


Probably some of you will be interested in this news: link to facebook post
[*]
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Probably some of you will be interested in this news: link to facebook post
[*]
Hello, codeforces!
It's time to continue the series of Polish tasks. I've decided to write about my own task one more time. Its name is "cook" (you can submit here). The task isn't very hard, but it uses cute (in my opinion) trick. The statement goes as follows:
There is a cook in a restaurant. He has n (1 ≤ n ≤ 106) orders which he must fill. Every order is a piece of paper, and all orders are speared on a spindle (sharp stick with pierced pieces of paper) in a fixed order which cannot be changed. Normal cook would just take orders one by one from the top of the spindle and fill them in this order, but the cook in this task has supernatural cooking powers and can combine orders to fill them faster. In particular, if at some moment there are k out of n orders still on the spindle, he can choose one of three options:
— He can take the topmost piece of paper and fill this order in time one(k).
— If k > 1, he can take two topmost pieces of paper and fill both orders in total time two(k).
— If k > 1, he can take 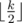 topmost pieces of paper and fill these orders in total time half(k).
topmost pieces of paper and fill these orders in total time half(k).
This task is interactive, so you should communicate with the library and ask it for values of one, two and half. You can ask as many times as you want and assume that the library works in negligible time, so your only limit is the time limit. Please, note, that when k = 2 functions one and half both fills only one order, but they might take different amounts of time. This same applies to other similar situations.
Also, the cook has an energy level, initially equal to e (0 ≤ e ≤ 106). He likes preparing food without any tricks, so whenever he uses the first option his energy increases by one. However, his half combo tires him very much, thus each time when he chooses the third option his energy decreases by one. Cook's energy cannot drop below zero at any time. Of course, we are asked about the minimum amount of time in which cook can finish all orders. Final energy level doesn't matter.
Last thing: memory limit is unusual because it's equal to 8MB.
Hello, codeforces!
This time I've decided to choose a task from my own contest which took place last April and was known as the Grand Prix of Poland. If you want to write this contest virtually in the future, then consider not reading this blog. If you've participated in this contest and maybe even solved this task, then anyway I recommend reading it, cause this task has many very different solutions, each of them being very interesting (in my opinion). It's also a reason why this blog is longer than previous ones.
I'll write about task C "cutting tree" (not uploaded to the ejudge yet :/). The statement goes as follows:
You are given a tree with n vertices (1 ≤ n ≤ 2·105). The task is to calculate f(k) for each integer k from the range [1, n] where f(k) is defined as the maximum number of connected components of size k which we can "cut off" from the tree. A connected component of size k is a set of k vertices such that it's possible to traverse in the tree between any pair of these vertices using only vertices from this set. Chosen components are not allowed to intersect, so each vertex must belong to at most one component.
Hello, codeforces!
All signs in the sky and on the ground indicate that you've enjoyed my first blog, so here is the second one. I've decided to choose a Polish task again, as there are plenty of interesting ones. This time we'll take a look at the "plot purchase" (you can submit here), which is a bit easier, but a few years ago I was very proud of myself when I solved it. The statement goes as follows:
You are given a square n × n grid (1 ≤ n ≤ 2000). In every cell, there is a number from the range [1, 2·109]. You are also given an integer k (1 ≤ k ≤ 109). A task is to find a subrectangle of this grid such that the sum of values in this subrectangle lies in the range [k, 2·k] (or report that there is no such subrectangle). Just print coordinates of its opposite corners.
Hello, codeforces!
The community wants so the community gets it! :D Here it is, my very first blog about tasks and algorithms. At the beginning I've decided to post my entries on codeforces, maybe I'll switch to something different if it becomes uncomfortable.
To pour the first blood I decided to choose a task from one of the old ONTAK camps. Task's name is "different words" (you can submit here). The statement goes as follows:
You are given n words (2 ≤ n ≤ 50 000), every of length exactly 5 characters. Each character can be a lowercase letter, an uppercase letter, a digit, a comma... basically, it can be any character with ASCII code between 48 and 122 (let's say that k is the number of possible characters). A task is to find all pairs of indexes of words which are 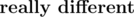 . Two words are if they differ at all 5 corresponding positions. So for example words
. Two words are if they differ at all 5 corresponding positions. So for example words  and
and  are really different and words
are really different and words 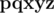 and
and 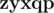 are not, because in both of them the third character is
are not, because in both of them the third character is 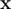 . As there can be many such pairs (up to
. As there can be many such pairs (up to 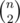 ), if there are more than 100 000 pairs, then the program should print that there are only 100 000 and print this number of pairs (arbitrary chosen).
