


We would like to thank the testers of this round's and Winter Computer Camp olympiad's problems: alger95, thefacetakt, adamant, -imc-, riskingh, ASverdlov.
Make sure to comment if you find any mistakes.
UPD: I've just remembered to put up the usual challenges for the problems. So, here they go.
Idea: Endagorion
Preparation: Endagorion
To check that every letter is present in the string we can just make a boolean array of size 26 and for every letter set the corresponding variable to TRUE. In the end check that there are 26 TRUEs. That is an O(n) solution. Also don't forget to change all letters to lowercase (or all to uppercase).
To make all the letters lowercase, one could use standard functions, like tolower in Python. Also, it is known that the letters from a to z have consecutive ASCII numbers, as well as A to Z; an ASCII number of symbol is ord(c) in most languages. So, to get the number of a lowercase letter in the alphabet one can use ord(c) - ord('a') in most languages, or simply c - 'a' in C++ or C (because a char in C/C++ can be treated as a number); to check if a letter is lowercase, the inequality ord('a') <= ord(c) && ord(c) <= ord('z') should be checked.
Challenge: how many pangrams of length n are there? Strings that differ only in capitalization of some letters are considered distinct. Can you find the answer modulo some prime p in linear time?
Idea: Endagorion
Preparation: Endagorion
The simplest solution is simply doing a breadth-first search. Construct a graph with numbers as vertices and edges leading from one number to another if an operation can be made to change one number to the other. We may note that it is never reasonable to make the number larger than 2m, so under provided limitations the graph will contain at most 2·104 vertices and 4·104 edges, and the BFS should work real fast.
There is, however, an even faster solution. The problem can be reversed as follows: we should get the number n starting from m using the operations "add 1 to the number" and "divide the number by 2 if it is even".
Suppose that at some point we perform two operations of type 1 and then one operation of type 2; but in this case one operation of type 2 and one operation of type 1 would lead to the same result, and the sequence would contain less operations then before. That reasoning implies that in an optimal answer more than one consecutive operation of type 1 is possible only if no operations of type 2 follow, that is, the only situation where it makes sense is when n is smaller than m and we just need to make it large enough. Under this constraint, there is the only correct sequence of moves: if n is smaller than m, we just add 1 until they become equal; else we divide n by 2 if it is even, or add 1 and then divide by 2 if it is odd. The length of this sequence can be found in  .
.
Challenge: suppose we have a generalized problem: we want to get n starting from m using two operations "subtract a" and "multiply by b". Generalize the solution to find the minimal number of moves to get from n to m in time if a and b are coprime. Can you do it if a and b may have common divisors greater than 1?
520C - DNA Alignment/521A - DNA Alignment
Idea: Endagorion
Preparation: Endagorion
What is ρ(s, t) equal to? For every character of s and every character of t there is a unique cyclic shift of t that superposes these characters (indeed, after 0, ..., n - 1 shifts the character in t occupies different positions, and one of them matches the one of the character of s); therefore, there exist n cyclic shifts of s and t that superpose these characters (the situation is symmetrical for every position of the character of s). It follows that the input in ρ from a single character ti is equal to n × (the number of characters in s equal to ti). Therefore, ρ(s, t) is maximal when every character of t occurs the maximal possible number of times in s. Simply count the number of occurences for every type of characters; the answer is Kn, where K is the number of character types that occur in s most frequently. This is an O(n) solution.
Challenge: we know that ρmax(s) = n2·C(s), where C(s) is the maximal number that any character occurs in s. How many strings s of length n with characters from an alphabet of size k have C(s) = m? Can you find an O(kn2) solution? An 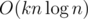 solution? An
solution? An 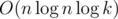 solution? Maybe even better? (Hint: the modulo should be an appropriately chosen prime number for a fast solution =)).
solution? Maybe even better? (Hint: the modulo should be an appropriately chosen prime number for a fast solution =)).
Idea: savinov
Preparation: savinov, sokian, zemen
Basically, the first player should maximize the lexicographical order of numbers, and the second player should minimize it. Thus, at every move the first player should choose the largest available number, and the second should choose the minimal one.
First of all, how do we check if the cube can be removed? It is impossible only if there is some cube "supported" by it (i.e., it has coordinates (x - 1, y + 1), (x, y + 1), (x + 1, y + 1)) such that our cube is the only one supporting it. This can be checked explicitly. The large coordinates' limitations do not allow us to store a simply array for that, so we should use an associative array, like a set in C++.
