


Google Code Jam Distributed Round starts in 15 minutes. It's a brand new format of contest, top-10 will advance to its own onsite final round in Seattle.
Let's discuss problems here after round finishes.
GL & HF everybody!
| # | User | Rating |
|---|---|---|
| 1 | jiangly | 3640 |
| 2 | Benq | 3593 |
| 3 | tourist | 3572 |
| 4 | orzdevinwang | 3561 |
| 5 | cnnfls_csy | 3539 |
| 6 | ecnerwala | 3534 |
| 7 | Radewoosh | 3532 |
| 8 | gyh20 | 3447 |
| 9 | Rebelz | 3409 |
| 10 | Geothermal | 3408 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Google Code Jam Distributed Round starts in 15 minutes. It's a brand new format of contest, top-10 will advance to its own onsite final round in Seattle.
Let's discuss problems here after round finishes.
GL & HF everybody!







PWND!
P.S. Hmmm... I don't understand why this picture is so small, because it was larger and when I try to resize it, its quality is horrible...
P.S.2 This picture is a little out-of-date because msg resubmitted E-large 17 mins later.
UPD: His large D and E failed and he didn't qualify :P (and as he admitted below, his C also shouldn't pass, but test data was very weak :P)
B: For simplicity assume that n=1e8, maxdis=1e6. Divide sequence to n/100 equal parts and give parts (i-1), i, (i+1) to i-th node. Note that all elements which need to be in i-th part of result are containted there. Sort elements in each node. Then sequentially by binary searches find elements with numbers 1e6 in first node, 1e6+1 and 2e6 in second, 2e6+1 and 3e6 in third etc.
C: How to do on one node? dp[i][j] — is a situation that first thread processed i operations and second j operations possible? Transitions are easy, deadlocks are pairs (i, j) such that dp[i][j] = true and we can't go neither to (i+1, j) nor (i, j+1) from that state . How to parallelize?
UPD: Thanks for W4yneb0t for pointing out that what was written here was not fully right. Here is updated version:
Divide array to blocks of sizes (n/100)x(m/100). I-th node will take care of 100 blocks in i-th row of blocks. In order to compute block with coordinates (i, j) we need to know informations on sides of blocks with coordinates (i, j-1) (which belongs to the same node) and (i, j-1), so when i-th node completes computing block it sends side of that block to node with number one bigger and computing of node (i, j) can be commenced which results in a good paralellization.
Very similar to problem "Sekretarka" from last year's distributed AE about computing LCS of 2 strings up to 1e5 characters, which I mentioned here: http://codeforces.com/blog/entry/18400?#comment-233794
D: This problem asks about size of the highest SCC in a tournament. How to do on one node? Count outdegrees (let it be that we have edge i->j if i loses with j), sort vertices in nonascending order and first k vertices form SCC iff their summed outdegree is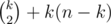 . How to parallelize? Count degrees in parallel xD. Rest is
. How to parallelize? Count degrees in parallel xD. Rest is  . Wow, such hard parallelization :D. Indeed a troll solution :P.
. Wow, such hard parallelization :D. Indeed a troll solution :P.
E: If I'm not mistaken this problems asks us about upper convex hull (despite the part starting with "Your list will contain every peak B with the following property:") which clearly contradicts rest of statement >_>...). Divide mountains into n/100 equal parts, compute their upper convex hulls and then notice that if we are "merging" two adjacent convex hulls then we need just one new segment (that means disregard a suffix of left hull and prefix of right hull) and it can be found in (nested binary search). However there are some implementation issues with those binary searches, but adding factor 100 to this shouldn't be a problem.
(nested binary search). However there are some implementation issues with those binary searches, but adding factor 100 to this shouldn't be a problem.
D: That's wrong, isn't it? A vertex may have a very big outdegree/indegree (I'm confused with your notation, but appropriate choice of a word will make my statement correct, I guess) and not belong to a highest SCC.
? Any vertex from highest SCC has strictly bigger outdegree than any vertex not from that SCC.
Wow. Indeed, that's cool. So simple solution =(
I was splitting vertices on groups, finding a highest SCC in each of them, returning to the master process and then doing the job on condensed graph on master process (the key idea was that we can significantly reduce the number of edges). But your of course is much simpler.
