


550A - Две подстроки
Задачу можно решать разными способами. Авторское решение такое: проверим две возможности — когда подстрока "AB" идет первее "BA" и наоборот. Проверять можно следующим образом: найти самое первое вхождение "AB" в исходной строке и рассмотреть подстроки длины 2 правее. Если среди них встретилась подстрока "BA" — ответ "YES". Аналогично проверяется второй случай. Если оба варианта не выполнены, ответ "NO". Сложность решения — O(n), где n — длина исходной строки.
550B - Подготовка олимпиады
Задачу можно решить полным перебором всех подмножеств задач (всего 2n подмножеств). Для каждого из подмножеств проверим, удовлетворяет ли оно условиям задачи. Найдем сумму сложностей всех задач, входящих в подмножество, и убедимся, что она лежит в отрезке [l, r]. Найдем также разность между сложностями максимально сложной задачи и минимально сложной задача подмножества и убедимся, что она не менее x. Если подмножество задач удовлетворяет условиям — увеличиваем общий ответ на 1. Сложность решения задачи — O(2n·n).
550C - Делимость на восемь
Задачу можно решить как минимум двумя способами.
Первый — через "школьный" признак делимости на 8 (число делится на 8 тогда и только тогда, когда число, образованное его последними тремя цифрами, делится на 8). Таким образом, достаточно проверять на делимость на 8 все однозначные, двухзначные и трехзначные числа, образуемые из исходного вычеркиванием цифр. Это можно сделать за O(n3) вложенными циклами по цифрам числа, где n — количество цифр числа.
Второй способ использует динамическое программирование. Будем считать величину dp[i][j], 1 ≤ i ≤ n, 0 ≤ j < 8 — величину, равную 1, если из префикса числа длиной i цифр можно вычеркнуть несколько цифр так, что остаток от деления полученного числа на 8 равен j, и 0 в противном случае. Формулы для пересчета: пусть i-я цифра числа есть ai, тогда dp[i][aimod8] = 1 (по смыслу — однозначные числа), dp[i][(j * 10 + ai)mod8] = max(dp[i][(j * 10 + ai)mod8], dp[i - 1][j]) (по смыслу — дописывание текущей цифры), dp[i][j] = max(dp[i][j], dp[i - 1][j]) (по смыслу — вычеркивание текущей цифры), где 0 ≤ j < 8. Ответ "YES" будет в том случае, когда для некоторого i выполнено dp[i][0] = 1. Для восстановления ответа также нужно завести дополнительный массив prev[i][j], который будет хранить индекс k такой, что при подсчете dp[i][j] пересчет был сделан из dp[i - 1][k]. Сложность такого решения — O(8·n).
Решение с динамическим программированием:
550D - Регулярный мост
Докажем, что если k — четное, то решения не существует. Пусть наш граф содержит мост(ы), k = 2s — четное число, степени всех вершин графа равны k. Дерево двусвязных (реберно двусвязных, далее слово "реберных" будет опущено для краткости) компонент исходного графа содержало компоненту, связанную с остальной частью графа только одним мостом (не несколькими мостами!) (на самом деле таких компонент как минимум две, но нам достаточно одной).
Рассмотрим эту компоненту. Удалим мост, связывающий ее с остальной частью графа. Тогда в ней будет всего одна вершина степени k - 1 = 2s - 1 и какое-то количество вершин степени k = 2s. Но тогда она будет содержать только одну вершину нечетной степени, что невозможно.
Построим такой граф для нечетных k. Пусть k = 2s - 1 — нечетное число. Рассмотрим отдельно случай k = 1, тогда, очевидно, подойдет дерево из двух вершин.
Для k ≥ 3 сперва найдем минимальное количество вершин искомого графа. Граф будет содержать как минимум один мост и как минимум две двусвязные компоненты, связанные с остальной частью графа одним мостом. Каждая из этих компонент содержит не менее k + 2 вершин (так как одна вершина связана k - 1 ребрами с другими, остальные имеют степень k = 2s - 1 — нечетное число, т.. количество этих вершин должно быть четным, в то же время оно не может быть меньше k = 2s - 1, то есть оно будет не меньше k + 1, что в сумме с одной вершиной степени k - 1 даст k + 2).
Следовательно, во всем графе будет не менее 2k + 4 вершин. Построим граф с таким количеством вершин.
