


I blacked out and completely forgot to set the timer for publishing a screencast, instead publishing it right away. I'm very sorry. My apologies to the authors and the whole community.
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions





Hi.
Shayan asked if he could interview me and I said "Why not?" The thing will happen in the near future on Shayan's YouTube channel Algorithms with Shayan.
Meanwhile, you can join his community in Discord and send questions to me on a special channel. Or you can ask the questions in the comments here.
I will not monitor the comments because I don't want to know the questions beforehand. Shayan will choose the most interesting questions to be featured in the interview!
Hello Codeforces! The 13th Stage of the 1st Universal Cup is coming. It will be held from April 22nd to 23rd.
This contest was first used in the Petrozavodsk Programming Camp Winter 2023, and also appeared in the 2023 ICPC Training Camp powered by Huawei and the Hello Muscat 2023 Bootcamp. If you participated in any of those, you should not participate in this stage of the Universal Cup.
All the problems were authored and prepared by 998kover, 244mhq, 353cerega (Harbour.Space P+P+P, Barcelona, Spain) and Um_nik (Lisbon, Portugal).
We want to thank the Universal Cup Committee for staying true to the spirit of 5h/3person/1pc contests and for providing the opportunity to share our contest with a wider audience.
As usual, we have three time windows for participating. You can participate in the contest in the following three time windows:
Time Window 1: April 22nd 13:00 — 18:00 (UTC +8)
Time Window 2: April 22nd 19:00 — 24:00 (UTC +8)
Time Window 3: April 23rd 02:00 — 07:00 (UTC +8)
Please note that you can see two scoreboards in DOMjudge. The 'Local Scoreboard' shows the standings ONLY IN THE CURRENT TIME WINDOW. And the 'Combined Scoreboard' shows all participants, including the onsite participants, and the cup participants in the previous time windows.
Contest link: https://domjudge.qoj.ac/
Universal Cup Scoreboard: https://qoj.ac/ucup/scoreboard
About Universal Cup:
Universal Cup is a non-profit organization dedicated to providing trainings for competitive programming teams. Up to now, there are more than 500 teams from all over the world registering for Universal Cup.
A more detailed introduction: https://codeforces.com/blog/entry/111672
Register a new team: https://ucup.ac/register (the registration request will be processed before each stage)
Results of the past stages: https://ucup.ac/results
Terms: https://ucup.ac/terms
Ratings: https://ucup.ac/rating

Just a reminder that Um still exists and I just posted Episode 9. And it is just 0:54 long, no reason not to watch. Magic words to attract attention: Um_nik does binary search, $$$O(\log N)$$$ per query online solution to Stamp Rally.
I switched to the "1 video every 2 days" schedule, it seems manageable.
The list now contains 15 problems. Also, there are slides for the problems for which videos are already posted.
Checklist by aryanc403 for tracking your progress on Um problems, Playlist with all Um episodes, My YouTube channel, Discord, Um_nik World.
More tips to use while studying under my tutoring here.
Stop caring about the rating
Unless there are prizes involved, your position in the standings makes no difference. I can feel awful after winning a contest if I know that I could solve one more problem. Or I can feel OK losing a bunch of rating points knowing that I solved everything I could. Because rating is just a number. It is highly volatile and it depends on other people, not only on your skill. But solving problems is totally up to you. And you should evaluate yourself not based on some random metric, but on your honest feeling whether you performed up to your expectations. Your sense of self should be under your control, don't get hung up on some imaginary value, you cannot reduce your progress to a single number.
Don't use more than one account
Rating is just a number. Do not be afraid to lose your colour. You’ll get it back in no time if you continue to improve.
You don’t need a second account for shitposting either. If you think something you are doing is shit and you don't want it associated with your main account you shouldn't do it at all. Either be proud of your trolling (and do it from your main account) or don't do it.
Write contests (duh)
You may think that you are not ready to write some contests, that you need more practice solving problems without time restrictions. And yeah, practice is a necessary part of progress, but you will never learn how to function under pressure without writing contests. The best way to learn how to do X is to try to do X.
Delete rating predictor
What is even the point of it? Does it help you make a decision of what to do? What problem to solve? What problem to hack? No. It may give you motivation, but it may also break your motivation by giving you a false sense of security.
And besides, rating is just a number. Your sole goal during the contest should be to solve as much as you can. As fast as you can, as optimal as you can, and hacking on the side comes later. Focus on solving. Focus on the next problem. That is it. Round is just a series of intervals where you focus on the new problem.
Rating is way too random to be tied to your sense of achievement. Be proud of yourself for solving problems, not for your place and rating change.
Write AtCoder
No explanation needed. Just do it.
Do not force ideas or algorithms on problems
Basically this: On "is this greedy or DP", forcing and rubber bands
You can (and should) try to think “Can I do greedy? Can I do dp?” and similar. What you shouldn’t do is to believe that the problem must be solved with any particular algorithm and only try to come up with a way to make this particular algorithm work.
One very special example of this is guessing solution or complexity from constraints and/or underlying objects. Yes, it is useful information to know which complexity is expected. But you can’t determine it with 100% certainty from the constraints, and that doesn’t dictate which algorithm to use.
And do not choose an algorithm first and solve the problem later. Algorithms are tools you use to implement the solutions efficiently. If someone asks you to help assemble furniture, you don’t say “I’ll take my allen wrench, that’s all I need” without reading the manual. There are significant differences in problem solving, of course. First of all, you don’t have the manual, you should write the manual yourself, that’s called solving the problem. And second, all your toolbox is in your head, so it doesn’t cost you anything to bring the whole toolbox to the problem.
