


Complete problemset + tests + original presentation of solutions.
Official scoreboard, public contest scoreboard, used for training elsewhere.
Short hints first, more detailed solutions afterwards.
A. Avoiding the Apocalypse
(difficulty: medium-hard, code)
Maxflow in a suitably selected graph. Ford-Fulkerson is sufficient.
The vertices of our graph need to correspond to states that one person can be in when traversing the original road network; the number of people moving in a group is then represented by flow along edges. Therefore, the most natural choice is to use vertices corresponding to states (location, time).
The rules from the problem statement say that at most c people can move along an edge e = (u - > v) in the original at any time. That means if we add an edge from (u, t) to (v, t + s) (s is the time it takes to traverse edge e), it needs to have capacity c; such edges fully describe these rules.
Staying in place is also moving, just into the same vertex; it takes one time unit. That adds some more edges (with infinite capacity, as any number of people can stay in place).
Now, a path of some person is represented by a unit flow in this graph. In order to find the maximum number of people that can get somewhere, we clearly want a maximum flow in this graph.
Wait, people can't wait forever! We still haven't used the restriction on time S till zombification, but that's simple — just don't use vertices corresponding to time > S. This also bounds the number of vertices to O(NS) and edges to O((N + M)S).
Furthermore, we need a source vertex vS, a sink vertex vT and edges from/to them; the answer is the maxflow from vS to vT. It's obvious that we need 1 edge from the source to the starting vertex of our group of G people (at time 0), and that edge should have capacity G. For edges to the sink, we'll use the last remaining part of the input (finally, the input is spent!): they need to go from the medical facilities, at time S (there's no harm in waiting for a film-like cliffhanger), and have infinite capacity.
All that's left is applying a standard maxflow algorithm, for example Ford-Fulkerson. That one has complexity O((V + E)F), where F is our answer (the maxflow), V and E are vertices and edges of our graph — in this case, it's O((N + M)SG). It actually runs in time, because its constant is fairly small and most tests are small or have small answers.
B. Button Bashing
(diff: easy-medium, code)
BFS in a graph of cooking times.
Again, we can construct a directed graph of states. In this case, each state will be a time set on the microwave so far; from it, you have N edges corresponding to button presses that lead you to a different time as described in the problem statement.
Obviously, you want to find the minimum distance from vertex (t = 0) to (t = T), or min. distances to vertices (t > T) (since you can always keep pressing one positive button, at least vertex (t = 3600) is guaranteed to be reachable) when necessary. One BFS is enough to find the min. distances of all vertices from (t = 0) and loop over all vertices (t ≥ T) until you find one with non-infinite distance.
There are O(3600N) edges in our graph, O(N) vertices, so our BFS takes O(3600N) time.
C. Citadel Construction
(diff: med-hard, code)
Convex hull; fix 1 vertex (u) of the quadrilateral, iterate the opposite one (w) along the convex hull and recalculate the furthest vertices v, x from line u - w on each of its sides. O(N2).
We need to pick a quadrilateral (possibly degenerated into a triangle) with maximum area. Obviously, a triangle is better than a concave quadrilateral, so let's stick to convex ones.
Suppose that we picked one diagonal of our quadrilateral. Its area is the sum of triangles made by this line segment and 2 vertices on opposite sides from it. Using the well-known formula: area (of a triangle) = base * height / 2, we realize that the most distant points from the line give the largest area, because the chosen diagonal is each triangle's base.
We can imagine taking a line parallel to our diagonal and moving it perpendicularly to it; the last vertices it crosses (depending on the direction of its movement) are the most distant ones. But this is equivalent to saying that these most distant vertices must lie on the convex hull — if we draw a line through a point that's not on the convex hull, there will be points (stricty) on both sides from it, the ones belonging to the convex hull. Applied to both diagonals, it means we only need to use points on the convex hull.
Let's now pick a diagonal between 2 vertices on the convex hull and rotate our coordinate system so this diagonal coincides with the x-axis. We need to find the topmost point (farthest from the x-axis on one side, the other side can be done analogously). By definition of convexity, as we go from left to right on the hull, the angle between the x-axis and the side of the hull we're currently moving along will be non-increasing, which means the y-coordinates of points we pass first increase (up to the first segment with negative angle) and then decrease.