Занумеруем вершины первой компоненты с 1 до k + 2, вторую компоненту построим аналогично первой. Пусть вершина 1 связана мостом с второй компонентой. Соединим ее k - 1 ребрами с вершинами 2, 3, ..., k. Вершины с номерами 2, 3, ..., k соединим между собой попарно и потом между каждой соседней парой, например 2 - 3, 4 - 5, ... (k - 1) - k, выкинем ребро. После соединим вершины 2, 3, ..., k с вершинами k + 1 и k + 2. Также соединим вершины k + 1 и k + 2 между собой. Тогда все вершины компоненты, кроме первой, будут иметь степень k. Точно так же создаем вторую компоненту и соединяем мостом с первой. Искомый граф построен и содержит O(k) вершин и O(k2) ребер.
Асимптотика решения — O(k2).
550E - Скобки в импликациях
Пусть дано выражение 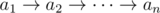 , ai — 0 или 1 для всех i.
, ai — 0 или 1 для всех i.
Покажем, что решения нет только в двух случаях.
1) an = 1.
Это следует из того, что 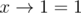 , т. е. никакая расстановка скобок не сможет заменить самую правую 1 выражения на 0.
, т. е. никакая расстановка скобок не сможет заменить самую правую 1 выражения на 0.
2) Выражение имеет вид  или является его суффиксом, содержащим не менее 2 аргументов.
или является его суффиксом, содержащим не менее 2 аргументов.
Это несложно доказать индукцией. Для суффикса  невозможность расстановки скобок очевидна, для более длинных суффиксов любая свертка импликаций либо приведет к тому, что справа появится 1, либо уменьшит число единиц в выражении на 1.
невозможность расстановки скобок очевидна, для более длинных суффиксов любая свертка импликаций либо приведет к тому, что справа появится 1, либо уменьшит число единиц в выражении на 1.
Покажем, что в остальных случаях решение есть.
1) Для выражения 0 ничего делать не надо — ответ 0.
2) Выражение вида 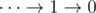 . Можно не расставлять никаких скобок, так как значение такого выражения без скобок равно 0.
. Можно не расставлять никаких скобок, так как значение такого выражения без скобок равно 0.
3) Выражение вида  , где вторая опущенная часть состоит только из единиц. Тогда
, где вторая опущенная часть состоит только из единиц. Тогда  .
.
Асимптотика: O(n).






please correct the format of problem C editorial,, it seems print the date
Thank you!
Problem C is very easy. Don't need Dp
yes, it has explained in this editorial
Oh. yes. I'm sorry :D
Can someone tell me why my A got TLE? : http://codeforces.com/contest/550/submission/11420305
I used Regexp in Ruby.
https://swtch.com/~rsc/regexp/regexp1.html. I think Regexp has a exponential running time as mentioned in this post. Also from the post :- "Perl, PCRE, Python, and Ruby are all using recursive backtracking". Hope it helps.
Do you mean bi-connected component by strongly connected component? If not, what is a strongly connected component in an undirected graph, I tried to google it and found nothing :)
Me too, I don't understand why there is a strongly connected component in undirected graph.
no bi connected components are different . Suppose you have a undirected tree then it is strongly connected but not biconnected. Biconnected components means there are always atleast two edge disjoint path between any pair of vertices in the component. It means there is no bridge in that component.
Good to know about biconnected. So what does strongly connected mean?
in the bottom of the explanation for C there is a O(8·len). but i think that in the big O notation you shouldn't write constants.
Yes, you are right. It's written in such a way to show that if you have the same problem with some d instead of 8, you can solve it in O(d·len).
Hey!
For problem C, can you please explain the method to restore the answer using prev[i][j] in its DP solution?
You should calculate it when you are finding DP: for example,
When you are printing answer, you may do it recursively, like
Thank you for your reply. I have one more confusion though.
When we cross out the 'i'th digit (i.e when we do not consider it), why is the DP equation : dp[i][(j * 10) % 8] ?
I mean, why are we doing (j*10)%8 ? Why not just leave it as it is, because we are crossing out the ith digit?
Should it not be like below.?
if (dp[i — 1][j] == 1 && dp[i][j] == 0){ dp[i][j] = 1; }
Yes, you are right, it should be j instead of j mod 10 in dp and prev. Thanks!
Excuse me, could you explain to me the first if? :
How can we calculate
when we know
I really don't understand although read editorial 3 times.
Thank you very much indeed.
dp[i][j] states if it's possible to achieve the remainder j by using upto i numbers. So, if we include the a[i], the new remainder can be calculated as (j*10 + a[i])%8. You can read the editorial of 490C - Hacking Cypher which uses the similar approach in calculating remainder.
