Let integer number N to be power of 2. Now consider an array of N elements numbered from 0 to N − 1. We will name that array with “a” letter and “ai” will denote its i-th element. Imagine that we have some rule to modify single ai and we want to apply that rule to every element between ax and ay inclusive. We will call this range modification.
Consider binary operation which is associative, commutative and has identity element. Let it be denoted by × sign, for example. Imagine that we want to evaluate that operation over elements between ax and ay inclusive (ax × ax + 1 × … × ay − 1 × ay). We will call this range query.
I am to describe non-recursive algorithms for performing range queries and modifications within O(logN) using data structure that takes O(N) additional space.

This is schematic representation of the data structure built for array of 8 elements. It consists of 4 layers (log2N + 1 in general). Each layer contains a set of ranges that don't overlap and cover the whole array. Ranges of the same layer have equal size that grows exponentially from bottom to top. All the ranges are numbered in row-major order from left to right, from top to bottom. The bottom-most (numbered from 8 to 15 here, from N to 2N − 1 in general) layer is intended to hold ai array values. Other ranges hold an answer for their range query.
One may call this structure a segment or interval tree, but thinking that this structure is a tree will give you nothing useful here.
Range Query over Static Array
First of all we will discuss how to implement range query while ignoring modifications. Assume that we have already built the structure somehow. Then the sample C++ implementation for sum operation looks as follows. (Please note that zero is an identity element of sum operation.)
int staticQuery(int L, int R) {
L += N;
R += N;
int sum = 0;
for (; L <= R; L = (L + 1) >> 1, R = (R - 1) >> 1) {
if (L & 1) {
sum += a[L];
}
if (!(R & 1)) {
sum += a[R];
}
}
return sum;
}
Let's break the function's code down. As was mentioned before, ai element resides at i + N index in the structure. That explains what first two statements do: query's range bounds are turned into indices of the bottom layer. Next statement initializes sum variable with identity. This variable will accumulate the sum in the range to return the answer.
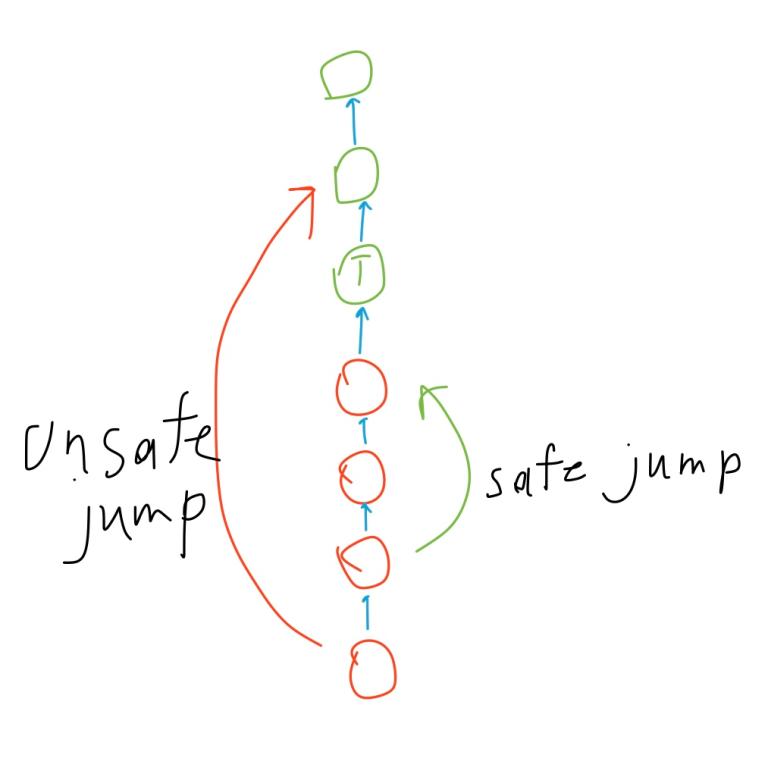
Now look at the for-loop and try to figure out how it changes L and R indices. In this picture colored ranges are ranges that were traversed while answering staticQuery(3, 7). Yellow ones were ignored, red ones were accounted. It's plain to see that red ranges don't overlap and their union is 3–7 range.

