


Adiv2
To solve the problem one could just store two arrays hused[j] and vused[j] sized n and filled with false initially. Then process intersections one by one from 1 to n, and if for i-th intersections both hused[hi] and vused[vi] are false, add i to answer and set both hused[hi] and vused[vi] with true meaning that hi-th horizontal and vi-th vertical roads are now asphalted, and skip asphalting the intersection roads otherwise.
Such solution has O(n2) complexity.
Jury's solution: 13390628
Bdiv2
It is always optimal to pass all the computers in the row, starting from 1-st to n-th, then from n-th to first, then again from first to n-th, etc. and collecting the information parts as possible, while not all of them are collected.
Such way gives robot maximal use of every direction change. O(n2) solution using this approach must have been passed system tests.
Jury's solution: 13390612
Adiv1
Let the answer be a1 ≤ a2 ≤ ... ≤ an. We will use the fact that gcd(ai, aj) ≤ amin(i, j).
It is true that gcd(an, an) = an ≥ ai ≥ gcd(ai, aj) for every 1 ≤ i, j ≤ n. That means that an is equal to maximum element in the table. Let set an to maximal element in the table and delete it from table elements set. We've deleted gcd(an, an), so the set now contains all gcd(ai, aj), for every 1 ≤ i, j ≤ n and 1 ≤ min(i, j) ≤ n - 1.
By the last two inequalities gcd(ai, aj) ≤ amin(i, j) ≤ an - 1 = gcd(an - 1, an - 1). As soon as set contains gcd(an - 1, an - 1), the maximum element in current element set is equal to an - 1. As far as we already know an, let's delete the gcd(an - 1, an - 1), gcd(an - 1, an), gcd(an, an - 1) from the element set. Now set contains all the gcd(ai, aj), for every 1 ≤ i, j ≤ n and 1 ≤ min(i, j) ≤ n - 2.
We're repeating that operation for every k from n - 2 to 1, setting ak to maximum element in the set and deleting the gcd(ak, ak), gcd(ai, ak), gcd(ak, ai) for every k < i ≤ n from the set.
One could prove correctness of this algorithm by mathematical induction. For performing deleting and getting maximum element operations one could use multiset or map structure, so solution has complexity 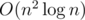 .
.
Jury's solution: 13390679
Bdiv1
One could calculate matrix sized n × n mt[i][j] — the length of the longest non-decreasing subsequence in array a1, a2, ..., an, starting at element, greater-or-equal to ai and ending strictly in aj element with j-th index.
One could prove that if we have two matrices sized n × n A[i][j] (the answer for a1, a2, ..., apn starting at element, greater-or-equal to ai and ending strictly in aj element with j-th index inside last block (a(p - 1)n + 1, ..., apn) and B[i][j] (the answer for a1, a2, ..., aqn ), then the multiplication of this matrices in a way
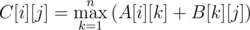
will give the same matrix but for length p + q. As soon as such multiplication is associative, next we will use fast matrix exponentiation algorithm to calculate M[i][j] (the answer for a1, a2, ..., anT) — matrix mt[i][j] raised in power T. The answer is the maximum in matrix M. Such solution has complexity 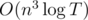 .
.
Jury's solution (with matrices): 13390660
There's an alternative solution. As soon as a1, a2, ..., anT contains maximum n distinct elements, it's any non-decreasing subsequence has a maximum of n - 1 increasing consequtive element pairs. Using that fact, one could calculate standard longest non-decreasing subsequence dynamic programming on first n array blocks (a1, ..., an2) and longest non-decreasing subsequence DP on the last n array blocks (anT - n + 1, ..., anT). All other T - 2n blocks between them will make subsegment of consequtive equal elements in longest non-decreasing subsequence.
So, for fixed ai, in which longest non-decreasing subsequence of length p on first n blocks array ends, and for fixed aj ≥ ai, in which longest non-decreasing subsequence of length s on last n blocks array starts, we must update the answer with p + (T - 2n)count(ai) + s, where count(x) is the number of occurences of x in a1, ..., an array. This gives us  solution.
solution.
