


Я нашел следующее решение с методом множителей Лагранжа задачи Core Training в этом раунде Code Jam. Мне понравилось это решение в частности потому, что в соревнованиях по программированию очень редко встречается задачи со множителями Лагранжа.
Пусть 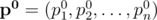 -- заданный вектор вероятностей успеха ядр и
-- заданный вектор вероятностей успеха ядр и 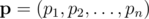 -- другой вектор вероятностей. Пусть
-- другой вектор вероятностей. Пусть 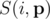 -- вероятность, что точно i ядр будут успешными, допустя что ядро i будет успешным с вероятностей pi. Тогда мы хотим найти максимум функции
-- вероятность, что точно i ядр будут успешными, допустя что ядро i будет успешным с вероятностей pi. Тогда мы хотим найти максимум функции

с ограничением
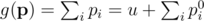
По методу множителей Лагранжа, мы знаем что любой максимум 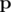 должен удовлетворить условию
должен удовлетворить условию
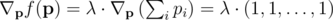
или лежить на границе множества решений (но мы сочтем этот случай попозже).
Лемма
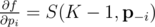
где 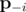 -- вектор вероятностей без pi, т.е. (p1, p2, ..., pi - 1, pi + 1, ..., pn). Иными словами, частная производная f по переменной pi -- это вероятность, что K - 1 других ядр будут успешными (без ядра i).
-- вектор вероятностей без pi, т.е. (p1, p2, ..., pi - 1, pi + 1, ..., pn). Иными словами, частная производная f по переменной pi -- это вероятность, что K - 1 других ядр будут успешными (без ядра i).
Доказательство Леммы
Разложим члены уравнения:
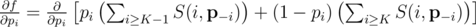
Упростим выражение:
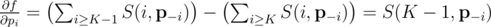
(Конец доказательства.)
Наивное решение 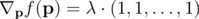 -- установить все pi равные друг друга. Но это невозможно потому, что мы не можем уменьшить pi меньше чем p0i. С учетом граничных условий, мы имеем для каждого ядра i три вариантов:
-- установить все pi равные друг друга. Но это невозможно потому, что мы не можем уменьшить pi меньше чем p0i. С учетом граничных условий, мы имеем для каждого ядра i три вариантов:
- Оставим pi как p0i.
- Увеличим pi до 1.
- Установим pi равные каких-то других {pj}.
Это наблюдение ограничает множесвто решений до такой степени, что мы можем его перебрать. (Ну, еще нужно несколько оптимизаий, например "увеличить pi до 1 только если pi уже велик", но это главная идея.)







