


I know that when we union 2 sets we compare the ranks of the representatives of the 2 sets and we put the smaller one inside the bigger one to ensure better complexity.
But the thing I don't understand is that why we don't update the rank when we do the find operation??
Actually when we do find we change lots of pointers and this changes actually the biggest depth of the set and correspondingly the rank of it. However the implementations I have seen doesn't change the rank while doing the find operation.
I have looked at Competitive Programming 3 implementation and the wikipedia implementation and both doesn't change the rank while finding.







The rank of a set should be its size, not its maximum depth.
This means that the codes I found is buggy??
Because the only place he changes the rank in the CP3 code is in the union function and he changes it when he has to union 2 sets which have the same rank and he only increments the new parent rank.
What you said means that he should not increment it and he should add the rank of the other set to it.
But in that case he should also change ranks while finding because there are intermediate sets which are not representatives anymore but they have a rank and it should be decreased.
Am I wrong about that?
Although using the size of a set as its' rank makes complexity better and I see this in many codes, but I think the main idea for rank, refers to the maximum depth of a set.
The rank is not the height of a tree. It's rather an upper bound for the height of a tree.
Why is the rank used instead of the height? When you perform a find operation with path compression the height of a tree may or may not change. It seems it's too difficult to update the heights. Luckily using the rank instead of the height does not have any negative effects. On the contrary, Tarjan showed that using union by rank and path compression leads to an amazing amortized runtime of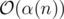 per operation which is effectively constant.
per operation which is effectively constant.