


Hi all. Tomorrow is the first day of the international olympiad in informatics which is currently being held in Kazakhstan. There is no topic for discussing the contest and problems and I want to create this blog to make it a place for discussions during/before/after the competition. What are your expectations, who are your favorites? Sorry for my bad English!
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Apr/24/2024 18:03:33 (j1).
Desktop version, switch to mobile version.
Supported by

Well, last year I did this
https://www.facebook.com/jonathanirvings/posts/10202121342861039?__mref=message_bubble https://www.facebook.com/jonathanirvings/posts/10202131588517174?__mref=message_bubble
This year I will do the same. I already done some preview commentary
https://www.facebook.com/jonathanirvings/posts/10204467118983976?pnref=story
Who know — where I can see the current results of the first round?
Everybody have 0 points right now
I found the link in other topic — http://scoreboard.ioinformatics.org/ Thanks to jonathanirvings !
Anyone noticed that Kazakhstan is mistyped (Kazakstan) in the tab of your browser when you open the site? :P
I'm trying to start the problem discussion with the problem "Graph" from practice sesion (link here). Actually I don't have a solution for the limits (N<=100000 and M<=200000.) Could somebody share their ideas for this problem?
As there is just one query for each input, the problem is simply shortest path with all edges have cost = 1, so a simple BFS can find out the answer, and the answer is equal to the minimum cost minus 2 as the answer does not count S and T.
But in the sample test the shortest path is 3... 3-2=1 and the answer is 2.
The answer is 2 xD
Nope. As the query was [ S = 0 , T = 4 ], so the answer should be the shortest path from 0 to 4 minus two. As the shortest path was 0 -> 1 -> 3 -> 4, the number of node passed = 4, so the answer = 4 — 2 = 2 ( Correct Answer !!! Huraay :D )
What about a graph with 4 nodes and these two paths: 0 -> 1 -> 3 and 0 -> 2 -> 3 ?
Is your answer 3-2 = 1?
Oops sorry I misunderstood the problem :P
Find a path from S to T. Then answer = number of bridges on that path
But in sample test all edges are bridges... :(... I was thinking something like run 2 dfs to compute for every node the number of outgoing paths to S and T, one on the original graph (S->T) and the other on the inverted graph (T->S), then multiply both results for each node... Then the answer would be all nodes having the same values than S and T. But i'm not really sure if that really works...
Sorry, not bridges, but cut vertices.
oh, no worries. Do you think the solution I explained above works?
Yes, I think it is right.
Problem task of day 1: https://acm.math.spbu.ru/ioi-2015-day1/
The official page seems to have the wrong links at the moment ... thanks!
Is there any place where we could submit solutions and get verdicts for the problems ?
How much points did brute force using selection sort take in problem scales (9 function calls in each test case)
45.45
wow that is too much for such naive brute force
Just a quick note: About 180 contestants did get so far, about 130 didn't. Out of those who didn't, about 50 implemented solutions worse than this one.
I have a feeling that I may be boring and a little rude with posts like that, but are those 130 contestants able to print "Hello world"? (Ok, Jarosław Kwiecień probably is able :P). For me it's hard to come up with something worse than that, it's incredibly easy, what I can understand is that maybe some contestant got problems with interactive problems implementation (but that alone of course shouldn't be worth any points)
This isn't worth more than 20 points (and anything worse is not worth nonzero), however I agree that it may be difficult to come up with some noncomplicated math formula which will do the thing.
There are many, many scenarios that might lead people who know how to "print hello world" to not submit this solution.
For example :
someone might be working on/thinking about a more complicated solution (while being perfectly aware of this solution) and runs out of time
someone might be entirely focused on producing the optimal approach that they don't think about brute force approaches at all.
someone might think they produced a better solution but they are wrong and it actually performs worse than this one.
the idea did occur to people but they rejected the possibility that it might score a non-infinitesmial number of points (for the same reasons you mention) and never actually checked how many points it would get
And so on down the line. Also even within solutions one may describe as "selection sort" there is quite a bit of variability.
How many points will 9 calls per run get ?
But don't you think that getting first two subtasks for problem teams(which is 34 points only) is harder than selection sort brute force for scales and should be awarded more than it?
I am not the best person to talk about this but sometimes there are easy and hard problems and often solving the hard problems for some partial score (which is less than 100) is harder than solving the easy problems for full score, so this is a common case in such competitions where all problems are awarded with equal points, at least this is my opinion :)
and how much points can I get with 6 function calls (in each test case) ?
