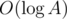 , where
, where 