Hello anh NGUYEN_THANH_LOI =)) Up to now, have you understand that? :v
=)) Who are you?
Your recursive_print(i,j) function is so clever. But i think your code has a bit trouble. Timur_Sitdikov For the cases, you take the number a[i] but it doesn't change the module 8, you must set prev[i][mod] = mod, so your recursive_print will work well.
Isn't it written in my listing on lines below (from 7th to 10th)?
Or I misunderstood you?
Thank you, i don't miss your code (from 7th to 10th). Your code takes at least at possible digits to catch the goal, and i think by the way at most at possible, so only if
dp[i-1][j] == 1, not evendp[i][(10*j+a[i]] != 0, i take thea[i]digit. Thanks to your reply, I understand completely your ideal. Thanks a lot!Actually O(8*len) = O(len). It's not necessary to write the constant, but you can.
Seems Codeforces has new feature: autocomment about post changes. Please ignore this comment.
The idea was not to edit such auto-comments so that everybody ignore them =) I guess we'll remove the option of editing auto-comments.
In problem C, I think the first approach can be better than O(len^3), O(125*len) can bee achieved, check 11430246
hey can someone explain how people solved B without using recursion ?
You can solve it by Bitmasking. You can Refer [my solution].(http://codeforces.com/contest/550/submission/11425633)
Here is my solution (it doesn't use recursion): 11424247
Each set of problems corresponds to a binary number. For example, if we had 5 problems total, then the number 10101 would represent a set containing problems 1, 3, and 5.
Because of this, we can just count from 0 to 2n in binary and test every possible subset.
Use the first n bits of an int mask to represent a subset. If the i-th bit is on, then it means the i-th element is in the the subset. Just iterate the mask from 1 to 2^n — 1.
Read this tutorial on how to find the power set of a set. POWER SET
http://codeforces.com/contest/550/submission/11421622
In problem D, how did you come up with the magic figure of 2k+4?? Can you provide any intuition for that?
Actually it is the minimum needed number of nodes (we thought about requiring it, but agreed it would be too hard).
I or Timur will post the proof later, if you want it and won't come up with it yourself :)
Hi
Please post explanation if possible.
Hi. Actually I just noticed that this proof is available in the Russian version of editorial :)
Here is the translation:
For k ≥ 3 let's find minimum number of nodes needed. The graph will contain at least one bridge and at least two strongly connected components, that are connected with other part of the graph with exactly one bridge. Each of these components will contain at least k + 2 nodes (one node that is connected to the bridge is connected with k - 1 edges with other nodes in the component. Other nodes in the component will have degree k — odd number, so the total number of them should be even, to make component right graph by its own [see handshaking lemma]. So this min number of other nodes is k + 1. Therefore total number of nodes in the component is minimum k + 2 ---- one incident to bridge, k + 1 not incident).
There are at least two components with at least k + 2 nodes in each, so minimum is 2k + 4.
When we want find a bridge side in th graph . so we can think of two grpah has only one vertex's degree is
k-1,other's degree is k. And then we connect the graph and another.If we want to get the grpah which has only one vertex's degree isk-1,k+2 vertexs can get the graph.... And maybe solving other constructive algorithms can help you.i didnt, i went for 4*k-2. its pretty easy actually. first consider the bridge and name the vertices u and v. then add k-1 other vertices to the right side and connect all of them to v and them add another k-1 vertices to the right side and connect all of them to the previous k-1 nodes so now those k-1 nodes + v have degree k but the new vertices have all degree k-1 since k is odd then k-1 is even and you can connect every two adjacent pairs of the new k-1 vertices to each other so they now all have the degree k and now do the same thing for u and you are done.
For me its more like 2 * (k + 1) + 2, which is equal to his formula.
To get weight k in one component we need exactly k + 1 nodes. We have two components, so its 2 * (k + 1). Also we have a bridge, which is 2 more.
Shouldn't the degree of EVERY node be equal to k? The degree of the (k+1) nodes in each component is k, but what is the degree of the 2 nodes which form the bridge? Isn't it just one?
Yes it should. And it would :)
My algorithm: Generate graph of k + 1 nodes, each connected to each. Remove k-1 edges from there and connect these nodes to the bridge one. After that, you'll have k+1 nodes with k degree, and bridge node with k-1 degree. Duplicate this graph, so you get two of them. Connect bridge nodes. Solved.
