


Начиная с октября 2015-го года рейтинг на Codeforces считается по открытым формулам, о которых и пойдет здесь речь. Вполне вероятно, что мы будем их слегка менять со временем, что будем отражать в этом посте.
Основная концепция используемых формул — мы расширяем принципы рейтинга Эло для встреч более чем двух участников.
Каждый участник характеризуется величиной рейтинга ri — целое число (возможно отрицательное). Грубо говоря, чем это значение выше, тем лучше участник выступает в соревнованиях. Рейтинг это подсчитывается/пересчитывается таким образом, чтобы выполнялось равенство:
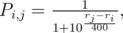
где Pi, j вероятность того, что i-й участник победит на соревновании j-го. Таким образом вероятность победы одного участника над другим определяется только разностью их рейтингов. Например, если разница рейтингов двух участников равна 200, то побеждает сильнейший с вероятностью примерно 0.75. При разнице рейтинга 400 вероятность возрастает до 0.9.
После очередного соревнования величины ri меняются так, чтобы в большей степени соответствовать основной формуле рейтинга. В данном случае “вероятность” какое-то расплывчатое понятие, последние соревнования вносят больший вклад в ожидаемый результат.
Рассмотрим момент до начала раунда и посчитаем для каждого участника его ожидаемое место (его называют seedi). Ожидаемое место равно сумме вероятностей по всем другим участникам обойти данного плюс один (плюс один берется из-за 1-индексации):
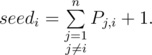
Например, перед Codeforces Round 318 [RussianCodeCup Thanks-Round] (Div. 1) при рейтинге 3503 ожидаемое место у tourist было примерно 1.7, а у Petr при рейтинге 3029 ожидаемое место было примерно 10.7.
Общая идея пересчета рейтинга такова: если участник занимает место ниже своего ожидаемого, то его рейтинг следует уменьшить, а если участник занимает место выше своего ожидаемого, то его рейтинг следует увеличить.
Посчитаем для участника среднее геометрическое его текущего места и ожидаемого, пусть эта величина равна mi. В самом деле, это какое-то среднее значение между ними, оптимистично сдвинутое в сторону меньшего из мест. Найдем (с помощью бинарного поиска) такой рейтинг R, которым должен бы был иметь этот участник, чтобы всё-таки ожидаемо занимать место mi (среди того же набора участников). Текущий рейтинг участника должен быть изменен так, чтобы стремиться к R. Поэтому, изменение рейтинга участника в раунде вычисляется как di = (R - ri) / 2.
Это почти всё, кроме фазы борьбы с инфляцией. Заметим, что при инфляции богатые становятся еще богаче, поэтому будем бороться именно с этим. Если предположить, что рейтинг был уже посчитан справедливо (то есть каждый участник имеет свой статистически обоснованный рейтинг), то математическое ожидание изменения рейтинга по любому участнику должно быть равно 0. Выберем группу наиболее высокорейтинговых участников раунда (по рейтингу ri — до начала раунда) и скажем, что сумма их рейтингов должна остаться неизменной. В качестве размера такой группы выбирается эвристическая величина 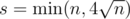 . Если di таковы, что их сумма для этой группы не равна 0, то ко всем им (по всем n участникам) прибавляется некоторое значение (вычитается) так, чтобы их сумма по s наиболее высокорейтинговым участникам стала равна 0.
. Если di таковы, что их сумма для этой группы не равна 0, то ко всем им (по всем n участникам) прибавляется некоторое значение (вычитается) так, чтобы их сумма по s наиболее высокорейтинговым участникам стала равна 0.
После раунда 327 ограничили этот эффект: сначала к каждому изменению прибавляется величина inc = - sum(di) / n - 1 (то есть di меняются), затем прибавляется inc = min(max( - sum(di) / s, - 10), 0). Таким образом, эффект изменения рейтингов из абзаца выше ограничен падением каждого рейтинга не более чем на 10.
Кстати, для любого логически непротиворечивого рейтинга должны выполняться несколько инвариантов:
- если участник A имел рейтинг хуже участника B и выступил хуже него на текущем раунде, то и его рейтинг после пересчета должен быть не лучше чем у B;
- если A выступил лучше B, но имел до раунда хуже рейтинг, то ему должны прибавить не меньше единиц рейтинга чем участнику B.