If we rotate this diagonal around one vertex u of the hull, starting with position parallel (angle 0°) to one side u - v of the hull in that place, adding vertices to the part "above" the diagonal, the angles of all segments with the diagonal increase equally and the first segment with negative angle moves along the hull in the same direction we're adding vertices in. Therefore, we can use two pointers to store the other point of the diagonal w and the topmost point v.
Since the "bottommost" point x can be recomputed using the 2 pointers' method with w in parallel to recomputing v and we can calculate the respective area easily using vector cross products, this gives us (together with the convex hull) an O(N2) algorithm.
D. Dropping Directions
(diff: med-hard, code)
Build a graph with vertices (intersection, direction); it's a specific union of cycles. Adding a signpost points all locations on 0 or 2 cycles to the goal.
The graph we're given is not very good, since the next intersection depends on the previous one. A much better graph is a directed one with vertices (intersection, direction). In this graph, the next vertex is given uniquely and the vertex from which we had to arrive is also given uniquely, so it must be a union of cycles.
Furthermore, if we had a cycle in it along some intersections, then there must be another cycle in which the order of intersections is opposite — it corresponds to traversing the same path in the original graph, just taking the opposite direction at each intersection.
Now, what would happen if we added some signposts? Each vertex would still have outdegree 1, but some would have indegree 0, so each connected component would be a cycle with some trees (directed to the root) appended to its vertices as roots. The situation we want to obtain is for each component's cycle to contain one of the goal's vertices (there are 4 of them, and at most 4 such cycles).
Let's look at the intersections in the goal's cycles, and at signposts in them. Such an intersection corresponds to 4 vertices, two of which originally lied in the goal's cycles already. Adding a signpost would therefore point at most 2 other cycles to the goal. After we added such a signpost, we could look at the graph again, find an intersection that leads tourists to the goal in two directions (either directly along an original goal's cycle, or by finding the previously added signpost) and add a signpost to it, and repeat until the goal is always reachable.
In fact, we can always find an intersection such that adding a signpost would point 2 cycles to the goal this way. Thanks to our strategy and the symmetric property of our graph, we know that pointing one cycle to the goal means pointing its opposite direction cycle to the goal as well, so we point 0 or 2 cycles. And if we could only point 0 cycles, that would mean the original graph isn't connected.
Therefore, we can calculate the answer very easily: it's the number of components that don't contain the goal's intersection / 2. All it takes is one BFS for each component, in O(N) time total.
E. Excellent Engineers
(diff: medium, code)
A classical problem solvable simply using sorting and minimum-BIT in  .
.
The order of engineers doesn't matter, so let's sort them by their first ranks. Now, the only people who can kick an engineer out of the shortlist now have to be before him in the sorted order, so let's process them in that order.
For an engineer (r2, r3), we need to find out if, among people processed before him and with smaller r2, there's someone also with smaller r3. That's straightforward if we use a minimum-BIT: if we store in the BIT an array A[] with A[r2] = r3 for already processed engineers and A[r2] = ∞ for the rest, then it's equivalent to asking if 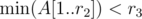 . Based on the answer, we can decide whether to add him to the shortlist. Then, we need to add the currently processed engineer by updating A[r2] to
. Based on the answer, we can decide whether to add him to the shortlist. Then, we need to add the currently processed engineer by updating A[r2] to 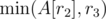 .
.
Sorting can be done in O(N), queries and updates on BIT work in 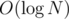 , so we have an algorithm.
, so we have an algorithm.
F. Floating Formation
(diff: hard, code)
Boats are edges, designs are edges. Compress the graph to a tree with its root marked, then keep marking the vertex that has the most unmarked vertices on the path from it to the root. It can be done with preorder numbering and a segment tree.
The input graph has specific form that simplifies stuff a lot — it's connected and has a part that always stays afloat. We can identify this part and compress it into the root of a tree. How? By identifying the part that doesn't stay afloat, and that can be done simply by cutting off leaves of the graph (stored in a queue) and adding their neighbours to the queue if they become leaves.