Do not write a segment tree if you don’t know how to calculate the answer for one query with $$$n < 1000$$$. Do not take your allen wrench out of the toolbox before seeing the screw with hex socket.
Ask yourself questions
When reading the problem statement:
- Why is this limitation here? How would the problem change if it is not here?
- What is unusual?
- What the problem asks me to do?
- Can I reformulate it as some standard problem? as a play on some standard problem? as a special case of some hard (NP-complete maybe) problem?
While solving the problem:
- How would I solve an easier version of this problem? Decrease limitations. Change the underlying object to something simpler: [graph] → [connected graph] → [cactus] → [unicycle] → [tree] → [bamboo/array] or [star]; [matrix/grid] → [array]. Is there some observation that would work for the general version too?
- How to answer one query?
- How would I solve a small case on paper? How would I solve it without time or memory limitations?
Before implementing the problem:
- What’s the complexity?
- Do I understand the problem correctly?
- What functions do I need?
- Which places are tricky? What do I need to remember to implement them correctly?
- Which place is the heaviest by implementation? Can I do it simpler?
- Which place is the slowest? Where do I need to be careful about constant factors and where I can choose slower but simpler implementation?
If not AC:
- Did you remember to do everything to handle the tricky places you thought about before?
- Is the solution correct?
- Do I understand the problem correctly?
If you have a test on which the solution gives wrong answer:
- Is the solution doing what it was supposed to do?
- Is the problem in the code or in the idea?
If stress-test cannot find the counter-test:
- Do I understand the problem correctly?
- Is my stupid solution definitely stupid? Does it use any assumptions/observations from the main solution?
- Am I generating all possible test variants? Does the problem have multitest, and if so, am I generating multitest?
After getting accepted:
- What could I have done better?
- What areas took me more time than I would like?
- Are there any tricks to simplify the implementation?
Don't solve by topic
Don't even look at problem tags. They are spoilers that prevent you from progressing.
But Um_nik, the best way to learn how to do X, is to do X. I want to be good at DP, therefore I need to solve DP problems.
True statement, wrong conclusion. What you want to be good at is not only solving DP problems, but most importantly recognising DP problems. And you consistently skip that step when you solve problems by topic. You immediately go from reading a problem to putting it in DP terms, you don't experience the realization that problems can be solved as DP, you don't gain knowledge of how those problems present themselves in your mind.
So, when you solve the problem without any hints about the topic (for example, in the contest setting), you don't know how to make the first step, even though you may be able to do everything after that.
Upsolve to your next level
Let's say you want to be able to solve ABC div2 during the round. Well, the best way to do that is to always solve ABC, but not necessarily during the round. Upsolve! You can do it on your own or with an editorial. If there is a hard implementation point that you cannot figure out, try to understand someone else's code for that problem.
It’s not a replacement for solving archives, it’s addition. Archives have a lot of problems (duh) and most of them are old (duuh). That can create an incentive for you to skip “random half” of problems, which is not actually random, but the problems you subconsciously didn’t like. By upsolving you are making sure that you are covering topics that appear in the current meta.
The best way to learn how to do X is to try to do X.
Don't try to create problems that MUST have a specific solution
I don't know how to help you be a good problem setter. But I know one thing. Creating a problem to fit a solution doesn't mean that that solution will be optimal for the problem. You may create the most convoluted data structure out there for something that in the end can be better solved with a simple greedy. And if you try to impose restrictions on your problem to prevent simple solutions, you are making your problem uglier or giving away your solution via restrictions.
You can still find inspiration anywhere you wish, and starting from a solution is a good way for beginners to get into problem setting. It is also a fun way of getting familiar with some new topic, even if you don't end up with any actual problems, you still learn more about mathematical models surrounding similar settings. But if you come up with a problem, you should immediately forget about your solution. Well, you should remember it, yes, but treat it as A solution, not THE solution. It is just some idea that you had, but it may not be the fastest or prettiest way to solve your problem.
The first episode of Um airs tomorrow, here is the link. I hope you'll enjoy it!
I added three more problems to the list. After the episode is released I will add the slides I used.
aryanc403 made a nice checklist for tracking your progress on Um problems.
My YouTube channel, Discord, Um_nik World, Tutoring.
I will not do a CF blog each time something is released in the future, so join Discord if you want to follow the news.
Hello Codeforces! I have some big news.
I am trying to fight depression and live a fuller life. That includes some self-realization, maybe even (I don't even want to think about it) a job. I love cp, and I love teaching, and I know I already tried that, but I believe that this is the way.
With the help of my wife, I started to work on some related projects, and today we want to share them with the world. All of them are in the early stages, but we set a hard deadline for March 1, so...
Um
Um... I am starting a series of educational YouTube videos / selected problems.
Every episode of Um is focused on one problem. I will explain how to solve this problem and talk about some related concepts. The idea is to show off some cool concepts using real problems.
The kicker: the problem is made public at least a week before the episode airs. So you can use Um as a source of problems. I will try to choose nice problems that highlight some ideas, and problems that I consider beautiful.
I am planning to do an episode every day. I might have to scale down later, but right now I'm excited. These videos will be much more scripted compared to my screencasts.
List of problems/episodes First week of problems is already there, the first episode will air on March 8. Note that you are able to filter the problems.
You can also join discussion channels for Um in Discord.
Um_nik World
Unfortunately, it is not an amusement park.
I created a Notion space for anything related to me. The most notable page is the Um_nik manual — my attempt to explain my notorious personality and help you communicate with me without pain.
I also created a Discord server. A place for conversations where I can ban you — what's not to like?
Um_nik Training Center 2.0
I have succumbed to requests for one-on-one lessons and I am officially starting tutoring.