В частности, для обновленного рейтинга Codeforces эти инварианты проверяются на выполнение при любом пересчете рейтинга.
Ознакомиться с используемым кодом можно по ссылке: 13861109.







У рейтинга на TopCoder есть какой-то очень понятный статистический смысл.
Мы предпологаем, что "выступление" участника — это нормальная случайная величина, с матожиданием рейтинг, и дисперсией волатилити. И все кидают свою случайную величину и по ней сортируются. Более менее из этого же получаются формулы пересчета.
Можешь сформулировать какой-то аналогичный смысл этих формул? У меня пока плохо получилось.
Вроде как стандартный эло-рейтинг, строит попытку приблизить матрицу вероятностей выигрыша отношением (с точностью до преобразования) силы игрока 1 к суммарной силе игроков 1 и 2.
Формулы пересчета рейтинга никаким естественным образом не получаются и требуют дополнительные параметры модели, я не прав?
Так вот почему рейтинга так долго нету после контестов, вы его на Java считаете...
скорее на пайтоне
Конечно, очень круто узнать как считается рейтинг! но теперь мне интересно, чего же тогда рейтинг так долго пересчитывают? На сколько я понимаю асимптотика квадратическая относительно числа участников, что должно выполняться за считанные секунды:)
Открою небольшой секрет, пересчитанный рейтинг всегда известен(в любой момент соревнования). Просто нет смысла его публиковать до сист. тестов и проверки на читерство.
до сист. тестов действительно не вижу смысла публиковать, а читеров вряд ли на столько много, что они значительно влияют на рейтинг..
Пока менеждеры соревнования не убедятся в том, что результаты окончательные ничего пересчитывать нельзя. А случаи бывают разные: читеры, у кого-то может решение 2 раза посабмитилось и он просит убрать 1 сабмит или еще что.
решение 2 раза посабмитилось и он просит убрать 1 сабмитА так можно? Пару раз такое было =(
Примерно так:
Я конечно извиняюсь, но
И пусть 8000 человек подождут...
А если серьезно, разве этим не должен заниматься кто-то другой?
Адилет, ну вот нельзя было без левого аккаунта спросить? Некрасиво же, правда.
В Codeforces есть много задач — некоторые из них интересны, некоторые не очень. Некоторые из них требует непосредственно моего внимания (например, динамика рейтинга). Я внимательно слежу за каждым обновлением рейтинга, в предыдущей редакции порой вносил некоторые улучшения, чтобы скомпенсировать инфляцию и просто для составления полноты картины в голове.
На самом деле вряд ли кого-то из команды я могу попросить заниматься читерами. Координатор должен заслуженно отдохнуть, ведь он только завершил большую работу по проведению раунда. Если вы думаете, что координатор не хочет домой, вы ошибаетесь. Есть еще члены команды, кто пишет раунды, они тоже зачастую спешат домой после раунда. Требовать у них как штык никуда не уходить и заниматься делами еще часок в 10 вечера?
Адилет, думаешь это такая захватывающая обязанность внимательно проглядеть пару сотен пар исходников в перед сном? Я ценю усилия, которые прикладывает каждый из членов команды и хочу сделать так, чтобы каждому нравилось делать Codeforces лучше. А овертаймов и рывочков по выходным или в ночь у нас и так хватает, никто не скучает.
Интересно, прижилось ли использование на практике чьих-либо решений распознавания плагиата с Wildcard-2 VKCup ?
Ну я знаю примеры списывания, которые не были обнаружены. Хотя там всего лишь переменные/функции переименовали и форматирование поменяли. Может, потому что люди были на 1000-каком-то месте и лень было просматривать их руками?
Оффтопик. Комментарий выше от "tempuserhandle" наводит на предложение разрешать писать посты или комментарии только рейтинговым пользователям.
Возможно имеет смысл сразу запустить сис-тесты и пересчитать рейтинг. Затем скорректировать результаты по окончанию выявления читеров через несколько часов или даже дней.
Выявление читеров можно немного автоматизировать скриптами. Похожие по мнению секретных скриптов решения показывать участникам в неком доп интерфейсе. Ну реально 8000 человек ломают клавишу F5, а могли бы сравнить пару решений на предмет похожести. Сигнал от участников можно каким-то образом учитывать и уменьшить ваш объём работы.