For simplicity I will explain the movement of L index only. Note that we must get into account a[L] value if L is odd because other ranges that cover L-range (1, 2, 5 ranges for L = 11) depend on ai values that don't appear in the query's range. That is what first if-statement checks. Of course we should ignore a[L] value if L is even because there is wider range that covers L-range and doesn't confront with query's range (3 range for L = 6).
As you can guess from the picture, the next range we will examine has L / 2 index (in case of even L). Generally, we will get a set of covering ranges if we divide L by powers of 2. In case of odd L we aren't interested in covering ranges, but we can notice that “interesting” ranges reside rightwards. It's easy to prove that L = (L + 1) >> 1 assignment takes into account both cases.
As for the R index, everything is the same. But because of this index is responsible for the right edge, everything will be right-to-left. That's why second if-statement and R = (R - 1) >> 1 assignment slightly differ from their counterparts. And of course, we must stop the for-loop when L > R because when L-range and R-range meet, the query's range is completely covered.
Note 1. It is possible to implement the algorithm in such a way that it won't require operation to be commutative. You can even avoid identity element requirement.
Note 2. If operation is idempotent (minimum, for example), you can omit both if-statements and rewrite body of the for-loop in a single line:
m = min(m, min(a[L], a[R]));
And don't forget that identity element of minimum is positive infinity, not zero.
Note 3. The algorithm can easily be adapted for multidimensional queries. Just look at the code for 2D-case.
int staticQuery2D(int x1, int x2, int y1, int y2) {
x1 += N;
x2 += N;
int sum = 0;
for (; x1 <= x2; x1 = (x1 + 1) >> 1, x2 = (x2 - 1) >> 1) {
int i1 = y1 + N;
int i2 = y2 + N;
for (; i1 <= i2; i1 = (i1 + 1) >> 1, i2 = (i2 - 1) >> 1) {
if (x1 & 1) {
if (i1 & 1) {
sum += a[x1][i1];
}
if (!(i2 & 1)) {
sum += a[x1][i2];
}
}
if (!(x2 & 1)) {
if (i1 & 1) {
sum += a[x2][i1];
}
if (!(i2 & 1)) {
sum += a[x2][i2];
}
}
}
}
return sum;
}
Modification of Single ai Element
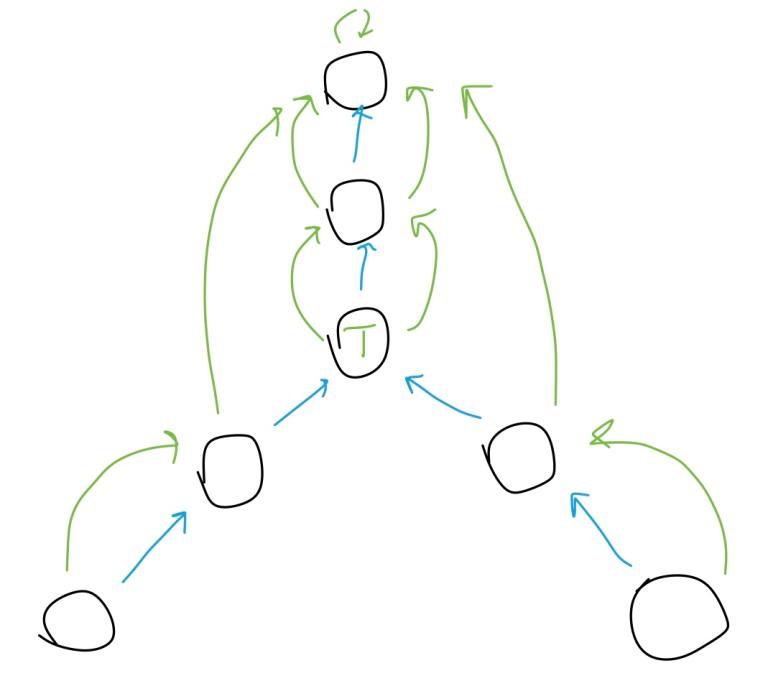
Performing single element modification is two-step. First, you modify the value stored at i + N index in order to modify ai. Second, you reevaluate values for all covering ranges from bottom layer to the very top.
void pop(int i) {
a[i >> 1] = a[i] + a[i ^ 1];
}
void popUp(int i) {
for (; i > 1; i >> 1) {
pop(i);
}
}
We already know how popUp() enumerates covering ranges, so let's focus on its subroutine. You can see that operation is evaluated over ranges with indices i and i ^ 1. It's not hard to figure out that these ranges are subranges of the same i >> 1 range. This reevaluation is correct because operation is associative. Please note that this code is not suitable if operation is not commutative.