100
Thanks.
6!=720>243=3^5, so it's impossible to judge this in 5 moves (however some nontrivial reasoning stands behind that and it's very easy to get it wrong).
I really can't understand why so many high rated coders got so little amount of points, it seems that 200 is really achievable, if not more.
Solving problems at home without pressure is easier than in the IOI contest hall.
I've got a question about http://scoreboard.ioinformatics.org/: why have some codes been submitted after the end of the contest?
If you look closely on the scoreboard, you'll notice a few submissions made after five hours had passed (I'm not pointing at anyone, but if you check some people's submissions, you'll find some such oddities). What has happened?
There is testing and discussion in schedule. Contestant are able upsolve the problems. That should be the reason. But I do not know for sure.
More likely those are judging times. I hear that by the end of the contest there was a 15-minute latency for submissions to "teams", for example.
I was trying to upsolve the problems a little while ago in the contest hall during analysis mode, so I think it's submission time.
And are your upsolving results showing on the scoreboard now?
Yes.
The contest judge was really slow (20 min for feedback on average), so some submissions got scored only after the 5h (sometimes like 1/2h after the 5h block !)
is the issue fixed ??
Can you give me any clue how to solve first problem 'boxes' ?
Circle
Here is diagram:
Ohh ... I was so close ... thanks for your clue . I think I can solve it now :)
Here also is solution Scales:
And Teams:
Can you solve the problem or not ? If you can help me then help , if you can't solve then stop trolling .
I don't yet have the full idea but my impression is that the main difficulty is deciding how many "full circles" to make.
Once you decide that and complete the "full circles" you're left with two 1-D problems (one for each "half" of the circle) where the optimal strategy is clear — just keep giving the gadgets to K most distant teams.
Yes, that's the same as my solution, but you can show that at most 1 full circle is needed. Put each team into a 'left' bucket or a 'right' bucket according to which direction you should go to reach the team. Each of the 2 buckets can be solved by a greedy algorithm, like you said. Now, suppose more than 1 full circle is used. In this case, at least one of the buckets must have received K or more souvenirs from the full circles. But there's no point in doing a full circle if all of the souvenirs from the circle were given to the same side. So using more than 1 circle is never optimal.
Yes exactly! And for the one cycle you can try each possibility for the division of K gadgets between the two buckets. Leading to a solution that scales with N+K.
Has anyone seen any problem that is related to this problem on any of the online judges by any chance?
(Personally I am not big fan of such ad hoc optimisation problems.)
Me too, that's why i've used dynamic programming. It's easy to prove that every distribution of boxes between two "0" is a closed interval. After this observation:
i - k ≤ j < i
f(i) = f(j) + cost(j + 1, i)
cost(a, b) = min{L, (L - b) * 2, a * 2}
Straight forward implementation gives O(N2) runtime. But decreasing it to O(N) is pretty easy.
You meant:
Team results after day one, ordered by the sum of points:
http://pastebin.com/raw.php?i=KFPERHAj
Where can i try problems ?
http://codeforces.com/blog/entry/19492
Could anyone tell how much the following solution for Scales is supposed to score?
Sort the first three and last three elements separately (we can sort an array of three elements in two moves using getHeaviest and getLightest). Say a[1] < a[2] < a[3] and a[4] < a[5] < a[6]. Now using getNextLightest, see where a[4] is supposed to be placed in the array (a[1], a[2], a[3]). Next, compare a[5] with the three largest elements in (a[1], a[2], a[3], a[4]); if a[5] is smaller than all of them, we know the sorted array is like (a[4], a[5], a[1], a[2], a[3]). Do the same thing for a[6]. This uses a total of 7 operations.
Of course, this isn't optimal... note that I don't use getMedian anywhere.
But when you compare a[4] with (a[1], a[2], a[3]) then if you get a[1] as the result, then you don't know if a[1]<a[2]<a[3]<a[4] or a[4]<a[1]<a[2]<a[3] is the correct order.
Oops yeah, you're right D: I should read the problem statement carefully before commenting...
The simplest way to fix this I can think of right now is to use another operation to compare a[1] and a[4] (for example, getMin(a[1], a[4], a[3])). If a[4]>a[1], we try finding the correct positions of a[5] and a[6] in the array (a[1], a[2], a[3], a[4]) using getNextHeaviest. Otherwise we try finding the correct positions of a[2] and a[3] in (a[4], a[5], a[6]). Unfortunately this brings up the number of operations to 8...