-тратишь уйму свободного времени и сил на создание русскоязычного ресурса, который обходит по популярности topcoder.
-парню (внимание) вне рейтинга не нравится, что ты не живешь в универе и проводишь время с семьей, потому что это немного задерживает пересчет рейтинга.
??!!??!!??!!?
UPD: вкладка со вчера была открыта, не видел ответа Майка >.<
Это пять :)
На сайте справа есть рейтинг людей по вкладу и по рейтингу А так часто соревнования проводят на codeforces среди команд, вот нельзя сделать что-то вроде рейтинга команд. Я думаю многим будет интересно посмотреть
Если завести еще двух, то это решится)) Просить будут все — а выделять никого нельзя, хд.
Кажется, у кого-то кооод не компилится..)
Кажется, что текущая версия борьбы с инфляцией будет приводить к нежелательным перекосам на границе между топ s и теми, кто чуть ниже. В частности может оказаться, что человек A имел до соревнования рейтинг выше, чем B, выступил лучше, но рейтинг у него в итоге оказался ниже. Для того, чтобы это устранить надо видимо штрафовать не топ сколько-то, а сразу всех некоторой убывающей функцией (к примеру медленно убывающей геомпрогрессией).
UPD. Выяснилось, что вычитают у всех, поэтому такого эффекта не возникнет.
Может там не очень написано — дельты меняются у всех n участников. Мне кажется лучше делать именно так, ведь сдвиг всех на константу не меняет разностей и, следовательно, взаимных вероятностей побед.
Ясно. Но если сдвигать на константу, то разница между топом и остальными будет изменяться с той же скоростью, как и до вычитания, разве нет?
Ну это будет система с отрицательной обратной связью — основной инвариант не должен давать им совсем сильно разойтись. Вот и в случае с инфляцией вверх полз не только топ, но и вообще вся масса регулярно участвующих.
Тогда логичнее кажется такая штука: вычитать из всех некоторое число(возможно отрицательное), так чтобы суммарное изменение рейтинга было не больше нуля (защищает от инфляции в целом), суммарное изменение в топ-s было не больше нуля(защищает от инфляции в топе), и хотя бы одна из этих сумм равнялось нулю(защищает от чрезмерного занижения рейтинга активных участников).
Мне кажется, инфляция будет свегда: при регистрации участнику "печатаются новые 1500 баллов".
Только если новый участник потеряет часть рейтинга
Поэтому сумма рейтингов постоянно уменьшается. В самом деле, во многом инфляция обусловлена аккаунтами, что пришли разок, слили раунд и больше не возвращались. По этому не исключено, что мы понизим дефолтный рейтинг.
Можно перестать учитывать unrated участников при подсчете ожидаемого и реального мест.
После снижения стартового рейтинга, "новенькие" часто будут пачками двигать ДИВ2 вниз, в турнирах для ДИВ2. Нельзя считать их "слабыми" или "сильными" до первого контеста. Нужно генерировать их рейтинг по первым реальным результатам. А до того из расчетов исключить.
Возможно, рассмотрим и такой вариант.
Следующая проблема, которую я вижу: чем гарантируется, что суммарное изменение рейтинга не окажется большим нуля (или сильно меньше нуля)? Первое грозит инфляцией, второе тем, что рейтинг тех, кто участвует будет падать относительно тех, кто не участвует.
Понаблюдаем. Думаю первое время могут быть спецэффекты из-за перестройки значений рейтинга с предыдущих формул на текущие. Будем следить за статистикой и распределением, может что-то придется потьюнить.
Расскажите, тестировали ли вы новые формулы на какой-то истории прежних соревнований, или на моках с какой-то статистической моделью? Насколько адекватно получалось?
Выше уже отметили возможные проблемы, интересно, насколько формулы подвергались критике.
Да, конечно. Рейтинг неоднократно запускался на старых данных, работал параллельно старому некоторое время. Тестировался на правдоподобных моделях. Однако, это не значит что он идеально протестирован. Дело в том, что разделение по дивизионам шло на основании старого рейтинга и данные были не совсем корректны.
Мы и сейчас продолжаем его анализ и исследования, поэтому я и пишу, что детали могут измениться.