Jury's solution (with suffix and prefix): 13390666
Cdiv1
Let's fix s for every (l, s) pair. One could easily prove, that if subarray contains ai element, than ai must be greater-or-equal than aj for every j such that 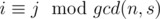 . Let's use this idea and fix g = gcd(n, s) (it must be a divisor of n). To check if ai can be in subarray with such constraints, let's for every 0 ≤ r < g calculate
. Let's use this idea and fix g = gcd(n, s) (it must be a divisor of n). To check if ai can be in subarray with such constraints, let's for every 0 ≤ r < g calculate
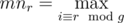 .
.
It's true that every good subarray must consist of and only of 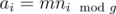 . For finding all such subarrays we will use two pointers approach and for every good ai, such that
. For finding all such subarrays we will use two pointers approach and for every good ai, such that 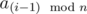 is not good we will find aj such that
is not good we will find aj such that 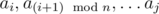 are good and
are good and 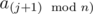 is not good. Let has k elements
is not good. Let has k elements 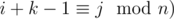 . Any it's subarray is superior, so it gives us arrays of length 1, 2, ..., k with count k, k - 1, ..., 1. As soon as sum of all k is not greater than n, we could just increase counts straightforward. There's a case when all ai are good, in which we must do another increases. Next we must add to the answer only counts of length x, such that gcd(x, n) = g.
. Any it's subarray is superior, so it gives us arrays of length 1, 2, ..., k with count k, k - 1, ..., 1. As soon as sum of all k is not greater than n, we could just increase counts straightforward. There's a case when all ai are good, in which we must do another increases. Next we must add to the answer only counts of length x, such that gcd(x, n) = g.
Solution described above has complexity O(d(n)n), where d(n) is the number of divisors of n.
Jury's solution: 13390645
Ddiv1
It is a common fact that for a prime p and integer n maximum α, such that pα|n! is calculated as 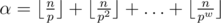 , where pw ≤ n < pw + 1. As soon as
, where pw ≤ n < pw + 1. As soon as 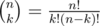 , the maximum α for
, the maximum α for 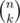 is calculated as
is calculated as 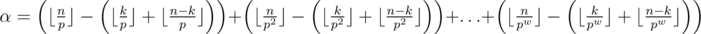 .
.
One could see, that if we consider numbers n, k and n - k in p-th based numeric system, rounded-down division by px means dropping last x digits of its p-th based representation. As soon as k + (n - k) = n, every i-th summand in α corresponds to carry in adding k to n - k in p-th numeric system from i - 1-th to i-th digit position and is to be 0 or 1.
First, let convert A given in statement from 10 to p-th numeric system. In case, if α is greater than number of digits in A in p-th numeric system, the answer is 0. Next we will calculate dynamic programming on A p-th based representation.
dp[i][x][e][r] — the answer for prefix of length i possible equal to prefix of A representation (indicator e), x-th power of p was already calculated, and there must be carry equal to r from current to previous position. One could calculate it by bruteforcing all of p2 variants of placing i-th digits in n and k according to r and e and i-th digit of A, and make a translation to next state. It can be avoided by noticing that the number of variants of placing digits is always a sum of arithmetic progression and can be calculated in O(1).
It's highly recommended to examine jury's solution with complexity O(|A|2 + |A|min(|A|, α)).
Jury's solution: 13390698
Ediv1
One could prove that the number of binary functions on 4 variables is equal to 224, and can be coded by storing a 24-bit binary mask, in which every bit is storing function value for corresponding variable set. It is true, that if maskf and maskg are correspond to functions f(A, B, C, D) and g(A, B, C, D), then function (f&g)(A, B, C, D) corresponds to maskf&maskg bitmask.