B: I dont really understand what your binary searches do. I believe you just need to get those elements that belong to block i
Hm, maybe it's little over-complicated, because I didn't give it a deeper thought on about how to implement it in a nice way since I was not eligible to participate xD. Each node has all elements which belong to his part and some elements from his left neighbour and some from his right neighbour. How to identify which are which in a simpler way? My approach was that if I already know last element from (i-1)-th block and I want to identify first element which should belong to ith block I just binary search first greater element in a list of elements in i-th block (maybe that description is somehow messy, but I hope you understand what I meant).
Yeah, I see, I throught about something similar first, but as far as I understand it's unnecesary (Will see if my solution pass)
Simpler solution is:
k = 220 is a very good constant. Since we are taking hash modulo k, we just need to find the right order of numbers on segments [0, k), [k, 2k) ... and for each of them sum up i * ai.
Split those jobs by machines. Now how we get the numbers that are in sorted order taking places [ik, (i + 1)k)? Consider the segment [(i - 1)k, (i + 2)k) and sort it (it is an array of length 3k). I state that the middle segment of it will be exactly what we need since [(i-1)k, (i+2)k) contains all number we need, they will take consecutive places and no other number can change a side (left/right in respect to that consecutive segment) it belongs to.
Wow, indeed I missed that observation that it will be middle segment and that simplifies it significantly. So in fact we can get rid of that binary search because it will always point to values in 1/3 and 2/3 position :D.
Well, it's not important that k=2^20 at all. You might as well split as you want and if node has range
[l; r) then you sort [l — maxDist(); r + maxDist())
C: Huh? That's not parallel, you can't start doing a block until you get the information from the previous blocks.
D: Wow, that's way simpler than what I did... I first searched for a hamiltonian path in O(n*sqrt(n)) on one node, then used that as my toposort instead of just sorting by degrees.
E: For the binary search, a priori, you don't know which node actually contains the peak you're interested in, so you have to ask all nodes which might contain it. This exceeds the message limit, it uses O(log(n)*numberofnodes) messages per node.
C: Uh, sorry, I didn't remember exactly how to parallelize this xD. However as I described it can be parallelized, but it will speed up just 10 times, not 100 times. I will update this. UPD: Updated that solution.
E: OK, I have to admit that I didn't care about messages limit :D. What was that exactly? Maybe we can do these merges not sequentially but by creating tree (I mean, firstly [1, 2], [3, 4], ..., [99, 100] then [1, 4], [5, 8] etc.). Will that be sufficient?
C: Ok, 10 times speedup works.
E: Each node can send up to 1000 messages of at most 10KB each (technically possible to send more than 10KB, but they said something about it being slow for whatever reason). I don't see how merging in a different way can help.
The judge solution merges segments one by one. That is, first 1 is merged with 2. Then 2 is merged with 3 (unless it disappears, then 1 is merged with 3). Then 3 is merged with 4 (unless it disappears, etc.).
A single merge is just a nested binary search, as mentioned above. The trick to speed it up is to send, say, 200 or 1000 positions at once, which allows the target to simulate 10 steps of the binary search at one go. This means that it's at most 2-3 hops to merge two segments. With ~5ms for a message pass, and at most 300 hops to perform, we use ~1.5s for communication. The nested binary searches are O(log^2 n), which is negligible, and calculating the convex hulls in each segment is O(N / NumberOfNodes).
Ah, so instead of binary search, you use 200-ary search, exploiting the fact that the message sending is also "parallelizable". Clever.
C: Actually, if you split it correctly, it is actually 100 times speedup (not sure if that's what you're saying after the edit, it's a bit confusing). You can work on 1 diagonal line at a time, splitting it into 100 parts.
Finding hamiltonian path is easier than that: just do a mergesort. I did the same btw.
Sorry, forgot to put this in my other post.
E: About the "every peak B with the following property" complaint: It is written in a slightly confusing way. They don't mean "For some peak A, B is visible from A, and nothing behind B is visible from A", they mean "For EVERY peak A, if B is visible from A, then nothing behind B is visible from A". I guess they used such confusing language in an attempt to sound like normal everyday English instead of math.
Yes, I have to admit for the tenth time in this subject that you're right :D. Kinda confusing but in fact it rather means "for all" not "exists".
Will fail Dlarge because forgot to remove
Ah, from 4th place to 30th :(
Wow, from 60th up to 13th after everyone else failed large. If I knew everyone's large was wrong, I'd have submitted brute force for the smalls instead of trying E, and I'd be qualified :S
Some rather weird TL I've got on E. I divide all work between 99 nodes which works O(chunk size), then sends something to server node, which process this in O(total data received). How can this be a TL and not message limit exceeded?
