


I have resumed screencasts with commentary, you can find them here
→ Pay attention
Before contest
Codeforces Round 940 (Div. 2) and CodeCraft-23
44:37:10
Register now »
Codeforces Round 940 (Div. 2) and CodeCraft-23
44:37:10
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3648 |
| 2 | Benq | 3580 |
| 3 | orzdevinwang | 3570 |
| 4 | cnnfls_csy | 3569 |
| 5 | Geothermal | 3568 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3530 |
| 8 | Radewoosh | 3520 |
| 9 | Um_nik | 3481 |
| 10 | jiangly | 3467 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | adamant | 164 |
| 2 | awoo | 164 |
| 4 | TheScrasse | 160 |
| 5 | nor | 159 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 150 |
| 7 | SecondThread | 150 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions





In yesterdays ACL1 I got WA on problem B. It turns out that compiler ignored the function call inside assert, the same code with function call not in assert works fine. Moreover, Merkurev explained that the reason for that is -DNDEBUG flag, and my submission works on GCC.
I don't understand computers, I just memorized some stuff that's enough for solving puzzles. I want to ask why the -DNDEBUG flag used in Clang, but not in GCC. rng_58?
Since antontrygubO_o has became CF coordinator he is trying hard to make rounds which meet his standards for quality and (more importantly) beauty. I think he is doing a great job.
For some time there is a very vocal group of people who dislike his view on things. I feel like it will be hard for Anton to maintain his work if he would think that majority of people doesn't approve.
But I don't really think that this is a majority. If you enjoy rounds prepared or coordinated by Anton, please comment here with some positive feedback.
#AdHocProblemsMatter
I have to ask Snark about updates on OpenCup twice a week. If you are as tired and don't want to miss next Grand Prix — join this Telegram channel. I will try to post anything I was able to get from Snark. Hopefully he will come to his senses and will admin the channel himself some time in the future.
UPD: Snark has admin rights now, maybe we will get the news in time.

As you may know, Petrozavodsk SU holds training camps for top teams twice a year. This time we decided to try to do screencasts of our participation, you may find them here. Unfortunately due to some technical errors we lost screencast of the first contest and the last 2 hours of the second one (we are not pros in screencast area, sorry).
Please note that if you are going to participate in Izhevsk mirror or by other means participate in these contests, you may ruin the fun for yourself.
Any explanations why at the same time happened this to these legends? :O

I'm thinking about doing more videos, not only screencasts of rounds. For some time now I'm using OI Checklist by Rezwan.Arefin01 (cannot recommend enough, especially if you are preparing for hard IOI-style contests) as an archive, so I'm thinking about doing videos with editorials (more like my thinking process) for some old POI problems.
So, here are some questions for you:
1. Is this interesting?
2. Should I read (and think about) problems beforehand? Pros: I will have more structured thoughts about problem, I will know for sure if I will be able to solve this problem in a short time, ??? Cons: It is kinda unfair, it may look like I'm crushing it when in reality it could take hours for me to solve, ???
3. Should I do one-problem length videos? The problem is that I prefer to open some (3-6) problems, read all of them, and then think about each problem for some time, probably starting with the one I liked more.
4. Despite these are OI-style problems with partial scoring I'm trying to go for a full solution, most of the time ignoring groups. Sometimes full solution of these problems are really-really hard. Should I do groups always, or only when I'm stuck for long time, or other options?
5. Do you have any suggestions about what kinds of videos I should make? Or other things I didn't think about concerning this particular kind?
You can look at my channel here
UPD
Thanks for your input! I thought a bit myself and here is my current position:
I'm willing to invest some time to learn basic video editing (yeah, didn't do anything before, just recording screencasts), I hope that I will even add some things to screencasts in post. This way I can read some problems, then solve them one-by-one, but make separate videos for each problem. Mostly I will do "blind" attempts at problems, since most of your want to see me struggle :) I will go through groups if they are interesting, but rarely will implement partial solutions.
About lectures and lower-level educational videos: don't think so at least for now because it is not interesting for me.
Because of learning basic video editing I will be slower at first, but I hope to do first video in next few days, so stay tuned! Also later today I will upload USACO Platinum screencast, so you can watch this if you are interested.
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Hello!
I'm glad to invite you all to Round 576 which will take place on Jul/30/2019 17:35 (Moscow time).
There will be 6 problem in both divisions.
Round is based on Team Olympiad in Computer Science Summer School. It is (yet another) summer school for schoolchildren organized by Higher School of Economics and "Strategy" Center in Lipetsk. Almost all the problems are authored and prepared by teachers and teaching assistants in CSSS: Um_nik, Burunduk1, fake123_loves_me, MakArtKar, Villen3tenmerth, Aphanasiy, Gadget. One of the problems is authored by Merkurev (just because we are friends :) ). One more problem for the round was added by KAN.