Clearly, we can use single element modifications to build the structure up. As each modification has logarithmic complexity, the build up will take O(NlogN). However, you can do this within O(N) by using the following code. (You still need to load up values in the bottom-most layer, of course.)
void buildUp() {
for (int i = 2 * N - 1; i > 1; i -= 2) {
pop(i);
}
}
Range Query within O(log2N) after Transparent Range Modifications
Imagine we have a set of range modifications with different parameters. Then we apply these modifications over array in some order. This will result in some state of the array. Now imagine we apply the same modifications over original array but in another order. The result may be the same as previous and may be not. If result doesn't depend on the order we will call such modifications transparent. For example, “increment all the values between first and third inclusive by five” is a transparent modification.
Assume that the range we want to modify is not arbitrary but one of the presented in the structure. We can simply apply modification to its value, but it will leave the structure in inconsistent state. Although we know how to update covering ranges, we won't do that for every such modification because there is more efficient way to update them when we will perform modification for arbitrary range. So we will assume that covering ranges became consistent somehow. But there are still inconsistent subranges. Of course, we cannot update them directly, because their number is O(N). Instead, we will attach a modifier that will store parameters of that modification virtually applied to every subrange. Here's the code for performing increment with parameter p:
void modifierHelper(int i, int p) {
a[i] += p;
m[i] += p;
}
Although both statements look the same, they are different in sense. First statement performs modification itself using parameter p. Second statement calculates a parameter for modification in such a way that this modification is equivalent to sequential appliance of modifications with parameters m[i] and p.
Now, how to perform arbitrary modification. Recall that we already know how to represent arbitrary ranges from staticQuery() function. So the code for increment modification will be:
void pop(int i) {
a[i >> 1] = (a[i] + m[i >> 1]) + (a[i ^ 1] + m[i >> 1]);
}
void modify(int L, int R, int p) {
L += N;
R += N;
int LCopy = L;
int RCopy = R;
for (; L <= R; L = (L + 1) >> 1, R = (R - 1) >> 1) {
if (L & 1) {
modifierHelper(L, p);
}
if (!(R & 1)) {
modifierHelper(R, p);
}
}
popUp(LCopy);
popUp(RCopy);
}
Two last statements is a more efficient way to update covering ranges that I mentioned before. It's enough to do only these pop ups. Please note that the pop() subroutine has been changed. That's because i and i ^ 1 ranges are under influence of covering range's modifier.
Now, how to answer range queries. Note that we cannot just use staticQuery() function, because traversed ranges may be affected by modifiers in higher layers. To find out real value stored in the range we will use this subroutine which is just an appliance of all modifiers of covering ranges:
int realValue(int i) {
int v = a[i];
for (i >>= 1; i > 0; i >>= 1) {
v += m[i];
}
}
Then this code will perform range query:
int log2Query(int L, int R) {
L += N;
R += N;
int sum = 0;
for (; L <= R; L = (L + 1) >> 1, R = (R - 1) >> 1) {
if (L & 1) {
sum += realValue(L);
}
if (!(R & 1)) {
sum += realValue(R);
}
}
return sum;
}
Range Query and Opaque Range Modification within O(logN)
As opposed to transparent, opaque modifications' result depends on the order of appliance. However, transparent modifications can be viewed as opaque, and it makes opaque case more general than transparent one. In this section we will learn as an example how to perform range assignment and range sum query. (Range assignment changes each value in the range to desired value p.)