After the fix what you have is the 55.55 points solution. The ones that score roughly 71 are the ones that can do it in worst-case 7 weighings.
Okay, thanks! Hopefully this works for 71 points:
Say we have a[1] < a[2] < a[3] and a[5]=med(a[4], a[5], a[6]) (three operations so far). We call med(a[1], a[4], a[3]) and med(a[1], a[6], a[3]) to check which of the intervals [1, a[1]], [a[1], a[3]], [a[3], 6] contains a[4] and a[6]. If a[4] and a[6] belong to different intervals, we already know which one of them is larger and can use two more moves to find where a[5] should be placed (If a[4]<a[1] and a[6]>a[3], we call getNextHeaviest(a[4], a[1], a[2], a[5]) and getNextHeaviest(a[2], a[3], a[6], a[5]). If a[4] < a[1] and a[1] < a[6] < a[3], we call getNextHeaviest(a[1], a[6], a[3], a[2]). If a[2] > a[6], we use getNextHeaviest(a[4], a[1], a[6], a[5]) to see where a[5] should be placed. Otherwise we use getNextHeaviest(a[4], a[1], a[2], a[5]). We handle the case a[1] < a[4] < a[3] and a[6] > a[3] similarly.) Now suppose a[4] and a[6] are in the same interval. If they are both < a[1] or >a[3], we just need one more weighing to find out which one is larger among them- a[5] will be right in between of them. Now say we have a[1] < a[2], a[4], a[6]< a[3]. Call getNextHeaviest(a[2], a[4], a[6], a[5])-- if it is one among a[4] and a[6] (say a[6]), we know it's the larger among the two. Moreover, we know a[2] lies in one of the intervals [a[1], a[5]] and [a[6], a[3]]. We call getNextHeaviest(a[1], a[4], a[5], a[2]) to check the position of a[2]. If getNextHeaviest(a[2], a[4], a[6], a[5]) returns a[2] instead, we use one more operation to find which one among a[4] and a[6] is larger and we're done. This uses 7 operations in total.
Yeap, it will be only correct this way: if you have two blocks L, R.
If L.mx > R.mx then insert R in L, else insert L in R.
It will be 8 operations in total (1 for getting maximum).
That's what I wrote (it got 55,55 pts)
I want to share my solution for "Teams". If someone who is solved it can reply this comment, I will really thankful.
Sort the intervals, smaller b[i] to bigger b[i]. And sort the given array for this query. Find smallest i such that, there are k[1] intervals which is contain k[1], in all intervals which indices is smaller than i. We can do it, using vector with segment tree and binary search on it. Then we have to decrease the segment tree nodes which is fully inside of our range, number of j such that, j is in this node and a[j] smaller then k[1]. We do same thing for k[2].... It will be O(200000 * log2(500000)), and if it's not enough for time limit, we can add fractional cascading on it, I think.
I won't wait from you to understand my solution, of course, If you did a something similar, can you share with me? Or another solution for problem? Thanks.
I was thinking about the same thing, but I'm not sure if you can really update the segment tree efficiently (at least not while also keeping the fractional cascading). If you can do it, then I'd be interested in how this is done (I've spent a bit of time thinking about this, but I might be missing something).
However, I thought about another solution which doesn't require segment tree updates (only queries — thus, with fractional cascading, we get truly O(log(N)) per query).
First, let's assume that all b[i]'s are distinct. If they aren't, it's not difficult to extend all the intervals slightly so that all the equal b[i]s are mapped to distinct positions after the renumbering (e.g. if you have 3 b[i]s equal to 7, they can become 7.1, 7.2 and 7.3).
Then we sort the k[i]s in each query and we maintain a stack with the queries which we will do next for finding the intervals which "cover" a k[i]. An element of the stack consists of two intervals [p,q] and [r,s] and represent a query in the 2D segment tree (all the intervals having p <= a[i] <= q and r <= b[i] <= s). Initially the stack is empty.
We will consider the teams in increasing order of k[i]. If the stack is empty, we add to the stack the pair of intervals ([1,k[i]], [k[i],MAX]). Otherwise, let ([p_U,q_U],[r_U,s_U]) be the intervals at the top of the stack. Because of the way the algorithm works, we will have: p_1=1, p_V=q_(V-1)+1, s_1=MAX, s_V=r_(V-1)-1. This says that the intervals [p_X,q_X] are adjacent to one another and have increasing left endpoints, while the intervals [r_X,s_X] are adjacent to one another and have decreasing right endpoints (as we move from bottom to top).