I would like to thank KAN for CF round coordination, I_love_Tanya_Romanova, Merkurev, Rox and 74TrAkToR for testing, and Codeforces and Polygon team for these beautiful platforms.
Scoring will be announced.
Upd: We added one more problem to div.1 contest, now both contests have 6 problems (4 in common). The round is not combined, if it were, I would write "combined" in the title.
Scoring distribution:
div2: 500-750-1250-1750-2500-3000
div1: 500-750-1250-1500-1750-2250
Congratulations to our winners!
div.1:
1. Radewoosh
2. tourist
3. mnbvmar
4. Benq
5. pashka
div.2:
1. ChthollyNotaSeniorious
2. Honour_34
3. idxcalcal
4. shogunator
5. yijan
Editorial won't be published.
How do I choose contest for practice: go to Gym, set difficulty to 4+ and duration to 5h, look through the list. In some of the contests I already participated, it is clearly visible in the list.
Problem: On the top there are other contests I don't want, I have to skip them every time and this list is growing. Why would I not want given contest? Maybe I participated on a different platform, or maybe difficulty is not right for me, or maybe I want to leave it for later team training.
Obviously, CF cannot detect any of these issues. But maybe we can have button "don't show this contest for me", just like Fav button? MikeMirzayanov
Another (less useful for me, but maybe more useful for community) possible feature is to allow users with coach mode to change difficulty settings. C'mon, low red get total in 4h, how is this a 4 star.
Hello Codeforces!
Sadly there will be no OpenCup round this weekend, but instead I invite you to participate in a mirror of t.me/umnik_team Contest which will be held on Timus Online Judge this Sunday, 12 MSK. This contest was originally held on Petrozavodsk Summer Camp 2018 (if you participated in the camp, please do not participate in this contest). This is an up-to-3-person team contest with ICPC rules (one computer per team). Difficulty level is comparable to OpenCup rounds (not jqdai0815-hard, but certainly not for Div.2).
Author of most of the problems is me, with huge help from Merkurev and one problem from Kronecker.
Hope you will enjoy the contest.
Last three blogs on main page of CF shouldn't be on main page. And it become quite common thing in recent CF practice. Main page should contain only something that all users should see. Of course, round announcements, platform upgrades and sponsor posts should be on main. Blogewoosh had some rights to be on main because it was cool series of blogs which had chosen CF as its platform so CF should have praise it (but it would be nothing wrong for it to be just in Radewoosh's posts like everything else). But all other stuff? Let's look at some examples for the last year.
Important: I'm not saying that these blogs are bad. Most of them are good. But why are they on main page? CF have great blogs system, every user can write something helpful. Just don't put random stuff on main.
Some algorithm stuff which is better than other algorithm stuff, I guess:
C++ STL: Order of magnitude faster hash tables with Policy Based Data Structures
Linear Recurrence and Berlekamp-Massey Algorithm
[Tutorial] Searching Binary Indexed Tree in O(log(N)) using Binary Lifting
Don't use rand(): a guide to random number generators in C++ — this one is kinda mandatory for participating in CF rounds due to bad compilers on CF, so it is good that it was on main
Blowing up unordered_map, and how to stop getting hacked on it
Random contests in gym which are better than other contests in gym, I guess:
Original Gym contest: Geometry Special 2018
2018-2019 ACM-ICPC, Asia Xuzhou Regional Contest (Online Mirror on Gym)
ROI 2018 in GYM
Promoting Errichto, I guess:
Stream
Sums and Expected Value — part 1
Lecture #3 — Exchange arguments (sorting with dp)
More sponsored stuff??
Анонс кружков от tinkoff.ru
My Course at Harbour.Space University: Advanced Algorithms and Data Structures (January, 2019) — selfpromotion, also nobody should pay 1000 euro for a course no matter what this course is. This is just abusing position as Codeforces CEO
IDK
Lunch Club at ICPC WF
The D programming language in competitive programming
Codeforces Contests Picker Goes Live: Celebrating ICPC Season
Team dashboard
Let's bring souvenirs to the ICPC World Finals
Unnecessary blogs on main
MikeMirzayanov's personal blog:
Hello, ITMO! — yes, there are some inforamtion about platform improvements but it is just an excuse to write this post
Codeforces Round #547 (Div. 3) — round announcement? Um_nik is totally crazy. Well, yes, but the photo and "I'm so cool I made a round in 6 hours" is nonsense. Also how about wait in line for half a year like others do?