), if there are more than 100 000 pairs, then the program should print that there are only 100 000 and print this number of pairs (arbitrary chosen).
Please, note that this task comes from the contest which took place a few years ago, so don't think about bitsets. :P
Hello codeforces! I want to share my idea with you.
I've noticed that I know some nice tricks and some tasks with very educative solutions, which might be interesting, surprising or useful in other tasks. Recently I am considering starting my own blog, where I'd share chosen tasks with you and write about possible ways to solve them. I wanted to ask the community about it, cause I don't want you to hate this idea and write comments like "boooo, we already have Petr's blog, you are just copying his idea, you just want contribution, you are next Swistakk, go away".
What do you think about this idea? I'd be able to change form of this blog as you wish and add additional sections. Should I write such blogs?
How to ask a question in the new GCJ system? Is is possible?
Hi!
Last times there was a post about quality of WF problemset. I also agree that they could be better, there were many other contests which consisted of definitely more interesting/better prepared problems. So here comes my question: what is your favorite ACM-style contest?
I'm asking mostly about quality of tasks, maybe there were very interesting? Or maybe something different caught your attention? Of course there is a lot of interesting tasks, but I'm definitely not asking about this kind of contests where there are 9 very easy tasks and then 2 very hard (but so nice) ones.
For example my favorite problemset was on CERC 2017, I think that there were many very interesting problems and they really needed no knowledge. I also liked problems from WF 2017.
Of course you don't have to choose some contest from the ICPC family. Maybe some snackdown contest was so cool for you? Or maybe you liked some contest from training camp in your high school? Write about it in comments.
Do you know any nice tasks which require randomization to decrease complexity which are not well known (like: you are given given set of points, find a line with at least n/2 points <- this one is well known)? Such like 364D - Ghd. Unfortunately codeforces has only tag "probabilities", which is usually used for problems where we have to calculate probability of something. Every time when I come across this kind of problem I am impressed how cool it is, so maybe you want to impress me? :D
Guys, did you notice that we have many more rounds nowadays? :D MikeMirzayanov and KAN must feel like this:


Hi guys!
On IOI I've learned many new things, so now I want to give you a challenge. You probably remember my and Errichto's eliminations to VK Cup 2016. Let's focus on this problem: 674C - Levels and Regions
Main solution was solving it in O(n*k), because k wasn't greater than 50. What if k is just lower or equal to n? :D
Unable to parse markup [type=CF_TEX]
Editorial was created by Errichto, but he said that he has enough contribution, so I'm posting it for you. ;)
(invented by GlebsHP — thanks!)
You are supposed to implement what is described in the statement. When you read numbers ti, check if two consecutive numbers differ by more than 15 (i.e. ti - ti - 1 > 15). If yes then you should print ti - 1 + 15. You can assume that t0 = 0 and then you don't have to care about some corner case at the beginning. Also, you can assume that tn + 1 = 91 or tn + 1 = 90 (both should work — do you see why?). If your program haven't found two consecutive numbers different by more than 15 then print 90. If you still have problems to solve this problem then check codes of other participants.
(invented by Errichto)
Some prefix of problems must belong to one division, and the remaining suffix must belong to the other division. Thus, we can say that we should choose the place (between two numbers) where we split problems. Each pair ai, bi (let's say that ai < bi) means that the splitting place must be between ai and bi. In other words, it must be on the right from ai and on the left from bi.
For each pair if ai > bi then we swap these two numbers. Now, the splitting place must be on the right from a1, a2, ..., am, so it must be on the right from A = max(a1, a2, ..., am). In linear time you can calculate A, and similarly calculate B = min(b1, ..., bm). Then, the answer is B - A. It may turn out that A > B though but we don't want to print a negative answer. So, we should print max(0, B - A).
(invented by Errichto)
We are going to iterate over all intervals. Let's first fix the left end of the interval and denote it by i. Now, we iterate over the right end j. When we go from j to j + 1 then we get one extra ball with color cj + 1. In one global array cnt[n] we can keep the number of occurrences of each color (we can clear the array for each new i). We should increase by one cnt[cj + 1] and then check whether cj + 1 becomes a new dominant color. But how to do it?
