


Consider a well-known problem: given a static array of size n, answer m queries of kind "how many numbers on [l, r] have value less than x". The standard solution is to build a segment tree where in every node we store a sorted vector. To answer a query we do a binary search in every corresponding node, achieving 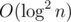 per query time complexity.
per query time complexity.
There is a method to reduce time complexity to 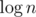 per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in O(1).
per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in O(1).
For years I thought that the second approach is blazingly faster than the first one. And today I've made a test. I implemented both approaches in a pretty straightforward way and tested them on a random data. The results were quite surprising.
Fractional cascading: 760 ms
Top-down implementation: 670 ms
Bottom-up implementation: 520 ms
The first one is  , others are
, others are 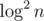 ! Time is averaged over several consecutive runs. Test data is generated randomly with n = 100000, m = 200000.
! Time is averaged over several consecutive runs. Test data is generated randomly with n = 100000, m = 200000.
Why doesn't fractional cascading give any improvements? Am I implementing it in an improper way? Anyway, this might be worth taking a look.







Did you measure the structure build time separately?
Yes. They are all about 70-90 ms, bottom-up approach statistically being a bit faster.
Standart solution will be to create persistent RSQ and say that get(l, r, x) = root[r].get(x) — root[l — 1].get(x) ?
Yes, but can you make updates?
Can you make updates to interval tree with fractional cascading?
Saying partial cascading you mean fractional cascading, right?
Oops. Sure. Thanks. Actually, I thought for a while that a word 'partial' makes no sense in this context but came up with that this is just one more stupid term.
I'm wondering where did you run into this issue: competitive programming, academic research or some commercial development? If it is the last option, I will not ask fur further details as that might be confidential, but still the very fact that there exist jobs where one could implement and use advanced data structure stuff would be cool by itself.
Will something like this really change the performance of the partial cascading implementation?
Could you explain "Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in O(1)." in more details? I didn't get the idea.
This is what is called fractional cascading, google it
read this pdf starting from 43rd slide
that pdf is not on the first (or second) page of search results for "fractional cascading" :P ??
try this search query "fractional cascading 2d range tree"
lol see it is the most firstest result :P
not entirely sure, but i think the first one is slower due to cache misses( linked list)
Like someone else has already pointed out, I think cache misses play an important role here. In the fractional cascading approach, you have to go through 3 "linked lists" so to speak (the lp, the rp, and the node itself) while the other solutions only have two such traversals (the node and the val arrays).
Having a single array of
struct Item { int val, lp, rp; };
Should probably eliminate such a problem. It might even be worth it to include pointers to the left and right child nodes Items directly into every Item. That would make every item larger but ensure a single (at most two in case of unlucky misalignment) memory access per visited node.
Also notice that the extra lg N cost in the other solutions is due to a binary search on a contiguous and typically small array, so it will be effectively quite cheap, and thus although fractional cascading should probably be faster if all implementions are made cache-friendly, the gain will not be huge unless we go to very large N.
My personal rule of thumb is that the difference between "cache-friendly operations" and "cache-unfriendly operations" is between 10 and 20 times in terms of runtime. So a cache friendly sqrt N typically performs about the same as a cache unfriendly lg N (very common in problems with cache-friendly Sqrt-Decomposition vs Treap or similar cache-unfriendly structures).
I've just tried your approach. Its consumed time is between straightforward fractional cascading and log^2 top-down approach, still not beating log^2 but a bit faster than the first version of cascading.
Interesting. Try to count the number of "far away memory accesses" in both cases. If the amount is similar in both implementations (lg^2 and fractional cascading) I can't think of any really obvious reason why it is not faster.
At this point, if you're still interested in investigating the issue, I strongly suggest using perf to pinpoint exactly where the program is consuming all of its CPU time.
perf tutorial: https://perf.wiki.kernel.org/index.php/Tutorial
Excellent talk on benchmark and C++ tuning using perf: https://www.youtube.com/watch?v=nXaxk27zwlk
perf even goes into the assembly, so it is an extremely powerful tool. Sometimes, unexpected compiler optimizations (or failures to optimize what should obviously be optimized) can be behind such counter-intuitive results.
You can try optimize cache misses in a number of ways.
1) Allocate memory in another order. For example allocate for small arrays first. Or i think it will be better to start allocation from up to bottom of recursion tree.
2) Avoid use "new" operator for memory allocation. It depends on actual memory allocator and can allocate memory in different pages depending on reqired size. allocation like
ptr = heap + heap_pos; heap_pos += size;can be better in your recursive memory allocation.3) There is technique to reduce number of page faults for binary search in a big array. Renumber array indices in a certain order. In a binary search algorithm, the very common element to read is n / 2, then n / 4, 3 * n / 4, n / 8, 3 * n / 8, etc... renumber elements in this way or use something heap-like full binary search tree to search elements. In an actual array of a big size very commonly accessed elements are stored at different pages. If you renumber indices like above, cache misses will occur only at last search stage on a few last pages.
PS: the last technique can be adapted for your specific set of arrays. It will be better to place most commonly accessed elements in cache.
can anybody tell me where I can find problems of this type?
http://www.spoj.com/problems/MKTHNUM/en/
260E - Dividing Kingdom
173E - Camping Groups
thanks, a lot my friend.
Similar effect with the rank-heuristic for DSU. O(a(n)) theoretical solution with the rank-heuristic works slower than O(log(n)) solution w/o this heuristic.
I think, such difference may be easily produced by uArch behavior on different code flows. Basically, this can be a question of constants for algo complexity, but the actual complexity func. It is interesting quesion and if I've got spare time this weekend I'll run uArch/memory analysis on these samples and report back with findings.
I'll just back up the others' answers. It's probably the same reason why even the leading prime sieves use Eratosthenes sieve and not the Atkin sieve, even though the former is slower with O(n log log n) compared to O(n). Atkin uses so much prime wheels and skips so much remainders such that the cache tends to miss all the time.
Practice is stranger than theory like how reality is stranger than fiction.
any problems and good tutorials for this technique? (for both standard and fractional cascading)