It looks like it is just a question of whether Mike saw and liked the post. MikeMirzayanov, CF main page is not your personal blog. Please don't use it as your favorite tab.
Someone suggested recording screencasts, I made a poll in my telegram channel (Russian only) and the idea was positively accepted. So, here is my first screencast. I think I will be doing them on every round (if possible) while someone is interested (because it is easy, just 4-5 clicks).
I know that some people would like me to do commentary, but on live rounds I'm trying show my best performance, so it won't happen. But you can suggest some things and maybe I'll do something.
I read Russian problem statements on screencast (because it is more convenient for me), but the code is in C++/Python, so it shouldn't be a problem.
UPD (10.01): I uploaded Hello 2019 screencast and almost uploaded round 530 screencast. I had bad internet connection when I was solving the contest, so I upload only now. Normally I will upload screencasts no more than 30 hours after the contest, so if you are interested in watching it, just go to my channel. I won't make updates like this in the future.
It is this time of year! Many people trying to summarize all the things happened during the year. And since I love to hate people, I want to make a vote for most annoying person on CF in 2018.
I know that I'm in top contributors list for too long, so to vote for given person you should downvote the comment with this person's handle(s). Due to the nature of voting through comments on CF, you can vote for many people, and you can also upvote comments if you find given person's comments helpful/funny/positive.
If you care for your contribution but want to nominate a candidate, you can PM me their handle(s), then I will write a comment to vote. Note that I will write that it was you who nominated this person, so it saves your contribution but not relationships with the nominee. I will ignore messages from people without rating.
If you hate someone already nominated so much that you want them to know, you can also PM me so I'll add you to list of people who nominated given person.
Obviously, you can nominate someone with your own comment, but watch out for downvotes.
Also, you can try to increase your contribution by nominating some very nice people unanimously loved by community. In that case I will nominate you right after that.
I know that I'm obvious candidate, especially after writing this post. But I don't annoy me, so go on and show me your hatred :)
Love you all, Um_nik.
Here are our champions:
-515 rotavirus
-316 riela
-264 MikeMirzayanov
-236 peltorator
-224 CodingKnight
-198 adamant
-166 droptable
-143 kostka
-135 300iq
-135 I_Love_isaf28
-134 I_love_I_love_isaf27
I wanted to write super-harsh blog but then I decided to split it into educational part and whining part. This is whining part. To read some cool stuff go here. This one will also be educational on a slightly different topic. And there will be A LOT of harsh stuff.
I'm not saying that I'm perfect. That round had some really bad problemsetting issues. Problem E was googleable, problem D had very weak tests against very stupid solution (so stupid that none of the authors and testers come up with it, moreover, it is so counter-intuitive that I don't know how so many people independently did it). In two constructive problems participants could look at jury's output, the feature of which I didn't know. And I'm sorry for these issues. BUT. This comment has very negative rating despite being so true. And no one are here to back me up. So I want to speak my truth as I always do.
Let me accompany you to the world of supposedly BAD STATEMENTS. aka statements written by Um_nik.
Problem C from 2nd division of CF Round #518 gets a lot of praise for having very bad statement. Let us look at clarification requests we get on this problem. My answers here are not answers to clarifications from real contest, they are my emotions.
I think that you should be ashamed for your clarifications so I will include handles. This is probably not ethical as a problemsetter to do it. But I don't care anymore. Maybe I will be banned from setting rounds on CF. That looks like a good thing for all of us. You don't want to solve my problems, I don't want to do anything good for you.
"Is it also necessary that if 2 colors harmonize each other they should be connected?" and similar
by sam29, arif.ozturk, aman28rwt, -rs-, Vshining, tgritsaev, L0rdV0ldemort000006, Huvok, seo, shinbay, Apptica, yurics, Distructed_Cat, Adoki, dalbaeb69, chrome, ASUS, cjc, its_ulure, GhostDrag, GhostDrag
Answer: Yes. That's what "if and only if" means. Literally. That is the meaning of these words.
"Excuse me, what is number k in prob C?"
by tgritsaev, dungdq, dalbaeb69
Answer: That's a good question, number k is not important for the problem, but I decided to introduce it to ensure that you'll understand that you should place only colored rooks on a chessboard.
"A,B harmonize; B,C harmonize; do A,C Harmonize?"
by harshit601, Fighter.human, Gudleyd, atrophy98, tshr
Answer: No. I have no idea where did you get it from. There is nothing resembling in the statement. Probably it's an attempt to explain some samples, but it is wrong on first sample.