Now, we have a rooted tree, with only its root marked as "stays afloat". If we connect a boat to its unmarked vertex, that vertex and all on the path from it to the root will also become marked that way. Obviously, we want to connect boats to leaves only; in fact, we want to connect a boat to a deepest vertex (if there are more, any one will do). If we didn't connect a boat to any of the deepest vertices, we could look at the first vertex w on the path from one of them (v) to the root that becomes marked in the end, take a boat from its subtree (connected to u) and connect it to that deepest vertex (v) instead, gaining at least one marked vertex, because we mark all vertices from w to v, unmark at most all vertices from u to w and v must have been deeper than u.
We can connect the first boat to this vertex and mark all vertices on the path from it to the root; this can be done by simply moving along the path until we encounter a previously marked vertex. Where to put the next boat? Again, to the vertex with the most unmarked ones on the path from it to the root (let's call this number "true depth"). The argument is that the cost is the same as if we just took all marked vertices and merged them into the root (we did this at the beginning, remember?), obtaining another tree with all but the root unmarked, which is the same situation as when choosing the vertex for the first boat.
We now have a clear idea of what to do — K times "pick the truly deepest vertex and mark all vertices above it (including itself)". Then, we just need to count unmarked vertices to get the answer. The only question remaining is how to do this.
Marking vertices is straightforward, the only problem is updating true depths and finding the truly deepest vertex. What often helps with this type of problems is renumbering vertices so that each subtree would contain vertices from one interval. For example, with preorder numbering, which can be computed with one DFS — the root gets number 0, its first son gets number 1, then the subtree of the first son is numbered recursively, the second son gets the first unused number, then its subtree is numbered recursively, the 3rd son gets the first unused number again etc. This produces the desired numbering, and updating true depths when vertex v is marked turns into subtracting 1 from all true depths in an interval (corresponding to v's subtree).
So, we need to find the maximum and subtract a constant from an interval. Does that remind you of anything? Yes, maximum interval/segment tree. With lazy updates and able to find the vertex that this maximum belonged to. Lazy propagation is a standard thing, so I won't describe the tree here, but I'll mention that in order to get the vertex, you can keep the maximum of pairs (true depth, corresponding vertex). The time complexity is 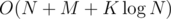 , because all but the query answering/updating takes just linear time and a segment tree can be constructed in O(N).
, because all but the query answering/updating takes just linear time and a segment tree can be constructed in O(N).
G. Growling Gears
(diff: easy, code)
Take the derivative of function F(R), find the optimal R and F.
This is one of the most basic problems in calculus. F(R) is a polynomial, which is differentiable in 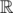 , so its maxima must satisfy
, so its maxima must satisfy
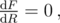
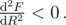
In this case, it means 2aR = b, -2a < 0$. The second rule is always satisfied, the first one has exactly one solution: 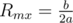 , with the corresponding maximum F(Rmx) = b2 / 4a + c.
, with the corresponding maximum F(Rmx) = b2 / 4a + c.
We want just solutions with R > 0, but in this problem, it's always satisfied.
We get a straightforward O(N) code; doubles are fully sufficient for max. values of F.
H. Highway Hassle
(diff: harder, I'm not sure if "very hard" is accurate)
Lol nope. Look for it down in the comments.
I. Interesting Integers
(diff: medium, code)
N = Gn = Fn - 1b + Fn - 2a; try all reasonable n, solve the equation 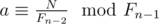 (think why it's equivalent to N=F_{n-1}b+F_{n-2}a$)
(think why it's equivalent to N=F_{n-1}b+F_{n-2}a$)
We know that N = Gn = Fn - 1b + Fn - 2a with F - 1 = 1, F0 = 0 (it's not called a linear recurrence without reason); proof by seeing that it satisfies all conditions it needs to satisfy. For a, b > 0, Gn ≥ Fn and Fibonacci numbers increase quickly, so we can try all n, for which Fn ≤ N holds.
Let's fix n ≥ 3. Modulo Fn - 1, we know that N ≡ Fn - 2a; consecutive Fibonacci numbers are also coprime (easy proof by induction), so Fn - 2 has a modular inverse and
We can precompute Euler's φ of all Fn - 1 ≤ N after factorising them. Then, we can compute the smallest positive a0 that can lead to a good pair (a, b) using fast exponentiation and its respective b0.