Additionally, let's keep one variable best with the current dominant color. When we go to j + 1 then we should whether cnt[cj + 1] > cnt[best] or (cnt[cj + 1] = = cnt[best] and cj + 1 < best). The second condition checks which color has smaller index (in case of a tie). And we must increase answer[best] by one then because we know that best is dominant for the current interval. At the end, print values answer[1], answer[2], ..., answer[n].
(invented by Errichto)
There is no solution if n = 4 or k ≤ n. But for n ≥ 5 and k ≥ n + 1 you can construct the following graph:
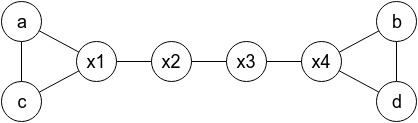
Here, cities (x1, x2, ..., xn - 4) denote other cities in any order you choose (cities different than a, b, c, d). You should print (a, c, x1, x2, ..., xn - 4, d, b) in the first line, and (c, a, x1, x2, ..., xn - 4, b, d) in the second line.
Two not very hard challenges for you. Are you able to prove that the answer doesn't exist for k = n? Can you solve the problem if the four given cities don't have to be distinct but it's guaranteed that a ≠ b and c ≠ d?
(invented by Radewoosh)
When we repeat something and each time we have probability p to succeed then the expected number or tries is  , till we succeed. How to calculate the expected time for one region [low, high]? For each i in some moment we will try to beat this level and then there will be S = tlow + tlow + 1 + ... + ti tokens in the bag, including ti tokens allowing us to beat this new level. The probability to succeed is
, till we succeed. How to calculate the expected time for one region [low, high]? For each i in some moment we will try to beat this level and then there will be S = tlow + tlow + 1 + ... + ti tokens in the bag, including ti tokens allowing us to beat this new level. The probability to succeed is 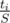 , so the expected time is
, so the expected time is 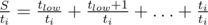 . So, in total we should sum up values
. So, in total we should sum up values 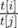 for i < j. Ok, we managed to understand the actual problem. You can now stop and try to find a slow solution in O(n2·k). Hint: use the dynamic programming.
for i < j. Ok, we managed to understand the actual problem. You can now stop and try to find a slow solution in O(n2·k). Hint: use the dynamic programming.
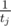 for all 1 ≤ j ≤ i.
for all 1 ≤ j ≤ i.Now let's write formula for dp[i][j], as the minimum over l denoting the end of the previous region:
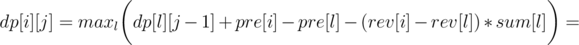
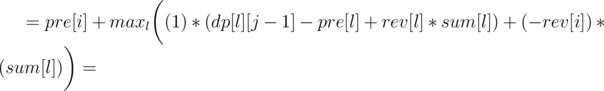
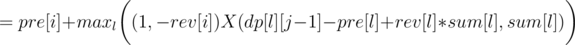
So we can use convex hull trick to calculate it in O(n·k). You should also get AC with a bit slower divide&conquer trick, if it's implemented carefully.
(invented by Radewoosh)
Let's say that every company has one parent (a company it follows). Also, every copmany has some (maybe empty) set of children. It's crucial that sets of children are disjoint.
For each company let's keep (and always update) one value, equal to the sum of:
It turns out that after each query only the above sum changes only for a few values. If a starts to follows b then you should care about a, b, par[a], par[b], par[par[a]]. And maybe par[par[b]] and par[par[par[a]]] if you want to be sure. You can stop reading now for a moment and analyze that indeed other companies will keep the same sum, described above.
Ok, but so far we don't count the income coming from parent's fanpage. But, for each company we can store all its children in one set. All children have the same "income from parent's fanpage" because they have the same parent. So, in set you can keep children sorted by the sum described above. Then, we should always puts the extreme elements from sets in one global set. In the global set you care about the total income, equal to the sum described above and this new "income from parent". Check codes for details. The complexity should be 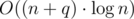 , with big constant factor.
, with big constant factor.
(invented by Errichto)
Let dp[v][h] denote the probability that subtree v (if attacked now) would have height at most h. The first observation is that we don't care about big h because it's very unlikely that a path with e.g. 100 edges will survive. Let's later talk about choosing h and now let's say that it's enough to consider h up to 60.
When we should answer a query for subtree v then we should sum up h·(dp[v][h] - dp[v][h - 1]) to get the answer. The other query is harder.
Let's say that a new vertex is attached to vertex v. Then, among dp[v][0], dp[v][1], dp[v][2], ... only dp[v][0] changes (other values stay the same). Also, one value dp[par[v]][1] changes, and so does dp[par[par[v]]][2] and so on. You should iterate over MAX_H vertices (each time going to parent) and update the corresponding value. TODO — puts here come formula for updating value.