Логика рейтинга понятна и справедлива. Она базируется на занимаемых местах в дивизионе. А сохраняется ли справедливость между дивизионами? Написав одинаковые две задачи у последнего из ДИВ1, мне кажется, больше шансов остаться в своем дивизионе, чем у первого из ДИВ2 удержать свой рейтинг.
На самом деле ровно наоборот. В div1 слишком большое количество сильных участников, и, как следствие, участнику с рейтингом 1900, то есть слабейшему, достаточно сложно обойти других, а это необходимо даже для того чтобы сохранить свой рейтинг. В раунде 323 надо было для этого попадать примерно в 2/3 сильнейших и решать 2 задачи. В div2 первые участники, которые потеряли рейтинг в этом же раунде, находились около 500 места, т.е. 1/10 от всех, и они решали 3 задачи, а это аналогично 1 задаче в div1. Те же, кто решали div2 d-e, улетали вверх где-то на 50-100 очков.
Будут ли опубликованы ожидаемое место участников до раунда?
Не очень полезная инфа, ведь не понятно кто из зарегавшихся примет участие в раунде, а кто нет. Будет что-то вроде зарегистрировано 2000, ожидаемое место 500, участвовало 1200, занял место 300, но а рейтинг все равно упал:).
Реквестирую предварительное изменение рейтинга во время раунда/систестов. Изменение рейтинга по текущей таблице участников. Чтобы до реального обновления рейтинга можно было оценить успешность своего выступления (хотя бы примерно). Решит (по крайней мере частично) и проблему с нетерпеливыми, и вопрос с ожидаемым местом.
Найдем (с помощью бинарного поиска) такой рейтинг R, которым должен бы был иметь этот участник, чтобы всё-таки ожидаемо занимать место mi (среди того же набора участников).
Я так понимаю, это, в общем случае, интервал рейтинга.
Нет. Ожидаемое место — не дискретная величина.
Да, еще раз напоминаю, что система с двумя дивизионами приводит при стабильном множестве стабильных игроков к образованию зазора между дивизионами за счет передачи очков из младшего дивизиона к старшему. Не хотите сделать отдельно "кандидат в дивизион 1" и "кандидат в дивизион 2" с одинаковым рейтингом?
It would be nice if contestants can see their expected place in the standings or somewhere else for a particular round.
"General idea is to increase ri if actual place is better than seedi and to decrease ri if actual place is worse than seedi. "
It would be really cool if we know seedi before. We will know the maximum rank required to have an increase in our rating.
But the problem is seedi can only be calculated when we know who all the actual participants beforehand. Which is not possible because many registrants do not actually participate in the live contest.
One solution can be to do the calculations in the live contest and update seedi for each participant after a fixed interval of time (say 10 minutes and if new participants get added). 😀😃
Would be awesome to have a expected rank on dashboard while we solve problems in the live contest. Can't imagine the adrenaline rush :P
At least showing the expected rank after a contest is still possible.
Yeah that should be a nice feature.
Good ideas. But I don't think Codeforces will ever do any of this. I think they should also assume all registrants participated in the round even if they didn't submit any solutions. That way, the number of registrants would be the real number of people who had a chance to participate. Every round a lot of people register and then never show up during the contest.
I m sorry, but considering all the registered participants, and then performing the rating changes, assuming no change for those who didn
t participate doesnt satisfy the Basic Maths :PCould you please translate this blog to English so that non-Russian people can read it, since this is important blog and no one should miss it
Автокомментарий: текст был обновлен пользователем MikeMirzayanov (предыдущая версия, новая версия, сравнить).
Auto comment: topic has been translated by MikeMirzayanov(original revision, translated revision, compare)
Very informative. Thanks for making it open.
Wow, geometric mean. That explains why it's easier to go up than down.
Anyway thanks for making it open; community discussion can only help! I might have more detailed thoughts later.
My thoughts parallel those of JohStraat below, though perhaps changing geometric to arithmetic mean is a bit of an overcorrection in terms of punishing bad performances. It seems to me the current rating system is a collection of hacks on Elo, designed to have some desired effect. It works fairly well but has some strange properties: for instance, if the number of contestants changed drastically, the relative meaning of geometric mean would change.