If r_U > k[i] then we add to the top of the stack the pair of intervals ([q_U + 1,k[i]], [k[i], r_U — 1]) ; otherwise we only modify q_U and set it to k[i].
After this, we go through the elements of the stack from top to bottom, until we remain with zero needed intervals (which is initially equal to k[i]) or until the stack is empty. We first make the query [p_U,q_U] x [r_U,s_U], corresponding to the top of the stack (if r_U < k[i] then we first set r_U = k[i]). If the number of intervals is less than or equal to the needed number of intervals, then we pop the element from the stack and decrease the number of needed intervals accordingly. If the stack is not empty, then we update q_(U-1) and set it to q_U (we basically extend the interval [p_(U-1),q_(U-1)], which is now at the top of the stack, to [p_(U-1),q_U]). If, however, the query for [p_U,q_U] x [r_U,s_U] has more intervals than the number of needed intervals, then we need to find X = the Y^th smallest right endpoint among all these intervals (where Y=number of still needed intervals). What this means is that among all the intervals with left endpoint in [p_U, q_U] we need to use all those which have the right endpoints in [r_U,X]. We "mark" this by setting r_U=X+1 (i.e. by reducing the old interval [r_U,s_U] to [X+1,s_U]).
If the explanation above is too technical, think of the stack as a set of disjoint queries in the segment tree, in increasing order of priority (top to bottom). Essentially, you always want to consider intervals with right endpoints close to the current k[i] (but >= k[i]) and with left endpoints <= k[i]. As we advance with the index i, we get new left endpoints which are valid for the current i (those between k[i-1]+1 and k[i]). From the intervals with these new left endpoints we want to consume first those intervals whose right endpoints are smaller than any right endpoint of a remaining interval which has a smaller left endpoint than them. And once all such intervals are consumed, we "add" the remaining intervals with larger right endpoints by extending the interval of left endpoints from the new top of the stack to also contain [k[i-1]+1,k[i]].
There are O(M) push and pop operations and, thus, there are O(M) 2D segment tree queries (which can take O(log(N)) if we use fractional cascading).
In my solution I also used an additional operation which may be called O(M) times: finding the Y^th smallest element (right endpoint) in a 2D range. Of course, we can use binary search with range count queries on the 2D segment tree to support such an operation in O(log^2(N)). But we can use another 2D segment tree with fractional cascading in order to support this operation in O(log(N)) time, too.
I would be interested to know what the contestants which scored full points during the competition implemented.
My acceptet solution was O(n×sqrt(n)×lgn)
That was sufficient for 100pts?? I also came up with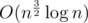 , but I was afraid if it will pass 77 pts tests (inb4 I'm not a contestant).
, but I was afraid if it will pass 77 pts tests (inb4 I'm not a contestant).
Few short questions that will be sufficient to tell whether our approach is The same — 1. Did you use Hall theorem? 2. Did you use fact that there are at most O(sqrt(n)) different values. 3. Did you use DP in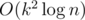 , where k is a number of different values?
, where k is a number of different values?
I think this is technically not but is instead
but is instead 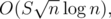 so this may be just a bit faster given that S ≤ 2 × 105. And @above, I'm also not a contestant but found the exact same solution as you are describing, using Hall's and DP.
so this may be just a bit faster given that S ≤ 2 × 105. And @above, I'm also not a contestant but found the exact same solution as you are describing, using Hall's and DP.
Yep, you're right, it was S instead of n, and I think the solution is the same
Thanks for solution, and explanation.
Here's my code http://ideone.com/IetuGM. I'm not sure but, I think it's true, because I only update the interval I want to deactivate. It's like, remove the numbers which are smaller than x, and query how many numbers in this array which are smaller than x, for increasing x? Is it possible on segment tree? It's logical but I never code it before, so It can be wrong. Here's my solution.
last : What is the last update for this node?
avl : Number of available nodes in this subtree.
doit : Last update in this node is a, let's make it b.
query_update : Only traverse the needed interval, and make them clear.
If it's true, we can use pair instead of int for last and avl, and in their seconds we can hold the last query time, and we don't need the clear segment tree after every query. (Query, which is we answer "Yes", or "No".) —————– And If it's true, and if we need fractional cascading, in the doit function, we can easily hold the
upper_bound(t[dep] + l, t[dep] + r + 1, a)in another array because it's the last update for this node, and forupper_bound(t[dep] + l, t[dep] + r + 1, b), all b are same for each query(Query, which is we answer "Yes", or "No".) so we can make fractional cascading on it. Am I right?Here's my solution:
solution:
We'll optimize the naive solution using persistent segment trees. Precompute, for each i, the persistent segment tree persist[i], which contains the b values of all intervals that intersect i. As we process the values of K, keep a persistent segment tree used, which contains the b values that have already been used. We can think of the values available to us as (persist[K[i]] - used). We update used in like this:
like this:
I realize something now, we can query the number of numbers which are smaller than x and in [l, r], online and O(N * log(N)) without fractional cascading, with persistent segment tree.