This is hard for me to do. The only way to do this for me is to be completely honest. I don't see why you would want to have lessons in competitive programming. But if you do want them, you want them with me.
I don't want to break CF rules more than I already did, so... If you are interested, read the tutoring section in Um_nik World. If you are a bit interested, join the Discord server and maybe follow the Um series. If you like my videos, you will probably like my tutoring.
Disclaimer: This blog is not about competitive programming; you probably will not learn anything about algorithms and data structures. In other words, it doesn't qualify for this initiative, but I want to give a link to it anyways because I think it's cool.
I love solving problems. No, seriously. I LOVE it. The mindset described in this blog is 100% how I feel. But it is not constrained to competitive programming problems. I loved math problems for a much longer time, and physics was somewhere there. But I also love solving puzzles. And playing puzzle games on the computer (well, on consoles). And participating in intellectual games. I am not as good in them as in cp, but it was never about being good for me, I just love the process.
And I think that there might be some people with a similar love for puzzles among competitive programmers, this is why I decided to write this blog on CF and not because this is the only place on the Internet where my opinion matters a little.
So, there is this thing called puzzle hunts. Basically, it's a set of puzzles, but they don't tell you the rules. And the idea is to bend the rules even if there are some. Some blog about puzzlehunts. The quote in the beginning is great:
Imagine a word search.
Now imagine you aren’t told what words to look for.
Now imagine you aren’t told it’s a word search.
Now imagine it isn’t a word search.
I'm not experienced in this at all, my first puzzle hunt was a year ago. 2023 MIT Mystery Hunt ended yesterday, and this weekend was one of the most fun experiences of my life. And I encountered the best puzzle of my life to date (which is not saying much). Spoilers for MITMH23 below.
Enter Showcase (I would not be surprised if the link will not open, the hunt just ended and I don't think the site was totally transformed into free form, so you might have to wait a bit; UPD we now have a PDF courtesy of one of the authors). Authors of this puzzle include
This is a spoiler not only to the puzzle but to the story below
This story starts around 1 pm (in my timezone) on Saturday. I open the puzzle and see 12 small grid puzzles. I love grid puzzles, I want to try and solve this one. Flavor text says
This is the last thing I'm putting under a spoiler tag, I WILL SPOIL THE SOLUTION TO THE PUZZLE
which probably means that I won't be able to solve the grid puzzles as is. But I don't understand what to do instead, so after some staring, I decide to try anyway. Surprisingly for me, the first 10 puzzles are pretty normal, they have a unique solution and some of them are interesting to solve (try E, H and I). This doesn't really help, as I still have no idea what to do next. I switched to a different puzzle.
Around 2 am in the night I thought that we should request a hint. The hint was "Read the flavor text carefully — it seems to be directing your intention to certain parts of the logic puzzles' instructions. Read those parts in order to find a cluephrase for what to do next." I did that and got... FIND ANOTHER CONTEST MIT WON RECENTLY, WATCH BROADCAST AFTER HOUR FOUR, OVERLAY LETTERS FROM FITTING ACRONYM IN SPOKEN ONE MAYBE TWO WORDS WITH TITLES.
MIT won the finals a couple of months ago... broadcast? hour four? wait, there are 12 puzzles which are numbered with letters?! Yes, this is certainly about ICPC WF. And look, this final has exactly 12 problems! I'm calling VArtem, who was one of the two not-yet-asleep members of our team, to join me.
Intrigued, I open the recording of the broadcast. They are talking about FFT, which is an acronym... but what to do with it? Rewatching several minutes around the 4-hour mark, nothing. But it is surely about the finals, and we should match 12 puzzles to 12 problems in the problemset. We look at the names of the problems, we open the problemset (I didn't want to spoil the problems to myself, but MITMH requires some sacrifices (mostly sleep)). Here it is, crystal structures (did you notice 12 phrases under the puzzles?)! But no, nothing else matches...
And then VArtem says:
- He said it! He said "writing system on them"!
- What? — I'm confused.
- One of the phrases! ecnerwala says it on stream!
Since I was rewatching several minutes around the 4-hour mark for the fifth time, I was too slow here. But the hint was to watch broadcast after hour four, not right after.
So, ecnerwala is going through the problemset and saying the phrases. We found couple more and... why is he saying weird words? People don't normally say "discrepancy" and "inconspicuous". Wait, ecnerwala. ecnerwala is from MIT. They didn't just take a video and made an ICPC-related puzzle. He is doing that on purpose!
Then we spend half an hour trying to hear phrases from the statement and writing down words. Then half an hour more for problem F. Then we just gave up. From the official solution to the puzzle: You might have encountered some difficulty finding the special phrase for Problem F — this was because the stream cut out while Andrew was covering this problem! We had to get Andrew to re-mention problem F some 30 minutes later, at timestamp 4:54:30.
Okay, we got almost all weird words and correspondence to problems, what's next? After several minutes I notice that several grid puzzle names have the same length as corresponding weird words. What was it, "OVERLAY LETTERS FROM FITTING ACRONYM IN SPOKEN ONE MAYBE TWO WORDS WITH TITLES"? We had to write down two words instead of one to get all lengths to match, but other than that it looked good. Ok, ICPC would be a fitting acronym, but... wait. Wait wait wait wait. All the weird words have a subsequence ICPC. Seriously?
Taking the corresponding letters we got ORDERPROBLEMSBYMITSO????IMETAKEFIRSTLINEOFOUTPUT. Or ORDER PROBLEMS BY MIT SOLVE TIME TAKE FIRST LINE OF OUTPUT. Output? Puzzle solutions you mean? Ok, we try, and it doesn't look good. Sample output? Doesn't look good either. After another half an hour of trying different things we decided to take another hint. Maybe we shouldn't have do it so soon, but we (well, at least I, can't say for Artem) really wanted to solve this CP-related puzzle and it was already 4:30 am.