I would rather instead we build a rigorous statistical model. For example, how about we suppose a person's rating r is drawn from a distribution centered at their "true skill" s with variance σ12. Their performance p in a specific contest is drawn from a distribution centered at s with variance σ22. Player i beats Player j iff pi > pj. Now we should perform a Bayes update, changing each player's rating to the mean of their posterior marginal distribution for s (the prior has s independently drawn for each player from logistic(r, σ12)).
Technical issues: the Bayes update may require numerical integration. I believe many of the partial sums can be precomputed and shared, so it should be fast enough. In a basic implementation, σ1 and σ2 should be global constants. If we want to get fancier, σ2 can be a function of certain factors that affect how accurately the contest measures skill; for instance, it makes sense to have σ2 be inversely proportional to the square root of the contest length. σ2 might also be higher for contestants who are much too strong or too weak for a given contest's difficulty. σ1 can be a property of each contestant, subject to Bayes update jointly with r: normally each contest will decrease the uncertainty, so we should also increment σ12 by a constant amount to account for the fact that people's skills change. Giving unrated coders a very high σ1 also prevents them from giving or draining too many points from the system for inflation or deflation.
I don't know how feasible it is, but it would be nice to invent a formula that naturally preserves some invariant such as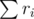 (or maybe something involving the $\sigma_1$s), as normal Elo does...
(or maybe something involving the $\sigma_1$s), as normal Elo does...
+1 This is very similar to the Glicko rating system used by many online chess sites.
Right, when σ1, σ2 are allowed to vary, my idea is essentially based on Glicko. When they are constant, it's closer to Elo but with a few distinctions:
1) A contestant's rank should not be treated as a sum of independent pairwise matchups. Instead, each pi is drawn independently.
2) pi is drawn from a logistic centered at si, whose prior is in turn logistic centered at ri.
These should be sufficient to prevent unduly punishing a single bad round, without resorting to the geometric mean. After all, it's much less surprising to get one bad draw from a logistic distribution, than 100 bad draws from independent normals. And if it's still not enough, we can consider asymmetric distributions for pi and si. Now it remains to derive some fast-computable formulas...
Ok I wrote up a draft! I plan to write more in the future, but for now just assume σ1 < σ2 and they are global constants.
https://github.com/EbTech/EloR
I conjecture that this system will have better properties than previous ranking-based update algorithms such as currently used by CF and TC.
Thanks for the clear explanation! Is it possible to open source the rating system? Put the code on Github? That way people can build tools on top of it? Maybe even parts of Codeforces (e.g. test evaluator etc) can be open sourced? Thanks again!
Please explain it easily. I don't understand.
you can understood the whole concept from here..
https://en.wikipedia.org/wiki/Glicko_rating_system
What is the actual time taken to do the calculations say for 5000 participants ?
What is the actual time taken to do all the calculations say for 5000 participants.
I didn't get the inflation "The rich get richer" case. How is it a problem ?
Yes, that isn't even inflation, it is inequality which isn't a problem in contests. The problem is if 400 rating difference doesn't signify a 10 to 1 win-loss ratio. Mike said that Tourist had an expected position of 1.7, but if you look at his history it isn't even close to that:
http://codeforces.com/contests/with/tourist
Sure he wins often, but he isn't even close to averaging a rank of 1.7 even before the blunder. And that blunder which is statistically impossible given his rating just lost him as much rating as he would get from winning 2 competitions. So he would have an expected rank of 1.7 if he just continued to alternate getting rank 1 twice and rank 168 once which doesn't really add up. Actual elo is made in such a way that it should be all but impossible to reach ratings as high as 3500, such ratings signify that there is a problem with how the rating is calculated.
Then in Codeforces Round #328 (Div. 2),There is a problem: Give you the rules of the rating changing and all participants' standings with their ratings; Calculate the change of ratings.
This causes inflation! I was wondering why people lost so extremely little rating for coming last in a contest, but now it is clear! With this system a person who places totally randomly will according to the system be expected to beat roughly 56% of contestants. So why not just do this instead:
This way sum of expected rank and actual rank will be the same. Sure it might punish people with high rating when they screw up, but protection of people with high rating is what causes rating inflation in the first place!
Difference between 1st and 10th place is much larger than between 41st and 50th.