Now, we could parse expression given input into binary tree. I should notice that the number of non-list nodes of such tree is about 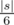 . Now, let's calculate dynamic programming on every vertex v — dp[v][mask] is the number of ways to place symbols in expression in the way that subtree of vertex v will correspond to function representing by mask. For list nodes such dynamic is calculated pretty straightforward by considering all possible mask values and matching it with the variable. One could easily recalculate it for one node using calculated answers for left and right subtree in 416 operations: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
. Now, let's calculate dynamic programming on every vertex v — dp[v][mask] is the number of ways to place symbols in expression in the way that subtree of vertex v will correspond to function representing by mask. For list nodes such dynamic is calculated pretty straightforward by considering all possible mask values and matching it with the variable. One could easily recalculate it for one node using calculated answers for left and right subtree in 416 operations: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
But all the task is how to make it faster. One could calculate s[mask], where s[mask] is equal to sum of all its submasks (the masks containing 1-bits only in positions where mask contains 1-bits) in 24·224 operations using following code:
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = dp[x][mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] += s[mask];
Let's calculate sl[mask] and sr[mask] for dp[l][mask] and dp[r][mask] respectively. If we will find s[mask] = sl[mask] * sr[mask], s[mask] will contain multiplications of values of pairs of masks from left and right dp's, which are submasks of mask. As soon as we need pairs, which in bitwise OR will give us exactly mask, we should exclude pairs, which in bitwise OR gives a submask of mask, not equal to mask. This gives us exclusion-inclusion principle idea. The formula of this will be
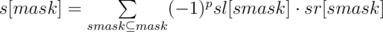 , where p is the parity of number of bits in mask^submask.
, where p is the parity of number of bits in mask^submask.
Such sum could be calculated with approach above, but subtracting instead of adding
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = sl[mask] * sr[mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] -= s[mask];
In such way we will recalculate dynamic for one vertex in about 3·24·216 operations.
Jury's solution: 13390713







I liked the problems, thanks!
Brute force, with a little bit of greedy, also passes for DIV2-C/DIV1-A.
Can someone explain test #5 from Div1 C?
It is said that the answer is 3 but I can only see two good pairs ((0,1) and (2,1)).
There is an another pair (2,2). We don't have a restriction l + s ≤ n
Ohh, thank you! I didn't assume that restriction but somehow missed that case anyway.
Similar problem to Div1 E was given in SRM 518 on Topcoder. The difference is that there was XOR instead of OR in the problem from that SRM. Interestingly enough, the approach from that problem can be used in Div1 E as well with a few modifications. For our problem the solution in terms described on Topcoder forum would be:
For example, if we want to compute
(x[0], x[1], ..., x[7]) @ (y[0], y[1], ..., y[7]) = (z[0], z[1], ..., z[7])Calculate two smaller
@operations:(x[0]+x[4], x[1]+x[5], x[2]+x[6], x[3]+x[7]) @ (y[0]+y[4], y[1]+y[5], y[2]+y[6], y[3]+y[7]) = (a, b, c, d)(x[0], x[1], x[2], x[3]) @ (y[0], y[1], y[2], y[3]) = (e, f, g, h)Then
z[0] = e,z[1] = f,z[2] = g,z[3] = h,z[4] = a - e,z[5] = b - f,z[6] = c - g,z[7] = d - h.I like to describe this approach in terms of formal polynomial multiplication where variables are taken from Z2 and coefficients belong to an arbitrary ring. I never seen a similar approach being described anywhere.
Consider a formal sum from Z2[x, x2, ..., xn] of form P(x1, ..., xn) = c0...00 + c0...01x1 + c0...10x2 + c0...11x1x2 + ... + c1...11x1x2... xn (the indices are binary masks of length n). We'll use the following rules of multiplication: coefficients c * are treated as usual numbers and are multiplied as numbers. Variables xi are multiplied like monomials with an additional rule that xi2 = xi (as if xi belonged to the field Z2).
Now we can multiply such polynomials, for example (3 + 2x1 - 3x2) × (x1 + 4x1x2) = 5x1 + 5x1x2.
Note that when we multiply polynomial P(x1, ..., xn) with coefficients {c0...0, ..., c1...1} by polynomial Q(x1, ..., xn) with coefficients {d0...0, ..., d1...1}, we get a polynomial R(x1, ..., xn) with coefficients {e0...0, ..., e1...1} satisfying the following formula:
It's exactly the formula of convolution we want to calculate, so now we'll understand how to calculate coefficients of product of polynomials $P$ and Q quickly.