The complexity is O(q·MAX_H). You may think that MAX_H = 30 is enough because 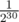 is small enough. Unfortunately, there exist malicious tests. Consider a tree with
is small enough. Unfortunately, there exist malicious tests. Consider a tree with 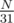 paths from root, each with length 31. Now, we talk about the probability of magnitude:
paths from root, each with length 31. Now, we talk about the probability of magnitude:
which is more than 10 - 6 for d = 30.
http://www.wolframalpha.com/input/?i=1+-+(1-(1%2F2)%5Ed)%5E(N%2Fd)+for+N+%3D+500000+and+d+%3D+30
(invented by Radewoosh)
Let's start with O(q·p2) approach, with the dynamic programming. Let dp[days][beds] denote the maximum number of barrels to win if there are days days left and beds places to sleep left. Then:
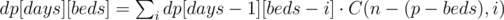
Here, i represents the number of bears who will go to sleep. If the same i bears drink from the same X barrels and this exact set of bears go to sleep then on the next day we only have X barrels to consider (wine is in one of them). And for X = dp[days - 1][beds - i] we will manage to find the wine then.
And how to compute the dp faster? Organizers have ugly solution with something similar to meet in the middle. We calculate dp for first q2 / 3 days and later we use multiply vectors by matrix, to get further answers faster. The complexity is equivalent to O(p·q) but only because roughly q = p3. We saw shortest codes though. How to do it guys?
You may wonder why there was 232 instead of 109 + 7. It was to fight with making the brute force faster. For 109 + 7 you could add sum + = dp[a][b]·dp[c][d] about 15 times (using unsigned long long's) and only then compute modulo. You would then get very fast solution.
(invented by qwerty787788)
Let's first consider a solution processing query in O(n) time, but using O(1) extra memory. If p = 51%, it's a well known problem. We should store one element and some balance. When processing next element, if it's equal to our, we increase balance. If it's not equal, and balance is positive, we decrease it. If it is zero, we getting new element as stored, and setting balance to 1.
To generalize to case of elements, which are at least 100/k%, we will do next. Let's store k elements with balance for each. When getting a new element, if it's in set of our 5, we will add 1 to it's balance. If we have less, than 5 elements, just add new element with balance 1. Else, if there is element with balance 0, replace it by new element with balance one. Else, subtract 1 from each balance. The meaning of such balance becomes more mysterious, but it's not hard to check, that value is at least 100/k% of all elements, it's balance will be positive.
To generalize even more, we can join two of such balanced set. To do that, we sum balances of elements of all sets, than join sets to one, and then removing elements with smallest balance one, by one, untill there is k elements in set. To remove element, we should subtract it's balance from all other balances.
And now, we can merge this sets on segment, using segment tree. This solution will have complexity like n * log(n) * MERGE, where MERGE is time of merging two structures. Probably, when k is 5, k2 / 2 is fastest way. But the profit is we don't need complex structures to check which elements are really in top, so solution works much faster.

Hello everybody!
I'm glad to announce that Round 1 of VK Cup 2016 will take place this Monday, and me (Radewoosh) and Kamil Dębowski (Errichto) are the problemsetters!
There will be an official round for teams from VK cup, but if you are not eligible to participate in it, then you can compete (alone, not in team) in one of two additional editions (one for div.1 and one for div.2), so everybody is invited to take part in the competition! Just register in your category here. All three rounds will be rated. Div.1 and Div.2 editions will look like normal CF round, but will have common problems with official edition.
If you can't register before the round, then you will be able to do it during the contest (but not for the entire duration, you can cheсk it here). Let's thank Mike for this great feature!
We want to thank GlebsHP for help in preparing the problems and MikeMirzayanov because without him we wouldn't have such a great platform as Codeforces, where we all can train and develop our passion.
You will again help Limak, your favorite bear. This time it may be harder, because evil Radewoosh will try to disturb him.
We wish you good luck and great fun! Can't wait to see you during the contest! :D
UPD Scoring will be:
For VK: 500 — 750 — 1000 — 1500 — 2000 — 3000
For Div.2: 500 — 1000 — 1500 — 2000 — 2500
For Div.1: 500 — 1000 — 1500 — 2000 — 3000
UPD Editorial is ready.
UPD Congratulations to the winners!