When is the 2nd day ?
It's on 30.7. @ 9am (Almaty time). Tomorrow is a break day.
Where can I find the day 1 tasks?
Problem task of day 1: https://acm.math.spbu.ru/ioi-2015-day1/
Someone has codes for tasks A and C ?? if there is please publish
Task problems of second day: http://ioi2015.kz/content/view/1/271
I wonder if horses are inspired by the problem of computing the optimal selling points for a stock given its history.
Given that interpretation various things become intuitively clear — one is that all horses will be sold off at a single "optimal time".
(If I sell a horse at time T1 I get Y[T1] for it and if I sell it at a later time T2 I get (cumulative growth per horse between T1 and T2)*Y[T2] — and depending on which is bigger it makes sense to sell all your horses at that time).
So the problem is really about figuring out the maximum out of X[1]*X[2]*...*X[T]*Y[T] as X[t] and Y[t] change.
It is still unclear to me how one completely solves this, but any change in Y[t] makes just that value to be a potentially new optimal one and any change in X[t] makes only the currently best value between t and N a potentially new optimum.
Now we have some optimal point J (if we sell horse in this point we will get maximum profit).
How to check if I is more optimal (or same) than J? (I > J)
We can just store 2 segment trees: one for optimal position in subtree and second is to get multiplication in segment.
Notice that ceil(Y[j] / Y[i]) is at maximum 10^9 so you can take multiplication as min(10^9, t[v+v]*t[v+v+1]).
To combine answer of 2 subtrees we'll call second tree to compute multiplication, so complexity for one query is log^2.
It got 100 pts.
Anybody used the observation that we can consider very few last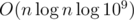 .
.
X[i] >= 2— andX[i]=1s after them? Using an obvious max-segment tree we would get the "complexity"For example, if
X[i]s are: {1, 1, 3, 1, 1, 4, 1, 1, 7, 1, 1, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1} and say the biggest of Y[i] is less than 100 (instead of 109 for clarity), we are able to discard all the elements before 4 (because if we sell everything in the end, we get an advantage of 4·7·3·2 > 100 from X-s alone). Thus we can keep an eye on X-s bigger than 1 and after each update just iterate over them from the end. It's easy to invent the remaining part of the solution.If somebody wrote such solution, can you write how many points it got?
I think it will get full score.
I wrote it and got 100
Yes. This was one of the intended 100-point solutions.
How about the solution of the other two problems? Towns sort of reminded me of this TopCoder problem http://community.topcoder.com/stat?c=problem_statement&pm=11742 but it actually seems to be quite a bit different.
Main idea for E is that order is not important. So you can binary search the answer and check it in O(M). Just do M moves and then try to sort it greedily. There can be some troubles because you need to return your moves. But it is not so hard.
May I know what do you mean by orer is not important? For example, if I have (A, B, C) swapping (A, B) before (B, C) leads to different result when compared to swapping (B, C) before swapping (A, B).
I mean if you can sort array in <= M moves after his M moves, then you can do it in that way (his move, your move and so on) too.
Is what you mean that I can't sort the array any faster if I just perform my moves after he performs his moves as opposed to performing them while he's performing them?
I can't see why that would be false but also not why would it be true.
My solution for horses ... We can notice that the answer is the maximum i that satisfies ( X[i] * X[i-1] * X[i-2] * ... X[1]) * Y[i] is our answer (modulo 10^9+7 of course) if we replace each X and each Y by its logarithm we can notice that it will turn into summation we make a simple summation segment tree with lazy probagation this solution works in N log N + M log M and gets 100 points
This was my first thought while reading this problem but I thought it might give precision issues.
Nope, I got 100 / 100 like that :-) You will probably need modular inverses to got a full score though, because you can't get the answer modulo directly from the logs.
I do not understand why my solution or comment has been treated as negative. please tell me the reason, so that i can improve upon any mistakes. thank you
There exists pastebin for pasting your codes and a bunch of similar sites. It's preferrable to use them instead of writing long comments. Just describe the approach in a comment and attach a link to your code next time.