Now we should find the maximal/minimal number that can be removed. A simple linear search won't work fast enough, so we store another data structure containing all numbers available to remove; the structure should allow inserting, erasing and finding global minimum/maximum, so the set C++ structure fits again.
When we've made our move, some cubes may have become available or unavailable to remove. However, there is an O(1) amount of cubes we have to recheck and possibly insert/erase from our structure: the cubes (x ± 1, y) and (x ± 2, y) may have become unavailable because some higher cube has become dangerous (that is, there is a single cube supporting it), and some of the cubes (x - 1, y - 1), (x, y - 1) and (x + 1, y - 1) may have become available because our cube was the only dangerous cube that it has been supporting. Anyway, a simple recheck for these cubes will handle all the cases.
This solution is  if using the appropriate data structure.
if using the appropriate data structure.
Challenge (inspired by questions from jk_qq and RetiredAmrMahmoud): suppose that the players put the numbers from right to left, that is, from the least significant digit to the most significant. The first player still wants to maximize the resulting number, and the second wants to minimize it. If the original rules of taking cubes apply, finding the optimal strategy for the players seems intractable. Try to solve this problem in the case where all the cubes are stacked in several independent towers; that is, a cube may only be taken from the top of any tower.
520E - Pluses everywhere/521C - Pluses everywhere
Idea: Endagorion
Preparation: gchebanov, DPR-pavlin
Consider some way of placing all the pluses, and a single digit di (digits in the string are numbered starting from 0 from left to right). This digit gives input of di·10l to the total sum, where l is the distance to the nearest plus from the right, or to the end of string if there are no pluses there. If we sum up these quantities for all digits and all ways of placing the pluses, we will obtain the answer.
For a given digit di and some fixed l, how many ways are there to place the pluses? First of all, consider the case when the part containing the digit di is not last, that is, i + l < n - 1. There are n - 1 gaps to place pluses in total; the constraint about di and the distance l means that after digits di, ..., di + l - 1 there are no pluses, while after the digit di + l there should be a plus. That is, the string should look as follows:
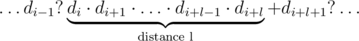
Here a dot means a gap without a plus, and a question mark means that it's not important whether there is a plus or not. So, out of n - 1 possible gaps there are l + 1 gaps which states are defined, and there is one plus used in these gaps. That means that the other (n - 1) - (l + 1) = n - l - 2 gaps may contain k - 1 pluses in any possible way; that is, the number of such placements is 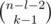 . A similar reasoning implies that if the digit di is in the last part, that is, i + l = n - 1, the number of placements is
. A similar reasoning implies that if the digit di is in the last part, that is, i + l = n - 1, the number of placements is 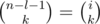 .
.
To sum up, the total answer is equal to
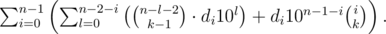
Let us transform the sum:
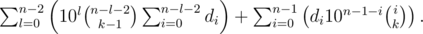
To compute these sums, we will need to know all powers of 10 up to n-th (modulo 109 + 7), along with the binomial coefficients. To compute the binomials, recall that 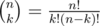 , so it is enough to know all the numbers k! for k upto n, along with their modular inverses. Also we should use the prefix sums of di, that is, the array
, so it is enough to know all the numbers k! for k upto n, along with their modular inverses. Also we should use the prefix sums of di, that is, the array 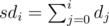 . The rest is simple evaluation of the above sums.
. The rest is simple evaluation of the above sums.
The total complexity is 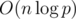 , because the common algorithms for modular inverses (that is, Ferma's little theorem exponentiation or solving a diophantine equation using the Euclid's algorithm) have theoritcal worst-case complexity of
, because the common algorithms for modular inverses (that is, Ferma's little theorem exponentiation or solving a diophantine equation using the Euclid's algorithm) have theoritcal worst-case complexity of 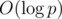 . However, one can utilize a neat trick for finding modular inverses for first n consecutive numbers in linear time for a total complexity of O(n); for the description of the method refer to this comment by Kaban-5 (not sure why it has a negative rating, I found this quite insightful; maybe anyone can give a proper source for this method?).
. However, one can utilize a neat trick for finding modular inverses for first n consecutive numbers in linear time for a total complexity of O(n); for the description of the method refer to this comment by Kaban-5 (not sure why it has a negative rating, I found this quite insightful; maybe anyone can give a proper source for this method?).