UPD: Forget to tell, that we should pick edges for removing carefully — each of them should have unique nodes connected, so no duplicated allowed (because if any dup k-degreee would be violated)
The solution for E is not clear to me Please help if possible
You must be clear fist on the fact that (x->1 = 1)
This means that the last number in the input must be zero.
So now our sequence takes the form "xxxxxx...0"
Now we want to make the second to last number equal to 1 in order to have (1->0 = 0)
Now we have two cases:
You can just leave the sequence as it is ... all the numbers to the left of the 1 will just have no effect .. and then the final value will be (1->0 = 0)
We need to turn this new 0 into a 1 somehow in order to be like case 1.
In order to get rid of this zero we have to match it with some other number.
From the rules, we have (1->0 = 0) and (0->0 = 1), so obviously we will try to match this 0 with another 0.
So we will search for the first 0 to the left of this 0.
So our sequence now takes the form "xxxx...0111..1100"
We can get rid of this group of 1s by grouping (1->1->1->1->....->0 = 0)
So now our sequence takes the form "xxxx...0(111..110)0" = "xxxx...000"
Now you will just have to group these two 0s together to change them into 1
"xxxx...(0(111..110))0" = "xxxx...(00)0" = "xxxx...10" = "0"
Great explanation , i just wish codeforces editorials were written like this .
awsome explaination....thnks a lot.
I was unable to complete my code of D during the round. I did it differently and it was more intuitive.
My submission : CodeCould have done better by creating just 2 such bipartite graphs and removing (k - 1) / 2 edges from each one of them.
I suppose you meant edges not nodes.
Yes, sorry for the typo.
Could have done even better by taking a completeGraph(k)[or K(k)]. Refer: http://codeforces.com/contest/550/submission/11437241
EDIT: LOL, just realised the editorial does the exact same thing.
Problem B can be solved with partial sums?
Well, you can find all permutations of problems and test each segment of each permutation using prefix sum, but the complexity would be O(n!*n^2) and you would get a TLE. I don't know if we can do better than this (using partial sum, of course).
anyone did Problem B using recursion? I did using bit masking . Just curious !!
I've solved it with recursion (Backtracking) 11423350
In the recurrence of problem C,
I think when we are crossing out current digit,
recurrence should be:
dp[i][j] = max(dp[i][j], dp[i - 1][j])
Correct me If I am getting it wrong?
You're right. The editorial solution is appending a zero to j.
Can you explain why need to append a zero to j? thx
There's no need for it. In fact, it's wrong as grayhathacker pointed out.
For problem D, if k is even, then Eulerian cycle exists, thus there are no bridges.
We can solve problem C in O(1000 * len) without using dp. First find all numbers which are less than 1000 and divisible by 8. Convert them into strings. Now check if any one of them is a subsequence of the given string. This can be done in O(len).
Seems wrong...
E.g. string: 214
The answer (YES, 24) is not a subsequence of the original string.
UPD: Or maybe you meant the solution like this one?
24 is a subsequence of 214. Check the definition of subsequence here en.wikipedia.org/wiki/Subsequence
Yea, sorry, thought about it like "substring"
I think this would be 124 not 1000. Because there are only 124 numbers less than 1000 (Not including 1000) that are divisible by 8.
125
Nice approach.But it is better to solve using dp.Using recursion+memoization it is solvable in O(2*8*length).
E easier than D :)
I also think that E is easier than D but that is subjective. There are [to the date] 363 accepted solutions for E which is lower than half those for D (754 accepted solutions).
Благодаря этому контесту я понял, что регэкспы это круто, но только когда с ними не перебарщивать.
Как же хорошо, что я не осмелился на контесте писать это решение в строку)
И да, я впервые стал синим! Спасибо за отличный раунд!
I can't get what the editorial says about the dynamic solution for problem C. Can someone tell me how is it working with a c++ code?
can anyone provide dp solution for problem A? As dp was a tag in problem a
almost 2000 user tag edit access... now it has "chinese remainder theorem" XD . can anyone provide chinese remainder theorem solution for problem A?
I almost used dp to solve it :P
11422078
haha cool enclosed is my dp solution http://paste.ubuntu.com/11587440/
In problem C I generated first 125 numbers which are divisible by 8, then convert each of them to string and find if any of them appears in the given string as a substring. This can be done in O(125*len)
so many brute questions , not sure is codeforces or bruteforces.
I really liked D! Theoretical graph problem is much interesting than a algorithmic graph problem.
Somebody should fix the tags for Div 2 Prob A. Seems like someone went crazy and added every possible tag to the problem.