That kind of reasoning is why 400 rating isn't even close to the alleged 10 to 1 chance of beating someone at the top. The point about ELO is that it is exponential so getting 2800 rating in chess means that you are an historical figure while 2700 is achieved by quite a lot of people. If codeforces used a real ELO then we would have such walls as well.
So with my system the difference between rank 1 and 10 is that rank 10 will never let you reach legendary status while rank 1 can, while the difference between rank 40 and 50 gets lost in the crowds.
As an example someone who alternates between rank 1 and 3 is obviously equal to someone who gets rank 2 every time (just take two people alternating and one stable and each of them beats each other 50% of the time) but this system glorifies the person with inconsistent results.
I think that one thing explaining why top scores on CF are higher than 2800 and that ratings functions are changing much more than in chess is that in chess one game is one win or one loss and on CF one round is like 600 games with particular users. In CF lack of one "ll" can cause your rating go down by 100 instead of having +50, it shouldn't be the difference between legendary user and "just red".
Btw I don't agree with your last paragraph. It depends on what is a measure you're using. If you take percentage of wins then you're right, however I don't think that is a perfect measure (in my opinion even pretty far from one). As I said, climbing on top of standings is much harder than on its lower parts. Assume that I did AB problems on one round and that gives me 100th place. If I solve problem C I will advance to 20th place. If I solve C and D I will advance to 1st position. Take 5 such rounds. Do you think that solving 4xABCD + 1xAB should be equivalent to 5xABC. Given your measure, it will be.
I probably don't get something in the math — how is this related?
Me too.
"We use di = (R - ri) / 2 as rating change for the i-th participant." initially it was di = (R-ri) / 3 and now this is di = (R-ri) / 2. was that a typo or the formula has been modified ?
"Let’s calculate expected place seedi for each participant before contest. It equals to the sum over all other participants of probabilities to win (to have better place than) the i-th plus one because of 1-based place indices:
Where is "plus one" in the formula of seed? Was that a typo?
I don't see there is a problem with the rating inflation if the skill level of existing members do increase overtime (relative to newcomers to Codeforces).
I think once you put in custom formulas / adjustments / caps, the basic principle "If the difference of ratings is equal to 400 then stronger participant will win with probability ~0.9." is not true anymore. Can any one correct me?
"Choose a group of the most rated (before the round) participants and decide that their total rating shouldn’t change. " is extremely flawed... are you expecting those who put hard work and training will not become better over time? (especially over the mediocre ones?)
Rating should be relative to not absolute. If because of some magic spell, all users become two times better than they were, keeping rating without changes is only sane solution. Moreover I guess it is a reasonable assumption that average level of cf member is almost constant function in time.
It isn't since competitive programming is still in an infant stage compared to most competitions. I mean, the world record in most physical sports 50 years ago barely qualifies you compete at the international level today and at least I think that refinements of training/techniques would have much less impact on lets say running than on competitive programming.
What happened to the cap of rating fall at ~-110 ;__;? Since my performances have big variances, that was really important to me xD. I have never experienced such a big fall or even similar one in Div1-only contest as yesterday's -140 ._. (even though I had greater fails)
Ho Lee Fuk Wi Tu Lo https://www.youtube.com/watch?v=17GbGmDORwk
He does not have two colors!
It seems that tourist's rating diverges. Is it reasonable?
Does this mean that it is easier to go up than go down in rating? Though I was confused about how to calculate this by myself.
Скажите, пожалуйста, а в комбинированных раундах рейтинг для каждого дивизиона вычисляется отдельно?
Если так то зачем в одну кучу их закидывать?
Емашь вы задр
раунды нормальные делайте, а то 100 баллов 1400 мест ,а рейт снимается. Хотя бы смотрите что вы добавляете в контесты.
Challenge submitted.
Если предположить, что рейтинг был уже посчитан справедливо (то есть каждый участник имеет свой статистически обоснованный рейтинг), то математическое ожидание изменения рейтинга по любому участнику должно быть равно 0. Выберем группу наиболее высокорейтинговых участников раунда (по рейтингу ri — до начала раунда) и скажем, что сумма их рейтингов должна остаться неизменной.Предпосылка "ожидаемое изменение суммы рейтингов равно нулю" неверна, поскольку опирается на независимость случайных величин "изменение рейтинга". Из независимости событий не следует их независимость при дополнительном условии.