Suppose that P(x1, ..., xn) = A(x2, ..., xn) + x1B(x2, ..., xn), Q(x1, ..., xn) = C(x2, ..., xn) + x1D(x2, ..., xn) (i. e. divide both polynomials into two parts, that contains x1 and that doesn't contain). Now let's rewrite the product:
. So, in order to multiply two polynomials of length $2^{n}$, we should perform O(2n) preparation work and then perform two multiplications of polynomials of length 2n - 1: A × C and (A + B) × (C + D). This leads to a recurrence alike to the Karatsuba's algorithm that does not three actions per recursive call but two:
.
That is exactly the same thing as everybody did (and as model solution), but I like this way of thinking since it allows to see the similarity of this algorithm and FFT or Karatsuba multiplication.
Solution link fr div2c is not working
As soon as a1, a2, ..., anT contains maximum n distinct elements, it's any non-decreasing subsequence has a maximum of n - 1 increasing consequtive element pairs. Using that fact, one could calculate standard longest non-decreasing subsequence dynamic programming on first n array blocks (a1, ..., an2) and longest non-decreasing subsequence DP on the last n array blocks (anT - n + 1, ..., anT).
I just can't catch that, and can you explain more about why we can precompute the first n array blocks and last n array blocks to get the answer? Although I got an AC with this approach just now, but I'm still puzzled, I'll be grateful if you can explain more about this.
If you consider an array from n to 1, you would need to go through the array n times to get the increasing sequence from 1 to n.
In this question, since you can't go through the entire sequence, we apply dp to a small portion of the entire sequence and extrapolate it to get the answer.
If you consider the blocks where you are actually changing the element you are at, you'll see that you're only doing n changes at max. This means that for the T - n blocks, you were stuck at a single element.
In order to bring a little order to this, we push the increments we are making to the beginning and ending, and let the blocks with the same element stay in the middle. A block which has only one element contributes only to its count in the original array, so there's also no point in having multiple elements stay the same in various blocks, one is enough.
Since we're leaving n blocks in the beginning and n blocks in the end, it gives us enough freedom to arrive to whichever element we want in the middle and start and end with whichever element we want.
Consider the example 456712344.
While it would be nice to take all 4s throughout the entire sequence, it would be little more optimal to choose 12344 in the first block, go for all 4s and then come to 4567 in the last block.
You are taking n^2 element at start and n^2 element at end. Calculating Longest non-decreasing subsequence for this alone cost you O(n^4).
But you mentioned overall complexity O(n^2logn). How are you calculating Longest non-decreasing subsequence in less time??
If you use the standard DP algorithm to find longest non-decreasing sub-sequence from n^2 elements then complexity will be O(n^4). By using the given constraints on elements (<=300), and making some changes : In DP part, instead of storing the length of longest non decreasing sub-sequence ending at ith position, you can maintain an array of size 300 and store the longest non decreasing sub-sequence ending at ith number. By doing so, the complexity will become O(300*n^2).
I can't find the solutions for DIV 2 C,D,E
Oh Alright! Its fine, this was my first contest, I didn't know that Div1 and Div2 had common problems, so basically Div2 C == Div1 A
In Bdiv1, C[i][j] = max(A[i][k] + B[k][j])?
I think it is C[i][j] = max(A[i][k] + B[k][j])
For Div2 B Robot's Task, what is the solution for 5 4 3 2 1 0
Isn't the solution 0?
No. You start from 0 position, so you should go all the way right to get the only piece of data you can then reverse and collect others.
Answer is 1
The robot is initially next to computer with number 1 (as the statement mentioned), so the answer will be 1.
I think in problem D, you need to prove the associativity of the operation over matrices!
It is indeed very close to matrix multiplication but it is not exactly matrix multiplication!
Brilliant solution by the way!