My guess would be that you try to send something around the size O(convex hull size) from each node. So, each node is within the limit of sending (it sends probably roughly 4MB of data), but the receiving master node is trying to get 400MB over the network. And that's not going to fly.
Your solution TLEd pretty consistently on the testcase where the convex hull within each 1/100th chunk was large (on the order of a 2M).
I see. Probably should've merged them by merging 2 at a time
Might've worked, not sure. I tried to produce test data that would make life hard for solutions that do "linear" merging instead of "logarithmic" (see the description of the intended solution, above), but I guess that with enough hard work it was possible to work around.
C. Consider operation i0 of the first thread and i1 of the second thread. Let S0 and S1 be the sets of locked mutexes immediately before these operations. This pair of operations can deadlock iff S0 and S1 don't intersect, and i0 is in S1, and i1 is in S0. Each node will consider every i0 and a range of i1. For each i1 from the range get the S1 as a bitset and put all these (up to 400) bitsets in a vector. Iterate over i0, keeping S0 and the sizes of intersections between S0 and S1 for each i1. Now we have everything needed to check the condition for current i0 and each i1 in O(1).
This is actually wrong as demonstrated by this test case — https://gist.github.com/msg555/4a6723c26b9616964f94
I have a feeling the test data is broken on this problem.
Every 'passing' solution I've tried fails this case as well (including my own).
This seems to be a serious problem. Have you notified the contest admins?
Yes, no reply yet
I checked msg555's data. I agree a correct solution should return "OK" on it. The judge solution does return "OK" on it (which is good), so the test data is correct, but weaker than it should be.
We're not going to rejudge everything or cancel the contest, although I obviously would have preferred to figure out this is an interesting testcase while preparing the data.
But the judge solution clearly thought about this case (since the OK means that it specifically checks whether a position is reachable), so it's also clearly supposed to be in the test cases.
I agree that rejudging everything would be wrong (since the small input actually gives you feedback during the contest, saying your solution is correct, so you can't change that), but can't you at least rejudge the large input? Since it doesn't give feedback, I don't see any reason not to do it.
5 people will fail C large and you'll advance (become 11th, but I guess someone is not eligible for onsite) :)
I have a better solution — invite 25 people instead of 10 :) Everyone will be happy :)
Or top 25 and Swistakk.
I guess I should have posted that from a fake account so people don't realize my selfish motives :P
You wouldn't get into TOP 10 even if all large Cs above you will fail :P
"Or top 25 and Swistakk." — yes, I approve that solution :D. Didn't advance to Round3, but advanced to finals 8]
+1 for the rejudge. (I'll stay in top 10 anyway). +1+eps for inviting the union of top10s with and without rejudge :)
The only "fair" thing to do would be to invite the union, and this is the standard procedure in this case in online contests (recent example: codechef snackdown round 1C), but you can't do that for onsites.
So, there are two reasons not to.
First, I feel that potential weakness of testcases is a part of every programming contest. As a judge, I try my best to have the hardest possible test cases, but this process will never be perfect. The contest, whenever someone submits a solution they're not sure is correct, is basically a smartness contest between the judge and the participant. The participant doesn't have to be perfect, he (or she) just has to be smarter than the judge.
I feel that, as a participant, I've got to accept the judges sometimes will make mistakes (especially in a contest advertised as a "beta", as this one was), and someone else will benefit. Of course, it would be better if the test cases were stronger, and it's my mistake they're not, but tweaking the testcases post-factum, after seeing the solutions, seems more unfair to me than leaving it be.
Second, in this particular case, if I thought of this testcase, it would have obviously been added to both the small and the large. Since this is a new platform, I tried to make the smalls representative; so that if your solution passed the small, you could be reasonably certain it's correct enough to pass the large (barring overflow, and other errors that occur with large data sizes).
Huh, that's sad that so many ACed solution are in fact incorrect :(. Frankly saying that was also my first thought to search for aba - 1 and bab - 1 subsequences, but when I realized that they may not be reachable I immediately changed my approach to dp. I think that it is pretty easy to be deceived by such condition and unpresence of such cases in testdata is a big overlooking. But everybody makes mistakes and it is understandable that such flawed solution hasn't occured to someone, but that raises another question — is testdata in GCJ/DCJ prepared by only one person?