The hint says "What does "output" mean in the context of ICPC problems? You'll need some corresponding "input", where can you find it?".
I mean... we still haven't used the puzzles. Could it be?.. We look closer at the puzzle solutions...
For the next 20 minutes me and VArtem are just sitting there and each minute one of us says some variation of "this is amazing". THEY MADE 12 GRID PUZZLES WITH DIFFERENT RULES (some of them are even good) WHOSE SOLUTIONS ARE VALID INPUTS TO ICPC WF PROBLEMS. I will repeat that and I don't think that caps is enough to emphasize what has happened.
THEY MADE 12 GRID PUZZLES WHOSE SOLUTIONS ARE VALID INPUTS TO ICPC WF PROBLEMS. ICPC WF is a serious prestigious competition. I am pretty sure that ecnerwala did not know anything about the WF problems before the contest. The problems could have had wildly different input and output formats. This is just unbelievable to me.
And don't get me wrong, the puzzle before that was also very good and very cool. ICPC subsequence is cool, and what's even more amazing about it is that ecnerwala managed to naturally mention all the words he needed as it was a normal discussion of the problems. And again, they didn't have the problemset beforehand, so they had to come up with all these natural-sounding phrases in 4 hours between the start of the contest and Andrew's amazing performance. They could have prepared some words with ICPC subsequence, sure, but to include them into a text about a problem...
But the puzzle to inputs step knocks it out of the park for me. Obviously, unlike ICPC words in the broadcast, the grid puzzles and their names were not written in 5 hours, but I couldn't do it in a lifetime. I want to show my appreciation to the authors. And I'm really happy that in our team the people who solved this puzzle could appreciate it to the full extent (I would be surprised if there was another team with 2 former ICPC world champions (actually we had 4, including tourist (see, tourist does it, it is surely the secret ingredient to being LGM))).
So, a big thank you to ecnerwala, ksun48 and other authors. I assume that you guys are a part of teammate? Probably your experience in puzzle hunts is much more valuable than mine, so it would be cool to hear from you.
And if I convinced you to look at the puzzle hunts, here is a short guide I wrote for our team. It is bad, and there are much better guides out there, but I made it, so here it is.
I'm all for companies sponsoring CF rounds and getting PR from it, authors deserve the salary, and CF has to get money for those somehow (paid rounds anyone?). But can we please stick to numbering for rounds instead of putting random words in the name (or keeping the number in the brackets)?
That's what my folders for rounds look like (and I don't like it):

Example from Codeforces, lol, why can't we do it every time?
I noticed that in many recent round announcements authors thank the coordinator for some kind of especially good coordination.
803
801
800
795
793
Did those coordinators do something special? If so, what exactly was so amazing about their work?
It is also interesting that they are using different words every time, which makes me think it is a meme of some sort. Is it?
I came up with this idea when solving an AtCoder problem, but the editorial had a simpler solution. I liked the idea, so I decided to set a CodeChef problem using this idea. Since most of you guys don't participate in CodeChef contests, which is a big mistake, I'll write a short blog explaining the idea. Consider this a spoiler warning for these two problems and a CodeChef promotion.
Combinatorial problem
For given $$$a$$$ and $$$n \le 10^5$$$ calculate $$$A_k = \sum_{i=0}^{k} \binom{k}{i} \binom{n-k}{k-i} a^{i}$$$ for each $$$k$$$ from $$$0$$$ to $$$n$$$.
(Use the two links above to see why anybody would like to do that)
Reformulation with polynomials
It is easy to see that $$$A_k$$$ is $$$((1+ax)^{k}(1+x)^{n-k})[x^k]$$$ (coefficient of $$$x^k$$$ in polynomial $$$(1+ax)^{k}(1+x)^{n-k}$$$). But since the polynomials are different for different $$$k$$$ this doesn't seem very helpful...
Solution
Let's generalize this a bit and say that $$$P$$$ and $$$Q$$$ are polynomials of degree at most $$$d$$$ and we want to calculate $$$P^k Q^{n-k} [x^k]$$$ for all $$$k$$$ ($$$d = 1$$$ in the problem above).
Let's apply divide-and-conquer. Let's say we want to solve the problem for $$$k \in [l, r]$$$. Then all the interesting polynomials will be divisible by $$$P^l Q^{n-r}$$$. Let's say we somehow calculated this polynomial. For given $$$k$$$ we will then have to multiply it by $$$P^{k-l} Q^{r-k}$$$. But the degree of this polynomial is $$$d(r-l)$$$, and since in the end we will be looking only at coefficients from segment $$$[l, r]$$$, right now we only care about the coefficients from segment $$$[l - d(r-l), r]$$$, all the other coefficients can't affect the answer. So, the number of coefficients we are interested in is $$$O(d(r-l))$$$. Let's write a recursive function that will take $$$l$$$, $$$r$$$ and a segment of interesting coefficients of $$$P^l Q^{n-r}$$$ and will find all the answers for $$$k \in [l, r]$$$. We'll choose $$$m = \frac{l+r}{2}$$$ and recurse to $$$[l, m]$$$ and $$$[m + 1, r]$$$. To recurse to the left, for example, we'll need to multiply $$$P^l Q^{n-r}$$$ by $$$Q^{r-m}$$$ and take a segment of coefficients. Since both polynomials have degree $$$O(d(r-l))$$$, we can multiply them in $$$O(d(r-l) \log (d(r-l)))$$$ time. To get $$$Q^{r-m}$$$ one can use binary exponentiation, it will work in $$$O(d(r-m) \log (d(r-m)))$$$ time (if $$$d=1$$$, one can use binomial theorem instead). The total complexity will be $$$O(nd \log^{2} n)$$$.