Let A be the answer for the first np numbers, B for nq, C for nr. By the definition (A × B) × C is the answer for the first n(p + q + r) numbers. It is obvious that A × (B × C) is also answer for n(p + q + r) numbers, so (A × B) × C = A × (B × C)
https://en.wikipedia.org/wiki/Max-plus_algebra
FYI
In problem Div2-D , second solution :
How we can prove that for middle part ( I mean T-2*n blocks in middle ) best solution is to select a[i]s ? not other selection between numbers a[i]<=x<=a[j].
Bdiv1
It should be max instead of min in the matrix multiplication, shouldn't it? Each sum Ai, k + Bk, j is the length of a possible non-decreasing subsequence of the sequence a1, a2... an(p + q). Why don't we just take the greatest possible length?
EDIT : Found the bug. Unable to find bug in my solution for Div2 C/Div 1 A. Gives WA on Test 23. Can anyone help me ? Solution
For the explanation of Div 1 C, mnr is defined as mini ≡ rmodg, but shouldn't this be the maximum? Since you want your element to be larger than or equal to all other elements it will cover.
fixed, thank you
http://codeforces.com/contest/582/submission/13403594 I don't know why this code doesn't work.
I was debugging my solution for GCD Table and i found that in test case 23, there is actually no solution. This solution does not get accepted 13406372 while this soltuion gets accepted 13406211. The difference between two is that is of a if condition which will occur only if for some number we don't have i,j gcd(ans[i],ans[j] )=number. Which a case for no possible. Correct me if i am wrong. Also if results, i have got, is correct then please reconsider grading Problem C div2 and Problem A div1 for this contest and update the ratings if possible.
Here's what's going wrong:
You first push a[i] onto ans, and later you remove all gcds between a[i] and numbers in ans, but the last element of ans is a[i], so you end up with two a[i]'s in your priority queue that shouldn't really be there. If you move the push_back behind the for loop it should work.
Honestly, you're lucky that second solution passes. EDIT: On second note, your second solution is correct, I didn't spot the
i++in the if-statement. Still, the first solution is very wrong.EDIT2: Here's a much simpler testcase that also goes wrong:
Your algorithm gives
12 7 5 2 2, where it should be12 7 5 2 1.I am having problem in understanding the approach explained in DIV2 D, can someone explain the solution.
Can anyone suggest further readings or link to understand the theoretic part of the solution in detail for Div 1 prob B using matrix expo? :D :D
could someone explain what's wrong with this solution of Div2-C http://codeforces.com/contest/583/submission/13487264 ?
For Ddiv1, could someone let me know where I can find more information about "It is a common fact that for a prime p and integer n maximum α, such that p^α|n! is calculated as ..."
So we want to calculate such maximum α that n! is divisible by pα.
Here is a formula for n!. Note that p is prime.
What multipliers are divisible by p? Every p-th multiplier is. There are n div p in total of such multipliers. We found that n! is at least divisible by p(n div p) at this moment.
Some of the multipliers are not only divisible by p, but also by p2. There are n div p2 in total. Each of the multiplier gives 2 to α. We have already considered them once above. To count them we should add n div p2. We found that n! is at least divisible by p(n div p + n div p2) at this moment.
We should continue this process until pw will be greater than n, and n div pw = 0.
Eventually we will receive the formula from the editorials.
Yup, same here. No idea why n segments are needed.
edit: n segments are needed for the case when a[] is a strictly decreasing array.
Oh no. Didn't read the problem statement correctly during the contest. I assumed robot can start from both ends that is from computer 1 and computer n. That's why i was getting WA.
In Bdiv1, I understand the "alternative solution". But I want to know how to access to problem like this at the first time. Please give me some advice.
I would really appreciate if the codes are well commented....
I need a better explanation for D please. I cannot understand last paragraph of D's editorial.
For div1 B / div2 D, I understood the second approach specified in the editorial, but couldn't understand the matrix approach, specifically how we get the relation:
$$$C[i][j] = maxOver(A[i][k]+B[k][j])$$$.
I tried observing the state of the matrix after each line, for various inputs, but still couldn't get the intuition behind this relation. Can someone please explain it?
Could someone help me to figure out why my code gives me WA on 5th test at problem B/div1? I have been thinking all the day but still cannot figure it out. Here is my submission: 213548711