Simple trick with realValue() won't work anymore because now modifications in lower layers can affect modifiers in higher layers. We need a way to detach modifiers from the ranges we need to update. The way is “push down”. It is so called because it removes modifier at the range, and applies that modifier down to both subranges.
void push(int i) {
if (h[i >> 1]) {
modifierHelper(i, m[i >> 1]);
modifierHelper(i ^ 1, m[i >> 1]);
h[i >> 1] = false;
}
}
void pushDown(int i) {
int k;
for (k = 0; (i >> k) > 0; k++);
for (k -= 2; k >= 0; k--) {
push(i >> k);
}
}
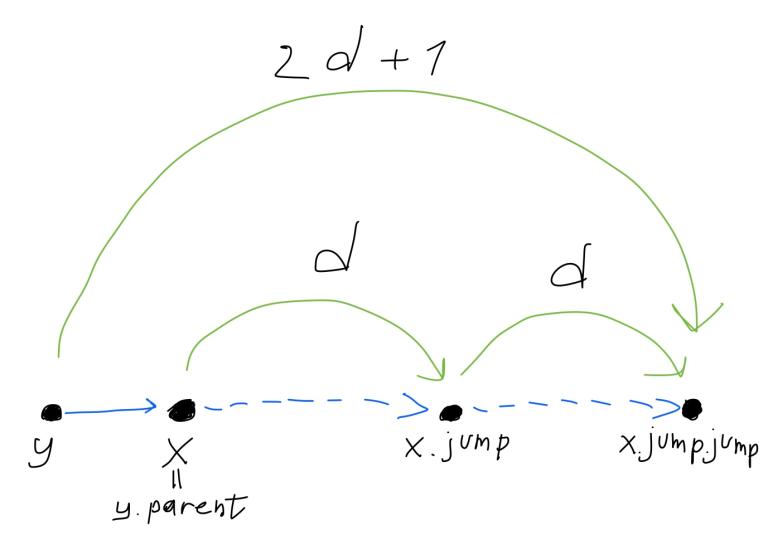
Let's look at pushDown() at first. All you need to know about this is that it enumerates the same indices as popUp() does, but in reverse order. This reverse order is required because push downs propagate from top to bottom.
Now look at push(). There is new value h[i >> 1] which is true if modifier is attached to i >> 1 and false otherwise. If modifier is present then it is attached to both subranges and i >> 1 is marked as free of modifier.
In order to support range assignments and sum queries we need new modifierHelper() and pop() subroutines. I believe it will not be hard to understand how they work.
void modifierHelper(int i, int p) {
a[i] = p * q[i];
m[i] = p;
h[i] = true;
}
void pop(int i) {
if (h[i >> 1]) {
a[i >> 1] = m[i >> 1] * q[i >> 1];
} else {
a[i >> 1] = a[i] + a[i ^ 1];
}
}
The only thing you couldn't know is what's the q[i] values. Answer is simple: this is number of array elements which covered by i range. Please note that these values are necessary for the problem of our example only, you don't need them in general.
The most direct way to calculate q[i] values is to use this routine which is similar to buildUp() function:
void makeQ() {
for (int i = N; i <= 2 * N - 1; i++) {
q[i] = 1;
}
for (int i = 2 * N - 1; i > 1; i -= 2) {
q[i >> 1] = q[i] + q[i ^ 1];
}
}
Clearly, after all necessary push downs have been made, we can modify range straightforwardly. There are only two push downs we need to do. So the code for range assignment is as follows:
void modify(int L, int R, int p) {
L += N;
R += N;
int LCopy = L;
int RCopy = R;
pushDown(LCopy);
pushDown(RCopy);
for (; L <= R; L = (L + 1) >> 1, R = (R - 1) >> 1) {
if (L & 1) {
modifierHelper(L, p);
}
if (!(R & 1)) {
modifierHelper(R, p);
}
}
popUp(LCopy);
popUp(RCopy);
}
Absolutely the same holds for range sum query:
int query(int L, int R) {
L += N;
R += N;
pushDown(L);
pushDown(R);
int sum = 0;
for (; L <= R; L = (L + 1) >> 1, R = (R - 1) >> 1) {
if (L & 1) {
sum += a[L];
}
if (!(R & 1)) {
sum += a[R];
}
}
return sum;
}
Note 4. Sometimes you can avoid use of h[i] values. You can simulate detachment by “undefined” modifier.
Note 5. If your modifications are transparent, you can omit push downs in modify(). Also you can avoid push downs in query(), but this won't be as simple as removing a pair of statements.
Surprise!
In the very beginning I have said that N should be integer power of 2. In fact, that's not true. All the algorithms described here work correctly for any positive integer N. So for any array of size N this structure takes just O(N) of additional space.