I heard a story about Polish MO and a guy whose solution was incorrectly graded on final and he missed IMO because of that, but jury decided not to change his score, because it wouldn't be ok for guy who would lose IMO spot. However in case of DCJ in my opinion it is much more unfair for people who deserved better place and would have qualified, because solutions of other people were very badly graded than it would be for people who advanced but didn't deserve to. However, as I look at scoreboard only guy whose particiption in final can possibly be affected by rejudging is YuukaKazami and MiSawa (I know that Marcin_smu's solutions is ok) — WJMZBMR could lose it and MiSawa can gain it if WJMZBMR's solution is wrong, but I didn't check it.
UPD: As suggested in above comments — if WJMZBMR's solutions is wrong then simply inviting MiSawa is even better solution :).
If they go for the "invite everyone" option (which is about 0.01% likely), they'd have to consider the small solutions too, so it wouldn't be just one person.
If you considered the smalls, then it would be two people, from what I can see (Tomato and you)
I would have invited you two, but I hope enough people decline so you can go and no one is put down by the bad test data :)
Actually I am fine if they replace me by MiSawa. Clearly he deserves it better.
Sorry if my post maybe seemed rude to you, but I was just trying to consider all possible scenarios, becuse I was too lazy to check if your solution works :p. But as I already agreed, inviting a union of people would be better solution — unfortunately it was not an option in case of IMO, but I think that Google can afford this :P.
Wow, I receive the mail implciating that top #11 will advance. I think it is very good decision :)
Just for the record I think assuming the data is correct and merely weak that this is the right decision. Weak data happens all the time it's just a shame it can have such an influence.
Ah, so that's why I "won" :(
Can't it be that some pair of positions is valid (i.e. S0 and S1 don't intersect) but it isn't reachable?
Seeing that only 201 (359 yesterday) out of 500 allowed participated today makes me very sad, because I wanted that badly, but I was not eligible due to poor performance in R2 :(. And I'm sure that wouldn't be the only one happy to participate instead of someone who didn't. Has anyone an idea for explanation why that happened and how it can be omitted in future? Even that 359 is not a good result. Some people can have something very important to do, but surely it shouldn't be the case for 300/500 qualified people >_>... I have an idea that if someone knows for sure that he won't participate then he should be allowed to refuse his participation and next guy in standings (firstly 501st, then 502nd and so on) should be allowed. Do you think that it is a good solution? Wouldn't it be too troublesome for organizers to apply this?
500 is a LOT of people. If you look at the top 10 of round 2, probably either 9 or 10 of them participated, but the 500th might not care that much about gcj.
Second possible reason: The t-shirt cutoff is at 1000 people, the finals cutoff is at 25 people. If you participate in R3 and get 26-500, you receive absolutely nothing for it (well, except the fun). The majority of those 500 have almost no hope of being top 25, so they don't even try.
First reason: Aren't almost all Codeforces and TopCoder contests just for fun :P? Maybe if it possible to win a T-shirt then it is a little bigger motivation, but contest is for me more important than T-shirt :d (btw I recalled that Petr has bed sheet made by his wife from his programming T-shirts :P).
Exactly. In codeforces rounds, only a few thousand people participate, even though 22k are active on codeforces. So 359/500 is reasonable.
22k ever registered vs 500 highly motivated to get in Round 3 ?
22k active in 6 months.
I am the exactly 500th in R2 this year, and I care very much!!! :-)
Forgot to mention: it's not 201 and 359 people who participated, it's 201 and 359 who got at least one submission accepted.
About 201 — amount of people who participated in practice contests was about the same. Moreover is someone sufficiently good to qualify to R3 unable to sort a sequence not to get 1pt today :)?
Well... barely just that :P
It seems that testdata was even weaker than we thought :(. Smu told me that his solution is also wrong, even though it is not because of the wrong assumption, which al13n described, but because of incorrectly handling some cases (lack of +1 in range of clearing some dp arrays which rarely mattered)
A lot of contestants have used the "message.h" library. Is it provided Google specifically for Distributed Code Jam, or is it part of GCC? Is there some documentation available for I/O and message passing between nodes?
It was a small library provided by Google to communicate nodes each with others. See here is the section "The "message" library": https://code.google.com/codejam/distributed_guide.html