CP is about solving problems fast. And as absurd as it may sound, I believe that SOLVE and FAST are very different and almost independent parts, and you need to practice them separately.
Let’s look at some contest, like a CodeForces round. For the sake of simplicity let’s assume that every problem has some difficulty, which is a numerical value denoting how hard it is, bigger values correspond to harder problems (it is not true, but it is an ok-ish approximation, at least if we consider subjective difficulty for a fixed person). Contests are made for a wide range of participants, and problemsetters strive to make contests interesting for a wide range of participants, which means having a smooth difficulty gradient. Well... as smooth as it is possible with 5-6 problems.
Graph 1
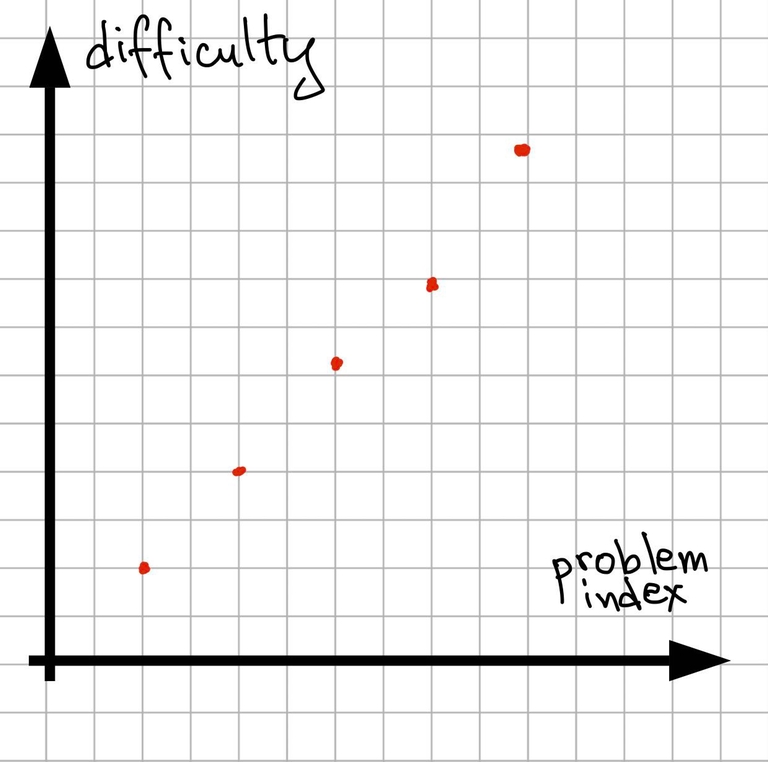
On the moment of a contest you have some ability to solve problems. If we assign each problem with numeric difficulty, it is reasonable to say that your problem solving ability is also a number on the same scale. But it doesn’t mean that you can solve all the problems below your level and can’t solve anything above your level... it’s more like “probability distribution”, or maybe how much time you need to solve the problem of given difficulty:
Graph 2
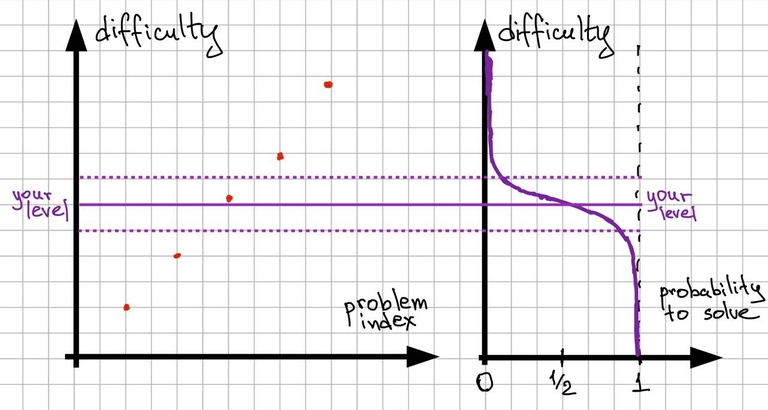
The issue is this probability distribution is something close to sigmoid: You can surely solve the problems that are much lower than your level and you solve them almost instantly after reading; on the other hand, you need too much time, maybe even infinite time, to solve problems way above your level. And that interval of difficulties which is not too easy while not too hard for you is rather small. Let’s call this interval interesting.
Since one contest has only a few problems and should cover a wide range of difficulties, there is usually one problem in your interesting interval, rarely there are two, sometimes there are none. These are the situations to which some participants refer to as speedforces: your result in the contest depends on how fast you solve easy problems. I don’t want to disappoint you, but almost every contest is a speedforces contest in a sense that your result is mostly determined by your speed and accuracy on easy for you problems or, how I call them, problems that you already know how to solve. In a contest, you don’t have time to come up with something completely new and original. Yes, you need to get what is the problem about, unravel some layers of reductions and implement the solution, but in a nutshell you know how to do every small part of the problems you will solve in the contest before the contest even starts.
What I’m trying to convey is that in a contest your goal is to solve the problem that you already know how to solve fast. By doing X you learn how to do X, so by participating in contests you learn how to solve problems fast. But then where do you learn how to solve problems?
To learn how to solve problems you need to solve problems, solve problems that you don’t yet know how to solve, but that are possible for you to come up with, maybe using a lot of time. These are the problems from the interesting interval, slightly above (or below in some cases) your current level, but not too much above because otherwise you can’t solve them yet. So we need to somehow find a lot of problems near your level, how to do that? The answer is rather simple: go to a place that has a lot of problems of various difficulties and doesn’t have a time limit. It is not a contest, it is an archive.