"are there many solutions for sample tests or it's one solution only?"
by Bakry, _QWOiNYUIVMPFSBKLiGSMAP_, bhowmik, mahdi.hasnat
Answer: Another good question, we made global clarification about this later. This was obvious from the samples, I think, but it was a mistake not to write it. I'm sorry.
"In the first sample, we can't go from the blue rook to every green rook!!" and similar
by cfalas, OmarBazaraa, MonsterInMe, DesiChamp, cjc, aman_shahi2, DesiChamp, MonsterInMe, S.Jindal
Answer: Samples are correct. Statement is correct.
"Reply fast please"
by ck98
"The statement looks like it was done with google translate, i don't understand anything"
by AlexArdelean
Answer: That's important information.
"if there is a harmonized pair (a,b). do the ans must contain a set of union of a and b? or i can arrange without any union set."
by Distructed_Cat
"if there is a harmonized pair (a,b). is it a must to make the both set of color a and b connected?" by Distructed_Cat
"And any rook of one color is connected with any other rook of another color that means all rook of 1st color is connected with all other rook of 2nd color if both color harmonise with each other?"
by Fighter.human
"Is it necessary for two rooks of different colors to be in one set?" by bktl1love
"What is harmonize of color??"
by _Muhammad
"can i connect colors other than the described in the input"
by KyRillos_BoshRa
"Specail Judge?"
by C20192413
Answer: Do you fucking read your questions? I like that "I can't solve the problem with operations in statement, can you provide better operations for me?"
Many questions just asking to clarify what the hell is happening in this hellish statement. There are a lot more stupid questions, I just tired.
CF has a large number of participants in each round. If 5% of participants think that his/her time is more important than ours then we will have to answer 5-10 questions every minute. In this round we had 30-40 unanswered questions during an hour, waiting time to get answer to your question is 5-10 minutes. And if we can't understand your question, we spend several minutes on answering. Please. Please. PLEASE. Spend 2-3 minutes trying to answer your question yourself. Use samples. Reread the statement. This is a skill, you have to improve it. Read my blog.
Don't ask "please explain the problem, I don't understand it". We already did explain the problem. The thing called "statement". Read it. Carefully. Why do you think that we will come up with better explanation right now? We prepared this statement several days, we asked testers to read it and say if something is unclear.
Don't say that statement is bad because you can't understand it. The statement can be hard to understand because it requires some knowledge, not because it is badly written. And some statements require to know mathematical notation like "if and only if" in this particular case. I can't come up with better explanation of why there are so many people asking the same question. basically "what if and only if means".
Please assume that authors spend some time on your contest. Much more time than yours 2 hours. Because it is true.
You can remember that once I made round unrated because I found the mistake in authors solution. I didn't wrote a clarification "I think your problem suck" without explanation. I continued my attempts to solve the problem and waited for the end of the contest, then asked what is authors answer for my test. Because I expected that authors did their job well and too busy answering stupid questions during the round.
One more time I spend ~15 minutes trying to prove that my answer for sample is incorrect. When I did it, I send this clarification: "Are you sure that answer for third sample is 34? For me it seems that there are 3 valid trees, in each of them there are 6 possible ways to choose pair of vertices, and for each path there are two possible winning moves for Ember, so the answer should be 36." Compare this to what you do.
I also think that CF should abandon the practice of answering every clarification if possible. It will decrease the number of clarifications and decrease the time to answer one clarification. If I can answer "Read the problem statement", that should be the answer. If I can answer "No comments", that should be the answer.
I think I'm finished with whining about my statements. Now about this doomed community of supposedly smart people.
The thing you did called bullying. There are people who downvote everything I write independent of content. Next there are people who disliked the consequences of my words, even my comment is correct. And there are also people who don't like that I'm saying my thoughts and don't respect their idols.
I liked first comment about "should stop creating problems", and first comment about this after the round. All others don't have own thoughts and have to repeat one thing over and over again. Now it is not a joke, it is being animals.
The same goes for "mind is weak". Yeah, guys, you are so original, it was not me who said it first.
To adequate people in this community: I'm tired of speaking truth. This not your truth? Explain me why am I not right, change my point of view. You think that I'm right in some cases? Speak it up. These animals can attack lone people, but if they will see that I'm not alone, they could think for once. You think that I have no right to insult people, but the idea is correct? Downvote me, say that wording is bad, but express that you agree with meaning.
MikeMirzayanov, I understand that for you quantity is more important than quality. I'm happy that you have your army of stupid fanatics who will write "You forget to hail Mike" under each post. This army has defeated me. Congrats.