You could solve C in linear time ( O( (1000/8) * len ), actually ): just check for each multiple of 8 less than 1000 if it is subsequence of the input.
Seems that.But if n is large and mod is prime, that means is ok?
In Problem E, when I used the inbuilt 'string' in C++, I got a TLE at case:8. When I replaced the inbuilt 'string' with the character array char[], it got AC.
Here is my code using inbuilt string which got TLE : http://codeforces.com/contest/550/submission/11455328
Here is my code using character array which got AC : http://codeforces.com/contest/550/submission/11455369
Any reasons for that?
Anyway, array of characters is a slightly faster than the
stringclass - but it should not make sense and should not give an advantage to who uses array of characters instead -but someone may use the
stringto produce a much slower running code inadvertently, How is it possible ?Every appending operation uses
+has a complexityO(n)wherenequals to the length of the string,- since
C++does a resize operation -you may use the built-in
push_backfunction instead or even initialize your string to have such a maximum length and append elements by a direct access using index . look here is your first submission, just swap+bypush_backand got AC in139 ms550C- Which data type should I choose for the integer n <= 10^100 in C++? I am using long long, but with it test# 23 gives incorrect answer probably because of limit of long long.
std::stringwill fit just well. :)I didn't get the idea behind the DP solution for the problem, "Divisibility by Eight." Could someone kindly explain the solution in greater detail?
Let's first define DP state as dp( index , mod) = {0,1}, which means using the digits between the leftmost digit and digit at index, is it possible to make a number x such that x%8 == mod
We loop through all digit (i.e. loop through all index) for each digit, we have two choices naturally:
For the first choice, dp( index , mod) |= dp( index -1, mod) for all mod
For the second choice, it becomes tricker.
Consider dp( index -1, mod ) for all mod
If it is true, then if we append current digit,
the modular at index will become ( mod *10 + digit( index ))%8
So we just update this way: dp( index , ( mod *10 + digit( index ))%8) |= dp( index -1, mod)
Here's my code using this idea: 12143232
Hey kirakira amazing explanation! But i would like to point out that even though your solution got accepted, the way you handled the dp table for filling the store table .. distorted the dp table filling base logic and even confused me in the beginning.
You just cannot assume
dp[0][0]++even though you have added
store[0][0]=" "and further in the final ans checkedThis way it distorts the dp table filling logic and even confused me in handling the base case. This can be managed just by adding
The rest is same .. this is my accepted solution 16596112 . Still better explanation than the editorial :) It helped me. Thank you!
Please explain me the dp solution of problem C . thanks in advance :)
dp[i][j] represents that is it possible to have the remainder j from 0 to i.
let me explain to you with the example
take the num 3454 for this number dp matrix will be of order 5*8
for i = 1 : only possible rem is 3
for i = 2 rem possible are: [3 for number 3] [2 for number 34]
in case 34 rem 2 is possible only you take numbers 3 and 4 both, right! so newRem = (rem*10 + a[i])%8 => (3*10 + 4)%8 === 2. To have the rem is equal to 2 you have to check whether it is possible to have rem as 3 which comes for previous i. That's where dp[i-1][rem] comes into play.
similarly, if you are not taking number 4 into account then rem == 3 which comes from prev number. So in this case too you have to check for dp[i-1][rem] is possible or not.
for i = 3 rem possible are: [3 for num 3] [4 for num 4] [5 for num 5] [2 for num 34] [5 for num 45] [7 for num 345]
You can observe that all the rem depends upon the prev values expect for the remainder of size 1 for that particular i that's why you take dp[i][a[i]%10] = 1.
I hope you understand the concept well!
if same ques with 9..then can we use 2nd approch?
The test cases of problem C are quite weak. My program 32731408 passes the test cases, while it fails on 8460.
550A - Two Substrings Test case 17 is : ABAXXXAB with Jury answer "YES"
I think it does not contain two non-overlapping string "AB" and "BA".
hey someone help me plz @madhur4127 , suraj021 ? why we are taking the the numbers divisible by 8 below 1000 only in Div-2 C problem ?
Because a number is divisible by 8 if the number obtained from its last three digits is divisible by 8.
See this caption for generalization.
The dp formula given in editorial is wrong. It second formula should be dp[i][j]=max(dp[i][j],dp[i-1][j]); for 0>=j>8
Pleasant surprise that people still solve these problems :D
You are right, thanks. I rewrote editorial for problem C a bit, and added link to the solution with DP.
ADJA code solution for the problem C is not showing up.
Fixed, thank you
Thanks, you done so quickly.