Graph 3
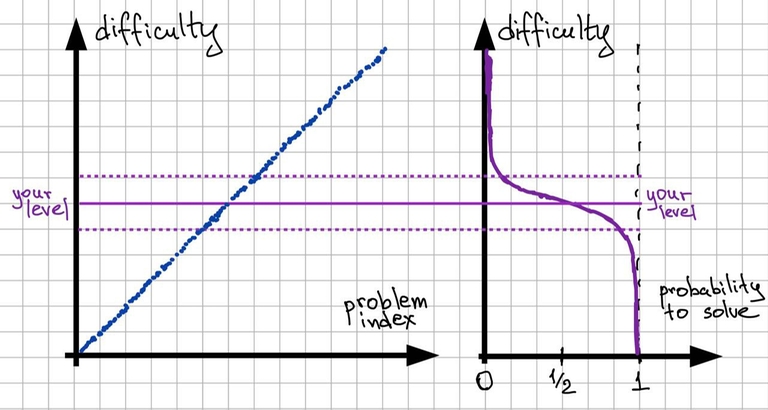
Just by having a lot of problems archives can almost always provide a problem of needed difficulty. And you don’t really need to do anything special to achieve that: sort the problems in the archive by difficulty and solve them. After the first period when the problems are too easy for you you will always be at a level where the next problems are the right difficulty for you because after solving a hundred problems your level will rise a bit, but so will the difficulty of the next problems.
I notice that nowadays many people start from CodeForces contests, and I think it is bad and it is the underlying reason for many frustrations. Some things that come to my mind:
- Newbies are ok with repeating problems in contests, problemsetters shouldn’t be so worried about problems being fresh — you should solve old problems in archives, learn classic techniques there and then use them in contests, contest problems need to be fresh.
- Where will we learn stuff if in contests there are no problems on classical techniques — again, learn the techniques themselves in archives, then you will see that there actually are problems that use classical techniques in contests, and obviously, there should be no problems that just are classical in contests.
- It is hard to make a training regime out of contests — it is, and you shouldn’t do this, contests should be only a part of training regime.
- Contests allow that self-deception thing: you can solve a lot of problems in contests, but they are the problems you already know how to solve and that doesn’t increase your level.
The questions that I anticipate (ask your questions in the comments if needed):
Q: How long do I try to solve the problem in the archive before reading the editorial? Like, 30 minutes?
A: You don’t read the editorial. The best option is to choose an archive that doesn’t have editorials at all, so you don’t have to fight the urge to look at the solution.
Q: Ugh, and what should I do if I can’t solve the problem?
A: Abandon it, for now, switch to a different problem, return to it after a month or so. My usual approach was to open 10-15 problems, read them carefully, think a bit, choose the one I want to try and solve now, try for some time. If I don’t feel like I’m getting anywhere, switch to another problem.
Q: Month?!
A: Maybe even more. You need time to acquire new skills and discover new ways to look at this problem (by solving other problems). It doesn’t make sense to return in less than a month because you will only run through the same ideas you did before.
Q: Ok, but how do I learn new techniques if I don’t read editorials? I’m not supposed to invent everything on my own, am I?
A: Most of the time you don’t need to learn any advanced stuff to solve the problem, you can’t solve it because you are not trying hard enough or not paying attention to details or just being stupid. My experience even says that most Russian schoolchildren who do CP know too many algorithms.
Q: But there are problems that require some standard things!
A: OK, yes. The best option, in my opinion, is to have some person around who solves the same archive and is better than you. In case you are stuck on a problem for a long time (that’s not an hour, that’s several months) you should ask them “Do I have to know some standard technique to solve this?” Pay attention: not ask how to solve, or for a hint, just a yes/no question. Most of the time the answer will be “No”. In the case of a positive answer, they will be able to send you a link to an article or what to google to learn about the technique. After that, you still will have to apply this technique to the problem, and you are more likely to actually remember how to use it and why did you need it in the first place, which tremendously increases your chances to use it successfully in the future.
Q: OK, which archive should I use?
A: It is not that important, but you should use one and stick to it. I have used Timus because I’m from Ural region, there are numerous others: UVa, SPOJ, Codeforces archive (has editorials and too many problems, thus a warning) etc.
To sum it up:
In archives you learn how to solve problems, in contests you learn how to do it fast. I’m not saying that contests are not needed: speed is also very important, and it is good to keep you in competitive shape. Also participating in contests is just fun, that’s also very important.
Acknowledging this and separating learning how to solve from contests can lead to better training, I believe.
How to split the time between archives and contests? Well, contests are held in some fixed time, so when there is a contest that fits into your schedule, you shouldn’t miss it. Turn to archive when you want to practice and solve something which should be often, otherwise CP is probably not for you.
I can sometimes see people doing some CP-related projects for their courses/portfolio/community, and I want to suggest an idea of such a project that would benefit me as a CodeChef Admin and all the problemsetters, I believe.
Issue: There are a lot of problems on different platforms, and it is really hard to check if some problem was already used somewhere or not. Sometimes googling works, but most of the time I have to rely on my own experience and memory, which are far from perfect. It's hard to search for problems, because they usually have some kind of story, and the same problem can be formulated in a lot of different ways.
Proposed solution: Create some kind of smart database, that will collect the problems from all known sources and will have some very smart search engine that would focus on the internal meaning of the problem, instead of how it is formulated.
I have no idea how to do any of that :) I would assume that it would require some kind of very smart ML and a lot of community effort. But I thought that it might be an interesting project for someone and I really hope that it will be done by some amazing person.
Just a database of problems from different sources with any kind of full-text search would also be nice.