In official VK:
1.Never Lucky: subscriber and tourist
2.SobolevTeam: Seyaua and sdya
3.LNU Penguins: witua and RomaWhite
4.Dandelion: Um_nik and sivukhin
5.uıɟɟnɯ ɐuɐuɐq ǝɥʇ ɟo uɹnʇǝɹ╰(º o º╰): enot110 and romanandreev
In Div.1
1.dotorya
2.kcm1700
3.JoeyWheeler
4.KrK
5.Swistakk
And in Div.2
1.osmanorhan
2.nhho
3.fudail225
5.agaga
4.alanM
Also let's thank qwerty787788 and AlexFetisov for testing problems, without them it would be much harder to prepare contest, so give them an applause!
Guys, what memes about waiting for system tests do you have? :D
Can you post them in comments?


These are not mine. I've found them somewhere in blogs.
Guys, today is 256th day of the year and it's international programmer's day. I wish for everyone all the best, many AC and great rating. :D
We can easily calculate the sum of money that we need to buy all the bananas that we want, let's name it x.
If n > = x the answer is 0, because we don't need to borrow anything.
Otherwise the answer is x - n.
Let's count the number of badges with coolness factor 1, 2 and so on. Then, let's look at the number of badges with value equal to 1. If it's greater than 1, we have to increase a value of every of them except for one. Then, we look at number of badges with value 2, 3 and so on up to 2n - 2 (because maximum value of badge which we can achieve is 2n - 1). It is easy to see that this is the correct solution. We can implement it in O(n), but solutions that work in complexity O(n^2) also passed.
It's easy to count who wins and after how many "fights", but it's harder to say, that game won't end. How to do it?
Firstly let's count a number of different states that we can have in the game. Cards can be arranged in any one of n! ways. In every of this combination, we must separate first soldier's cards from the second one's. We can separate it in n + 1 places (because we can count the before and after deck case too).
So war has (n + 1)! states. If we'd do (n + 1)! "fights" and we have not finished the game yes, then we'll be sure that there is a state, that we passed at least twice. That means that we have a cycle, and game won't end.
After checking this game more accurately I can say that the longest path in the state-graph for n = 10 has length 106, so it is enough to do 106 fights, but solutions that did about 40 millions also passed.
Alternative solution is to map states that we already passed. If we know, that we longest time needed to return to state is about 100, then we know that this solution is correct and fast.
Firstly we have to note, that second soldier should choose only prime numbers. If he choose a composite number x that is equal to p * q, he can choose first p, then q and get better score. So our task is to find a number of prime factors in factorization of n.
Now we have to note that factorization of number a! / b! is this same as factorization of numbers (b + 1)*(b + 2)*...*(a - 1)*a.
Let's count number of prime factor in factorization of every number from 2 to 5000000.
First, we use Sieve of Eratosthenes to find a prime diviser of each of these numbers. Then we can calculate a number of prime factors in factorization of a using the formula:
primefactors[a] = primefactors[a / primediviser[a]] + 1
When we know all these numbers, we can use a prefix sums, and then answer for sum on interval.
There are few ways to solve this task, but I'll describe the simplest (in my opinion) one.
Let's build a flow network in following way:
Make a source.
Make a first group of vertices consisting of n vertices, each of them for one city.
Connect a source with ith vertex in first group with edge that has capacity ai.
Make a sink and second group of vertices in the same way, but use bi except for ai.
If there is a road between cities i and j or i = j. Make two edges, first should be connecting ith vertex from first group, and jth vertex from second group, and has infinity capacity. Second should be similar, but connect jth from first group and ith from second group.
Then find a maxflow, in any complexity.
If maxflow is equal to sum of ai and is equal to sum of bi, then there exists an answer. How can we get it? We just have to check how many units are we pushing through edge connecting two vertices from different groups.
I told about many solutions, because every solution, which doesn't use greedy strategy, can undo it's previous pushes, and does it in reasonable complexity should pass.
Hi everyone!
I am pleased to announce that Codeforces Round #304 (Div.2), of which I am the author, will take place today. This will be my first round, so I hope that it will be cool and interesting. Traditionally Div.1 participants can take part out of the competition.
I want to thank znirzej, Dakurels and Zlobober for help with preparing the problems, thank Delinur for translating the problems, and thank to MikeMirzayanov and all who created polygon for this great system.
I wish you all good luck!
UPD Scoring will be 500-1000-1250-1500-2250.
UPD editorial
UPD Congratulations for winners in div.2:
And in div.1:







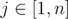 . Also, for fixed
. Also, for fixed