But Um_nik, we all know how to read, we have our whooping 2 month of experience! Oh, my sweet summer child, my experiments show that many people with kinda cool achievements like medals on ROI don't know how to read statements. But don't worry, I'll teach you. Well, probably you won't understand anything, because you didn't try to understand anything in your life, you expect all hard work to be done for you by someone else. Let's start!
Basic rules
- The result of reading the statement is usually pure math model. If story helps to build correct understanding, you can keep it, but still try to discard as many unnecessary details as possible.
- Imagine you want to tell the problem to someone else. What parts you want to tell? (According to my PM, this rule won't help you).
- Shorter = better.
- Simpler = better.
- Limitations are part of problem statement. Especially small limitations, because for small data you can try all the possibilities.
- Samples are part of problem statement. After building math model, check that you model working correct on samples, at least on small samples where you can check everything fast.
- Notes are part of problem statement.
- Try to find familiar patterns, maybe objects you already know something about. If you are given some connected graph with exactly one simple path between each pair of vertices, it's called tree. 4 letters instead of 12 words, see?
- Try even harder to spot something strange, something you not expecting. That probably will be the cornerstone of the problem.
- If there is some part of the statement you don't like, try to change that to something you like. Start with understanding the object, then simplify it. There are some problems which can be completely solved by this technique.
- If the model you get is very big, try to split it into some pieces. It would be great if pieces are independent, like 'solve problem1, then use its answer as input to problem2 and so on'.
- On first stages it can be useful to write your new statement. On paper. By hand.
- Problemsetters do not write random things in statements. But why would you believe me, since I'm a bad problemsetter? I don't know, maybe you shouldn't.
Some examples
I'll use Timus for almost all examples. If you see statement in Russian and you don't want to, there is a language switch in upper-left corner.
Assumed workflow: read the statement on Timus, try to understand and simplify it using the rules above. You don't have to read "solution" parts, but I warn you that my concept of reading statements works. I mean, "statement" parts will often contain huge hints to solution.
In most cases I won't write step-by-step explanations how I get the final version. You can say that that's not how teaching works. I can say that you don't want to study. I'll win, because that's my blog.
Statement
Solution
Statement
Solution
Statement
Solution
Statement
Statement
Harder examples
Now I'll try to explain something.
Statement
Solution
Statement
Statement
Statement
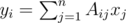 (maybe
(maybe Solution
Coolest trick of reading statements
Statement
Different math models will lead you to different solutions
Well, only if you have some patterns of how you should solve problems. And you should have them, patterns are good, they're the fastest way to solve problems.
Statement and Solution
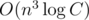 (intersect
(intersect Statement and Solution 2
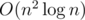 is standard and
is standard and  is possible, probably only with library code :)
is possible, probably only with library code :)Eliminating things you don't like can solve the problem
Last example in this blog will be not from Timus, it is 2016 Yandex.Algorithm Round 3, Problem F, shout-out to Endagorion for creating such pearl.
Problems visible only to participants, so I'll give already simplified problem statement here:
Given a tree, all vertices are initially white. Two players, Red and Blue, take turns coloring white vertices (surprise) red and blue. The game ends when there are no white vertices left. The score of the game is CR - CB, where CR is a number of connected components on red vertices, and CB is a number of connected components on blue vertices. Red wants to maximize the score, Blue wants to minimize it. Find the score if both play optimally. n ≤ 2·105.
Solution
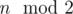 . So now we play not for components, but for edges. Better, but still not obvious.
. So now we play not for components, but for edges. Better, but still not obvious.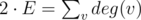 . But for calculating
. But for calculating 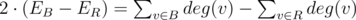 . Turns out this is true, because all RB-edges cancel out.
. Turns out this is true, because all RB-edges cancel out.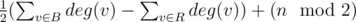
CODEFESTIVAL site is updated with info about this year edition but only in Japanese.
Using Google Translate I read that this time only people living in Japan are allowed to participate (at least in the final round).
rng_58, can you confirm this?
Main reason for asking now is that the Finals date is 17.11 which is very close to TCO onsite dates (13.11-16.11).
I want to apologize once more for queue problems. It has also aggravated some tight ML/TL issues which probably would be not so big otherwise. I hope you enjoyed the problems nevertheless.
Tutorial is loading...
Tutorial is loading...
38799800 — logs
38799811 — case analisys
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
I hope that Petr is not mad at me for my joke.
Tutorial is loading...
38799850
38799853 — completely different solution with complexity O(6n / 2)
Tutorial is loading...
Tutorial is loading...
I hope that PrinceOfPersia is not mad at me for my joke.
Tutorial is loading...
Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Apr/19/2024 20:57:51 (l2).
Desktop version, switch to mobile version.
Supported by