Challenge: now we want to find the sum of all expressions that are made by placing k pluses with a ≤ k ≤ b; that is, we want to find the sum of the answers for the original problem with k = a, ..., b; here a and b can be any integers with 0 ≤ a ≤ b ≤ n - 1. There is an obvious O(n2) solution: just find the answers for all k separately. Can you find a linear solution?
Idea: Endagorion
Preparation: gchebanov
Suppose the only type of upgrades we have is multiplication. It doesn't even matter for the answer which particular skill we are going to multiply, so we just choose several upgrades with greatest values of bi.
Now we have additions as well; set multiplications aside for a moment. It is clear that for every skill we should choose several largest additions (maybe none). Let us sort the additions for every skill by non-increasing; now we should choose several first upgrades for each type. Now, for some skill the (non-increasing) sorted row of b's is b1, ..., bl, and the initial value of the skill is a. Now, as we have decided to take some prefix of b's, we know that if we take the upgrade bi, the value changes from a + b1 + ... + bi - 1 to a + b1 + ... + bi - 1 + bi. That is, the ratio by which the value (and the whole product of values) is going to be multiplied by is the fraction 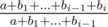 . Now, with that ratio determined unambigiously for each addition upgrade, every addition has actually become a multiplication. =) So we have to compute the ratios for all additions (that is, we sort b's for each skill separately and find the fractions), and then sort the multiplications and additions altogether by the ratio they affect the whole product with. Clearly, all multiplications should be used after all the additions are done; that is, to choose which upgrades we use we should do the ratio sorting, but the order of actual using of upgrades is: first do all the additions, then do all the multiplications.
. Now, with that ratio determined unambigiously for each addition upgrade, every addition has actually become a multiplication. =) So we have to compute the ratios for all additions (that is, we sort b's for each skill separately and find the fractions), and then sort the multiplications and additions altogether by the ratio they affect the whole product with. Clearly, all multiplications should be used after all the additions are done; that is, to choose which upgrades we use we should do the ratio sorting, but the order of actual using of upgrades is: first do all the additions, then do all the multiplications.
Finally, let's deal with the assignment upgrades. Clearly, for each skill at most one assignment upgrade should be used, and if it used, it should the assignment upgrade with the largest b among all assignments for this skill. Also, if the assignment is used, it should be used before all the additions and multiplications for this skill. So, for each skill we should simply determine whether we use the largest assignment for this skill or not. However, if we use the assignment, the ratios for the additions of current skill become invalid as the starting value of a is altered.
To deal with this problem, imagine that we have first chosen some addition upgrades, and now we have to choose whether we use the assignment upgrade or not. If we do, the value of the skill changes from a + b1 + ... + bk to b + b1 + ... + bk. That is, the assignment here behaves pretty much the same way as the addition of b - a. The only difference is that once we have chosen to use the assignment, we should put it before all the additions.
That is, all largest assigments for each skill should be made into additions of b - a and processed along with all the other additions, which are, as we already know, going to become multiplications in the end. =)
Finally, the problem is reduced to sorting the ratios for all upgrades. Let us estimate the numbers in the fractions. The ratio for a multiplication is an integer up to 106; the ratio for an addition is a fraction of general form 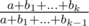 . As k can be up to 105, and bi is up to 106, the numerator and denominator of such fraction can go up to 1011. To compare fractions
. As k can be up to 105, and bi is up to 106, the numerator and denominator of such fraction can go up to 1011. To compare fractions  and
and  we should compare the products ad and bc, which can go up to 1022 by our estimates. That, unfortunately, overflows built-in integer types in most languages. However, this problem can be solved by subtracting 1 from all ratios (which clearly does not change the order of ratios), so that the additions' ratios will look like
we should compare the products ad and bc, which can go up to 1022 by our estimates. That, unfortunately, overflows built-in integer types in most languages. However, this problem can be solved by subtracting 1 from all ratios (which clearly does not change the order of ratios), so that the additions' ratios will look like 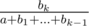 . Now, the numerator is up to 106, the products in the comparison are up to 1017, which fits in 64-bit integer type in any language.
. Now, the numerator is up to 106, the products in the comparison are up to 1017, which fits in 64-bit integer type in any language.
Challenge: suppose that you have to compare two fractions and , where a, b, c, d may be up to 1018. What way would you use to do that? Can you find a simple solution that does not involve long arithmetics, floating-point number or magic built-in integer types tricks (but may perform a non-constant number of operations)?
