Does anyone still remember this problem Dreamoon and Ranking Collection?
In the statement of this problem, Dreamoon would like to collect all the places from 1 to 54. Now, after 41 more rounds, Dreamoon did it!
I'm very happy now, so I share my good news to the Codeforces community. ^_^






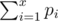 , while the maximum possible total score of
, while the maximum possible total score of 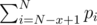 . So the problem asks us to make sure the minimum score of
. So the problem asks us to make sure the minimum score of 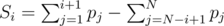 , which is the sum of the smallest
, which is the sum of the smallest 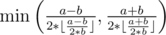 . Besides, the only case of no solution is when
. Besides, the only case of no solution is when 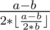 always dosn't exist or larger than
always dosn't exist or larger than 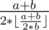 .
.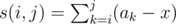 , we can write down the definition of poorness formally as
, we can write down the definition of poorness formally as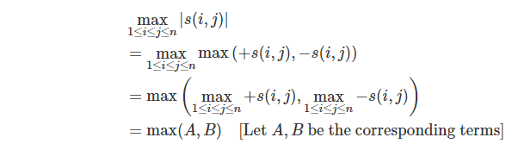
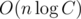 ,
,
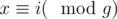 will become happy some day because of this person.
will become happy some day because of this person.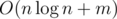 )
) using dfs only once. (if the length of every edge is
using dfs only once. (if the length of every edge is