We can add any multiple of Fn - 1 to a0 and subtract the same multiple of Fn - 2 from b0 to get all the other pairs (a, b). The largest k, for which a0 + kFn - 1 ≤ b0 - kFn - 2 holds, is 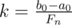 (integer division). If b0 < a0, there's clearly no way to make a good pair (a, b) with this n (a0 must be the smallest possible a here, but we'd try to subtract something from it). Otherwise, the pair corresponding to this k must be good.
(integer division). If b0 < a0, there's clearly no way to make a good pair (a, b) with this n (a0 must be the smallest possible a here, but we'd try to subtract something from it). Otherwise, the pair corresponding to this k must be good.
We just need to pick the optimal one of so found good pairs (a, b). There are possible n-s, each requires  factorisation for φ and exponentiation; all remaining steps are O(1), so we get
factorisation for φ and exponentiation; all remaining steps are O(1), so we get 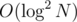 complexity per query with
complexity per query with 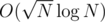 precomputation.
precomputation.
J. Jury Jeopardy
(diff: easy, code)
Trivial simulation of what's described in the statement (walk around the maze and mark cells as empty), just bug-prone. Nothing else to add, you can read my code to understand better.
K. Key to Knowledge
(diff: medium, code)
Meet in the middle, pick one half of correct answers. 3112 < 1018, so a vector can be compressed into a 64-bit integer.
The simplest bruteforce would try all possible combinations of correct answers, count the number of correct answers each student got and decide if it's correct. But that's too slow.
A better solution uses meet-in-the-middle approach. We can bruteforce all combinations of the first 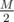 correct answers and count how many of them each student answered correctly, as a vector v of size N. The same can be done for the last
correct answers and count how many of them each student answered correctly, as a vector v of size N. The same can be done for the last 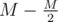 answers, obtaining vectors w of how many answers each student needs to answer correctly in the other half. The answer to the problem is the number of pairs (v, w) with v = w.
answers, obtaining vectors w of how many answers each student needs to answer correctly in the other half. The answer to the problem is the number of pairs (v, w) with v = w.
We could just throw all vectors v into a map<> and compute the answer directly by looping over all w. But to make sure it doesn't TLE, we can convert the vectors into numbers in base M + 1. Since these numbers are at most (M + 1)N ≤ 1018 here, 64-bit integers are sufficient for this representation. Comparing vectors in O(N) now turns into comparing integers in O(1).
There are O(2M / 2) halves of correct answers to check (O(MN)), compress (O(N)) and drill into or search in a map (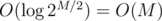 ), so the time for this is O(2M / 2MN).
), so the time for this is O(2M / 2MN).







For problem B, I used the same concept as the popular coin-change problem's DP solution, but I got WA. Please point out the mistake in my solution.
dp[i] represents the minimum no. of buttons pressed to get time i.
If t cannot be made from given buttons, pick i, such that i > t and getting time i is possible, i.e. no. of buttons = dp[i].
Else ans = dp[t].
Negative integers on the input, probably.
i think problem A can be done with mincost-maxflow but i don't know if it will give TLE, am i right ?
Depends on implementation, probably. Also, the time limit is 6 seconds, which is quite a lot, the graph is very sparse (M ≤ 1000, N ≤ 1000) and most test cases are probably small or give a smaller flow (Ford-Fulkerson is O(edges * answer)).
What does H involve, why is it so hard ? Great work as usual, btw.
tourist didn't solve it during contest, so it has to be hard :D
Dunno, I found their presentation of solutions and I'll try to figure out why the one for H works in time.
is dinic slower than Ford-Fulkerson in problem A ? because complexity of dinic doesn't depend on the answer(max flow) , while Ford does
Our solution to problem H:
First, precompute the shortest paths between all pairs of critical points (plus the start and end). Then, run shortest path on a graph where each node represents the following triplet: 1. Current position 2. Boolean indicating whether or not you filled up at the last station you were at 3. Last station you were at (only include this part if you filled up there) Then, from each node, try all possible next stations to go to. Runtime is about O(n^3*log(n)) with Dijkstra's, where n <= 120.
Is there any way to solve problem E with more than 3 categories?