


Somehow I don't feel sleepy at all at 6am, which is kinda weird. I wonder if writing an editorial will help.
SquareScores (250)
The standard trick is to use the linearity of expectation: for every substring count the probability that it consists of the same characters, and sums all these probabilities. There are O(n2) substrings, which is a reasonable amount in the given limitations. However, iterating over all symbols in the substring yields O(n3) solution, so we should optimize something.
My way was as follows: fix the beginning of the substring, and process all substrings with this beginning altogether. Count qc — the probability that current substring consists only of characters c. If we append one symbol from the right, qc changes in a simple way: if the symbol is a letter x, then all qc with c ≠ x become zeros, while qx does not change; else, if the symbol is question mark, every qc gets multiplies by pc. So, we process all substrings with fixed beginning in O(mn) (where m is the number of different symbols), for a O(mn2) solution.
Do you have a more effective/simple solution for this problem?
SuccessiveSubstraction (450)
When we open all the brackets, every number adds up with a plus or a minus sign by it. Which configurations are possible? It is not difficult to prove that all possible configurations are as follows: the first number is always a plus, the second is always a minus, while all other numbers with a plus sign form no more than two consecutive segments. So, we just have to find two subsegments of the array with the greatest total sum. There are lots of ways to do it in O(n), the most straightforward (IMO) being DP (how many elements are processed; the number of consecutive segments already closed; is a segment currently open). Simply recalculate the DP after every change in the array, for a solution of O(n2) complexity.
TwoEntrances (850)
What if there is only one entrance in the tree? The problem becomes a classic one: count the number of topological orderings of rooted tree with edges directed from the root. There is a simple subtree DP solution; also, a closed formula is available: 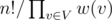 , where n is the total number of vertices, w(v) is the number of vertices in the subtree of v.
, where n is the total number of vertices, w(v) is the number of vertices in the subtree of v.
Now, two entrances s1 and s2 are present. Consider vertices that lie on the path connecting s1 and s2 in a tree; every vertex of the path can be associated with a subtree consisting of vertices not on the path. The last vertex to cover will be either s1 or s2 (WLOG, assume it's s1), the second-to-last will be either s2 or the neighbour of s1 in the path, etc. The observation is that at any moment there is a consecutive subsegment of the s1-s2 path which is covered.
Count dpl, r — the number of ways to cover the subsegment from l-th to r-th vertex in the path with all the hanging subtrees. The number of ways such that the l-th vertex is the last to cover is 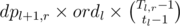 , where ordl is the number of topological orderings of the subtree of l-th vertex (which can be calculated as described above), tl is the size of this subtree, and Tl, r is the total number of vertices in the subtrees of l-th, ..., r-th vertices. The intuition behind this formula is that we independently deal with the segment [l + 1;r] and the l-th subtree, and the last vertex is always the l-th vertex of the path. The number of ways that cover r-th vertex in the last place is obtained symmetrically; dpl, r is simply the sum of those two quantities. The base of DP is clearly dpl, l = ordl.
, where ordl is the number of topological orderings of the subtree of l-th vertex (which can be calculated as described above), tl is the size of this subtree, and Tl, r is the total number of vertices in the subtrees of l-th, ..., r-th vertices. The intuition behind this formula is that we independently deal with the segment [l + 1;r] and the l-th subtree, and the last vertex is always the l-th vertex of the path. The number of ways that cover r-th vertex in the last place is obtained symmetrically; dpl, r is simply the sum of those two quantities. The base of DP is clearly dpl, l = ordl.
Clearly, this subsegment DP is calculated in O(n2), with all the preliminaries being simple DFS'es and combinatorial primitives which also can be done in O(n2).






OIerRobbin in my room coded a different solution to 450, which I think is quite cool.
He finds the maximum consecutive segment in the data, inverts signs on that segment and then simply finds the maximum consecutive segment again. In case he finds two overlapping segments that way, it is still a valid solution, since one could achieve the same result by choosing two non-overlapping parts.
How do we care about vertices in subtrees rooted not in [l,r]? We can partially fill some of them.