Idea: Endagorion
Preparation: Endagorion
We have to find two vertices in an undirected graph such that there exist three vertex- and edge-independent paths between them. This could easily be a flow problem if not for the large constraints.
First of all, we can notice that all the paths between vertices should lie in the same biconnected component of the graph. Indeed, for every simple cycle all of its edges should lie in the same biconnected component, and the three-paths system is a union of cycles. Thus, we can find all the biconnected components of the graph and try to solve the problem for each of them independently. The computing of biconnected components can be done in linear time; a neat algorithm for doing this is described in the Wikipedia article by the link above.
Now, we have a biconnected component and the same problem as before. First of all, find any cycle in this component (with a simple DFS); the only case of a biconnected component that does not contain a cycle is a single edge, which is of no interest. Suppose that no vertex of this cycle has an adjacent edge that doesn't lie in the cycle; this means the cycle is not connected to anything else in the component, so the component is this cycle itself, in which case there is clearly no solution.
Otherwise, find a vertex v with an adjacent edge e that doesn't lie in the cycle (denote it c). If we can find a path p starting with e that arrives at a cycle vertex u (different from v), then we can find three vertex-distinct paths between v and u: one path is p, and two others are halves of the initial cycle. To find p, start a DFS from the edge e that halts when it arrives to vertex of c (that is different from v) and recovers all the paths.
What if we find that no appropriate path p exists? Denote C the component traversed by the latter DFS. The DFS did not find any path between vertices of C\ {v} and c\ {v}, therefore every such path should pass through v. That means that upon deletion of v, the component C\ {v} becomes separated from all vertices of c\ {v}, which contradicts with the assumption that the component was biconnected. That reasoning proves that the DFS starting from e will always find the path p and find the answer if only a biconnected component was not a cycle nor a single edge.
Finally, we obtain that the only case when the answer is non-existent is when all the biconnected components are single edges or simple cycles, that is, the graph is a union of disconnected cactuses. Otherwise, a couple of DFS are sure to find three vertex-disjoint paths. This yields an O(n + m) solution; a few logarithmic factors for simplification here and there are also allowed.
Challenge: how many graphs G on n labeled vertices exist such that there exist two vertices of G connected by three disjoint paths? (Hint: we have already shown that it suffices to count the number of disjoint unions of cacti.) Find the answer modulo 109 + 7. Can you come up with any polynomial-time solution? An O(n3) solution? Maybe even better?






Is it possible to do Div 2 B using dynamic programming? I tried to implement this however kept encountering errors, which partially might be because I am getting stuck in some sort of infinite loop of say going from 1 -> 2 -> 1 over and over. However even after I thought I fixed that I still had problems. The two approaches described here in the editorial are obviously better now I see, but I am wondering if anybody successfully implemented a dynamic programming solution, as I would like to understand if this is possible, and if not why this is so? Thanks!
I had a terrible issue with the order of the operations, so I reach the dp[n] with an incorrect timing (amount of steps) then all the calculations from there where straight to hell, my implementation was basically dfs.
Hello =)
I tried DP at first but it gave me wrong answer because I didn't handle the cases like "9999 10000" which the answer is 5000.
But I tried the backwards solution (recently) and got AC:10125859
Dp solution:
codeforces.com/contest/520/submission/10109529
I don't know about a DP solution but a fairly simple recurrence gives the right answer.
I think this is O(log(n)) but still working on Endagorion's challenge to generalizing it for subtract a and multiply b type of operations. Any further hints Endagorion ?
Well, basically the editorial contains everything you need. The case when a and b are coprime seems somewhat easier to handle. =)
For Div-1 C / Div-2 E, I first learned the O(n) modulo inverse computation from rng_58's solution in the TCO10 finals: http://community.topcoder.com/stat?c=problem_solution&rm=306085&rd=14287&pm=11061&cr=22692969
Here's the implementation :)
Can problem B Div-1 be solved if the number was constructed from the right to the left?
520B - Two Buttons I know that turning m into n is easier than the opposite, but why is this code wrong? Can you give me any easy counterexample?
5 11
Correct solution:
5->4->3->6->12->11 — 5 steps
Your solution:
5->10->9->8->7->6->12->11 — 8 steps
You are wrongly assuming that if n is 2 times or more smaller than m it is worth everytime to multiplky n by 2. Look at the example. Even though you quickly got to 10 which is so close to 11 you then have to subtract one so many times that it becomes inefficient. Intuitevely it is better and faster to get to 3 first, because difference between 5 and 3 is small, as they are are small numbers and then multiplyinyg that 3 by two will quickly get you to 12 — closest even number to 11.
