


Here is a problem my friend smurty posed:
Say we are given an array of non-negative integers of length n, representing stacks of dirt of certain heights. We can move one piece of dirt from one pile to an adjacent pile for cost 1. What is the minimum cost it takes to transform this array to be non-decreasing?
Neither me nor my friend could come up with a polynomial time solution in n to this problem. Can CF think of something?
EDIT: BUMP






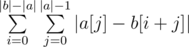 . Swapping the sums, we see that this is equivalent to
. Swapping the sums, we see that this is equivalent to 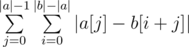 .
.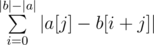 without going through each individual character. Rather, all we need is a frequency count of different characters. To obtain this frequency count, we can simply build prefix count arrays of all characters on
without going through each individual character. Rather, all we need is a frequency count of different characters. To obtain this frequency count, we can simply build prefix count arrays of all characters on 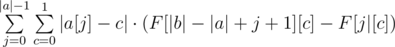 . This gives us a linear solution.
. This gives us a linear solution.
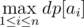
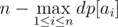
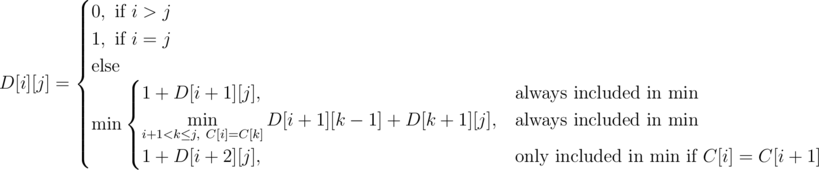
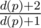 . As for the contribution of
. As for the contribution of 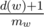 , the proof of which is left as an exercise to the reader.
, the proof of which is left as an exercise to the reader.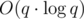 , Space Complexity —
, Space Complexity — 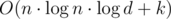 , Space Complexity —
, Space Complexity — 

{kind=link}