I think I'm ready to pay some reasonable money ($1000? I understand that it's small money for a high-level ML person, but I'm not rich) for a well-done job, and maybe we can crowdfund it even more.
Hello Codeforces!
I will hold a Q&A/AMA stream on Twitch on Tuesday, 21 MSK (UTC+3).
You can write your questions in chat during the stream, or send them in this form beforehand (for example, if you can't attend the stream in person). Recording will be uploaded on YouTube afterwards.
Questions written in Russian will be answered in Russian, questions written in English — in English, questions written in other languages won't be answered because I can't understand them. I won't answer a question if I don't want to. Hopefully, the multilingual nature of the stream will be resolved afterwards by interested people who will add subtitles.
Questions can be about anything, but once again, I won't answer a question if I don't want to.
Huge thanks to lperovskaya who has agreed to help with this.
UPD: I won't answer questions like "how to become red", "how to become better at topic X", "how to win icpc wf". Answer
UPD2: Thanks to those who have come to watch this clownfest, here is the recording, including the last part during which my internet has died.
I'm not allowed to bring my phone into contest area, but I can live-codeforces this ICPC Challenge
Hello Codeforces!
For the last half a year I have been working on CodeChef and was proposing ideas on how to change the problemsetting practices (hopefully, for the best). For some time the changes were in brainstorming phase, but as of now many of them are implemented. Today we are ready to share the information with you. But first I would like to approach people who are going to close this blog without reading:
If you are not interested in CodeChef contests at all, I think you should change your mind. Monthly short contests (Cook-Off and Lunchtime) have interesting quality problems, on par with Codeforces in my opinion (not AtCoder level yet, but who are?). Long and Starters are more targeted to newbie participants, with more classical educational problems.
If you are interested in setting problems for regular contests, you might want to do it on CodeChef. Some reasons:
- You don't have to set the whole round, as we work on per problem basis.
- This may be especially interesting for proposers of hard problems — you don't have to come up with easy problems. You can also propose a lot of problems on your favourite topics, as we won't put all of them in one contest.
- Your problem will be reviewed by me, discussed with me and then maybe enhanced. You might have different views on my persona, but it is hard to deny that I'm pretty good at this stuff.
- In normal circumstances your problem will be reviewed less than a week since submitting proposal. (You might have to wait for it to be used in contest though)
- We are pretty low on harder problems, so if you propose a (good) Medium+ problem you can expect it to be used soon.
- We pay more. I know, I know, we do it not for the money. But it is a nice bonus, isn't it?
With that sorted, let's take a closer look at what have we changed.
Some of the changes are internal and it's hard to show them, but hopefully those changes will simplify the life of contest admins and they will have more time and energy to work with problemsetters and oversee the contest preparation.
- We have separated reviewing problem proposals and admin-ing (coordinating) contests. Now we have a special person, whose job is to review proposals and try to improve them. That person is me right now, although I hope that this system will outlive me, as it is more fair and leads to better problems. Yes, better problems, as my job is not only reviewing the proposals, but also thinking on ways how to make them better. Most of the short contests in 2021 had at least one hard problem significantly improved during the review.
- Making problems better requires collaboration with setters, which starts from communication. We used emails before, and it was... not ideal. Now we have created a dedicated Discord server, where we create private channels for me to communicate with setters. On the same Discord server we create channels with all the setters for a particular contest, where they will be able to talk with admin, tester, and generally people working on the contest. Moreover, if there is an issue that requires some managing help (like providing access) it will be easy to ping managers. I will not put a link to the server here, and I ask setters who has it to not do it too: we want only people who are interested in problemsetting there.
- Many people hate Campus (the system which was used for preparing problems on CodeChef), and rightfully so. We don't like it either. That's why we have gotten rid of the entire UI and have built a new problemsetting portal from scratch. We have implemented many essential features which were previously lacking (bulk uploading of test files, bulk editing of time limits, and judges, statement history versions, copyable sample IO, etc), and are working on adding the missing features as well. We know we still aren't as good as Polygon, but we are working towards it. We ask setters to prepare the problem on Polygon, and then port them to CodeChef.
- This is an internal thing, but I'm very proud of it. In general, we have a big waiting list of problems that are approved but not yet used for contests. When we need to make the next contest, an Admin is assigned, and he then chooses the problem from the waiting list. This waiting list was stored in a Google Sheet, it was hard to maintain and even harder to choose problems from it, and mostly we had to rely on our memory to choose problemsets. Now the waiting list will be stored in Notion. We will have to migrate the waiting list manually, and this work is far from done, but the future of stuck-in-the-waiting-list problems looks a bit brighter now, as we will be able to actually consider them while choosing problemsets.
- The CodeChef problem setting portal is still not a very user friendly system. And to use it you have to somehow learn how to do it. There is a guide for it... accessible only by a link you have to somehow get. Also this guide is written several years ago. Yeah. Actually, there are more different guides, sometimes contradicting each other. But it's not much of a problem, you have close to 0 chance to find them. Well, this had to stop. Either by CodeChef dying out because the link to the guide was lost and now nobody knows how to upload problems, or by us making an effort. We have chosen the second way, and it's Notion to the rescue again. Introducing CodeChef Public Guides. It's very new, but at least there are links to all the old guides I could find. We are planning to write more articles on all things related to CodeChef problemsetting, and maintain them in relevant state. Right now there are articles on step-by-step process of setting a problem and what (not) to do when proposing a problem. I'm planning to write an article on good practices when working with Polygon next.
- We have increased our judge server capacity and have not had a queue issue in a long while. We are in the process of scaling it 4x (and more) in the coming months, which will allow our setters to not have to worry about keeping the testfiles to a minimum.