Yeah, you are right! Do you think it is possible to solve this problem converting n into m?
Possible but tough!
missing the challenge part like the previous editorials of Endagorion
Ah, yes, I knew I forgot something. I'll put them up shortly, stay tuned.
Can anynone explain the fast solution of the div 2 b problem with an example ??
Its quite simple . First understand if m<n then ans is n-m
else
make m less than or equal to n by dividing it by 2 , increase the count by one and if at any moment it becomes odd increase the count by 1 and increase m by 1 . e.g
4 17
1. 17->18
2. 18->9
3. 9->10
4. 10->5
5. 5->6
6. 6->3
then 3 is smaller than 4 so ans is 6+(4-3) = 7
nyways take a look at my solution 10105430 . Its quite easy to understand .
how can we approch this problem by using graph
can anybody find mistake in my solution of 521C - Pluses everywhere? it doesn't come through the 10 test :/ and i'm out of guesses now
Here is my code http://pastebin.com/aH1u9vmv (updated, now commented) sorry for my horrible english
Same here, hope somebody would help.
Never mind, it was a simple bug in my nCr function :S
Is it still possible to solve problem 1B/2D, if we allow same number appearing multiple times?
Div1D challenge:
This should be correct up to den=0 and maybe some negative values, but it's not a code I will use, so details are left to the reader, it's just a main idea :P.
Best problem E ever in Codeforces. No any complex ideas but very very very insightful
Div1C challenge:
Consider i-th position:
amount of expressions consisting ai with multiplier 100: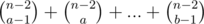 ,
,
with 101: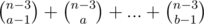 ,
,
...
with 10n - i - 1: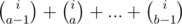 ,
,
with 10n - i: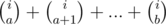 .
.
One should compute this numbers and it's prefix sums only ones.
The main task is calculating for all n ≤ 105 and few number of k.
for all n ≤ 105 and few number of k.
This can be done in linear time for each k:
Yup, that's it.
CUBES: What is so particular with test case 19 ?? For all previous tests my code (java) runs below 500 ms . And I get timed out for test 19...
Maybe it is something like anti-java-hashmap test.
My current code doesn't use HashMap. I do some sorting and binarySearch at the begining to initialise my data structure. After,I use a PriorityQueue, but with Integer objects (the objects beeing the value of the cube). It's annoying me...
I used two priority queues. I replaced by one TreeSet. That changed performance on test19....
Thanks you, I get this error too and after change from PriorityQueue to TreeSet the performance is better and I get AC. It's seem the operator add in TreeSet better PriorityQueue in this case.
I dont understand how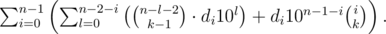 becomes
becomes 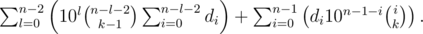
Please can anyone explain?
The first part of the sum: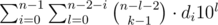 =
= 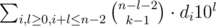 =
= 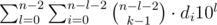 =
= 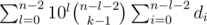 . The second part stay the same.
. The second part stay the same.
Is that any more transparent?
Thanks Endagorion. I got it.
:)
Excuse me, someone can explain Div D example test case, I don't understand this line: "assign the i-th skill to b;"
Can anyone please explain the challenge of Div 2 C/ Div 1 A(DNA Alignment).
Isn't the challenge for A just the number of surjections {1, 2, ..., n} → {'a', ...'z'}?
Note that n, m, k are all independent parameters.
520A Challenge: Would (26 * n) be considered a linear time?
What about a dp with index and count of distinct lower-case characters that showed up till now? Time: 26 * n. Memory: if converted to a loop, would be something like 26 or 2 * 26.
Edit: Of course, there's some memoization and modding.
can any one please tell me the generalize solution of Div2 B problem , when instead of 2 and 1 , a and b are given ?
wow, I only know better algorithm solving B problems after reading this post
Hi, I'm having trouble understanding why my code fails on test 4 of D2D. Here is my solution which swaps 4 and 6 in the 4th test for some odd reason. I'd appreciate the help! Thanks.
Submission Link
EDIT: Nvm I found the issue, I didn't exclude values after updating.
520B — Two Buttons I found an elegant solution after looking through the confusing editorial. The algorithm with complexity O(log m + Δ), where Δ is a difference between m and n.
My code here
Feel free to leave any feedback.