Эвристическое утверждение. Наиболее вероятным исходом раунда является уменьшение суммы рейтингов группы наиболее высокорейтинговых участников.
Действительно, каждый участник равновероятно имеет рейтинг выше и ниже некоторого истинного значения. Если участник имеет рейтинг выше истинного, то ожидаемое изменение его рейтинга отрицательно. С другой стороны, если участник имеет рейтинг выше истинного, то и вероятность попасть в группу высокорейтинговых участников у него выше. Таким образом, в группе высокорейтинговых участников ожидаемо больше участников с завышенным рейтингом и ожидаемый эффект — уменьшение суммы рейтингов участников этой группы по результатам раунда.
I have a question about the changes. Why the history of color changes is not preserved? Initially red color was granted for getting 2000 rating. I understand the changes of colors and ranks but they should not affect the past.
Could you please reflect old color status on participants profiles?
Edit. Perhaps a better place for this, would be post which announces the changes, however there were 2 changes already and that post was mentioned recently, so I used it as a place to express my thoughts.
Last time there was a poll and most of participants didn't care about history preserving
Ok, I found it here: http://codeforces.com/blog/entry/20629
Well — let it be then...
Edit. Even though the voting rules were obviously in favor of the first option — those who were red at that time had a much bigger voting power and obviously it was more attractive for them to prevent others from ever achieving a red color.
So performance rating is roughly equal to Oldrating + change * 4?
Can anybody explain to me that how does this rating system remain consistent? I couldn't find any theoretical explanation toward consistency of this rating system.
Мне кажется есть недочет на границе дивизионов.
На 538 (only div 2) занял 515 место, был рейтинг 1982, изменение: -12.
На 539 (выступал в div 1) занял 466 место, был рейтинг 1970, изменение: -60.
По-моему не логично, ведь в див2 меня обошло много с более низким рейтингом и отняли мало, а в div1 обошло меньше человек, рейтинг у них и так в основном выше, а изменение намного больше.
Somewhere I saw ready-made formulas on how to get rid of the binary search when calculating the expected place $$$R$$$. Can you help me find it?
are you referring to this (under ELO system and expected rank): link ?
No, in my post above I mentioned that we use a binary search to find $$$R$$$. But it can be replaced with explicit calculations, and I previously saw a comment with such formulas. In the post you mentioned I don't see such formulas.
Let $$$n$$$ be the no of participants in a contest. $$$n$$$ is typically 20k-40k, but the rating range is [-500,4500], let $$$R = 5000$$$,
The current algorithm calculates everyone's rating in $$$O(n*n*logR)$$$
The rating calculation can be done in $$$O(n*R)$$$, for 35-70x speedup.Update 1: The rating calculation can be done in $$$O(R*R+n*logR)$$$, for 140-550x speedup.
Instead of running this loop in $$$O(n*n)$$$, we can run it in $$$(R*R)$$$ by maintaining the frequency of each rating point and calculating the seed for each rating. One can also overkill by using FFT in $$$O(R*logR)$$$
This one takes $$$O(n*n*logR)$$$ and can be optimised to run in $$$O(n*R+n*logR)$$$, with precalculations.This one takes $$$O(n*n*logR)$$$ and can be optimised to run in $$$O(R*R+n*logR)$$$, with precalculations.Precalculation -
if (getSeed(contestants, mid) < rank) { right = mid; } else { left = mid; }We can precalculate ranks for each rating point in the range [low,high] in $$$O(n*R)$$$We can precalculate ranks for each rating point in the range [low,high] in $$$O(R*R)$$$, by first calculating frequency of each rating point, and then running two for loops in O(R*R).
So that
getRatingToRank(contestants, midRank)will run in $$$O(logR)$$$ instead of current $$$O(n*logR)$$$Once this is done, the main for loop of
needRatingwill run in $$$O(n*logR+R*R)$$$ instead of the current $$$O(n*n*logR)$$$validateDeltas(contestants);It's too risky to touch, although we can use some 2D range query data structures to make it subquadratic.can some one suggest me how to calculate leetcode rating accurately and how can i convert it to codeforces equvivalent(i meant may be a guardian maybe map to 1700 etc...) its needed for my project.
For Chinese users, I'd like to giv u a link to a blog which was written by rui_er in Chinese about how to calc the rating.
Blog