In case I have managed to convince you to become a problem setter on CodeChef, here is the link. But please read this first.
What changes would you like to see on CodeChef, either in problemsetting or in general? Please help us make CodeChef better by filling this form.
In case you haven't heard: ICPC announced that in the Championship (onsite in Moscow) Division of ICPC World Finals 2020 teams will use 3 computers (one per participant). And they did that less than 40 days before the contest itself.
I think this is ridiculous and this is not the competition we have been preparing for all these years.
If you think the same, please comment under this blog in a format you deem reasonable (you can follow my format or not).
Moreover, there was a suggestion from Alex_2oo8 to ignore ICPC and self-impose the rule to use one computer at a time. If you want to do that (in case ICPC will go with 3 computers per team), you can add such a statement to your comment too.
Big thanks to KAN who uploaded these two contests with ghosts and everything and even tuned up TLs a bit for CF.
2019-2020 Зимние Петрозаводские сборы, Almost Algorithmic Contest
The second contest was used as an OpenCup stage last season, while the first one was not published anywhere (except some secret Chinese servers I assume).
Selfpromotion: I really think that these two contests are amazing. The difficulty is comparable to ICPC WF or harder regional finals (but with a smaller number of easy problems, who needs them anyway).
I was the author of more than half problems from both contests, with additional problems contributed by KAN, vepifanov, ashmelev, kristevalex, Merkurev and WYOCMWYH. I also want to mention the authors of three original problems that were improved and reused in the second contest: Ferume, fake123 and dario2994.
Enjoy!
I'm just in a mood to shitpost. Don't take it too seriously.
Things that I have heard of, but don't know (imagine how many things I haven't even heard of):
- Li-Chao Segment Tree
- Segment Tree Beats
- RMQ in $$$O(n)$$$/$$$O(1)$$$
- Any self-balancing tree except treap
- Link-cut tree
- Wavelet tree
- Mergesort tree
- Binomial heap
- Fibonacci heap
- Leftist heap
- Dominator tree
- 3-connected components in $$$O(n)$$$
- $$$k$$$-th shortest path
- Matching in general graph
- Weighted matching in general graph
- Preflow-push
- MCMF in $$$O(poly(V, E))$$$
- Minimum arborescence (directed MST) in $$$O(E \log V)$$$
- Suffix tree
- Online convex hull in 2D
- Convex hull in 3D
- Halfplane intersection
- Voronoi diagram / Delaunay triangulation
- Operation on formal power series (exp, log, sqrt, ...) (I know the general idea of Newton method)
- How to actually use generating functions to solve problems
- Lagrange Inversion formula
- That derivative magic by Elegia
- That new subset convolution derivative magic by Elegia
- How Elegia's mind works
- Sweepline Mo
- Matroid intersection
If you know at least 3 of these things and you are not red — you are doing it wrong. Stop learning useless algorithms, go and solve some problems, learn how to use binary search.
We invite you to participate in CodeChef’s December Lunchtime, this Saturday, 26th December, from 9:30 pm to 12:30 am IST.
Note the unusual time. It starts at 9:30pm instead of the usual 7:30pm
You will be given a total of 8 problems (6 in Div2, 6 in Div1) to solve in a duration of 3 hours.
Joining us on the problem setting panel are:
Setters: Sahil sahi1422 Chimnani, Venkata Nikhil_Medam Nikhil Medam, Áron mraron Noszály, Nishant nishant403 Shah, Yogesh SeismicToss Sharma, Hriday the_hyp0cr1t3, Divyam divyamsingal01 Singal, Bhavyesh bhvdsi Desai
Tester: Rahul amnesiac_dusk Dugar
Editorialist: Taranpreet taran_1407 Singh
Video Editorialists: Chirayu Chirayu Jain, Prachi agarwal19 Agarwal, Darshan darshancool25 Lokhande, Yashodhan ay21 Agnihotri, Bharat Singla, Shivam Bohra, Aryan Agarwala, Radoslav radoslav11 Dimitrov
Statement Verifier: Jakub Xellos Safin
Mandarin Translator: Gedi gediiiiiii Zheng
Vietnamese Translator: Team VNOI
Russian Translator: Fedor Mediocrity Korobeinikov
Bengali Translator: Mohammad solaimanope Solaiman
Hindi Translator: Akash Shrivastava
Problem Submission: If you have original problem ideas, and you’re interested in them being used in CodeChef's contests, you can share them here.
Prizes: Top 10 Indian and top 10 Global school students from ranklist will receive certificates and CodeChef laddus, with which they can claim cool CodeChef goodies. Know more here.
The video editorials of the problems will be available on our YouTube Channel as soon as the contest ends. Subscribe to get notifications about our new editorials.
Good luck and have fun!
As this is my first contest as CodeChef admin, I wanted to add few words from myself. Please do consider setting problems on CodeChef, we need your help to create great contests! One of the advantages of setting problems on CodeChef is that you don't have to create whole problemset by yourself (though it is certainly possible, you can write directly to admins to [email protected] for LunchTimes and to [email protected] for Cook-Offs). Many new authors can't create whole problemset without experience, and that's totally understandable! Sending problems for review allows you to get feedback for our admins (Um_nik, 300iq, jtnydv25, Ashishgup and Morphy), and if your problem is good, you will get the invaluable experience of setting a problem for thousands of participants worldwide while working side-by-side with some of the best minds in competitive programming. Some of the best problems in this contest are set by first-time problemsetters, at least on such a level, and they did a great job, I'm looking forward to working with them again.
Apologies to SeismicToss for messing up the announcement :)
The contest is unrated due to queue and server issues.
Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Apr/25/2024 17:57:15 (k2).
Desktop version, switch to mobile version.
Supported by
