


I'm terribly sorry for the delay.
Please report any mistakes.
Author: Tigutor
You had to print all numbers of form kx for non-negative integers x that lie with the range [l;r]. A simple cycle works: start with 1 = k0, go over all powers that do not exceed r and print those which are at least l. One should be careful with 64-bit integer overflows: consider the test l = 1, r = 1018, k = 109, the powers will be 1, 109, 1018, and the next power is 1027, which does not fit in a standard integer type.
Author, developer: ch_egor
You were asked to print the product of n large numbers, but it was guaranteed that at least n - 1 are beautiful. It's not hard to see that beautiful numbers are 0 and all powers of 10 (that is, 1 followed by arbitrary number of zeros). If there is at least one zero among the given numbers, the product is 0. Otherwise, consider the only non-beautiful number x (if all numbers are beautiful, consider x = 1). Multiplying x by 10t appends t zeros to its decimal representation, so in this case we have to find the only non-beautiful number and print it with several additional zeros.
We tried to cut off all naive solutions that use built-in long numbers multiplication in Python or Java. However, with some additional tricks (e.g., ``divide-and-conquer'') this could pass all tests.
Author, developer: platypus179
Consider distances between the point P and all points of the polygon. Let R be the largest among all distances, and r be the smallest among all distances. The swept area is then a ring between circles of radii R and r, and the answer is equal to π (R2 - r2).
Clearly, R is the largest distance between P and vertices of the polygon. However, r can be the distance between P and some point lying on the side of the polygon, therefore, r is the smallest distance between P and all sides of the polygon.
To find the shortest distance between a point p and a segment s, consider a straight line l containing the segment s. Clearly, the shortest distance between p and l is the length of the perpendicular segment. One should consider two cases: when the end of the perpendicular segment lies on the segment s (then the answer is the length of the perpendicular segment), or when it lies out of s (then the answer is the shortest distance to the ends of s).
Author: cdkrot
Developers: cdkrot, galilei2000, ch_egor
Let's save the original positions of skills and then sort the skills in non-increasing order (almost decreasing) by current level. We can always restore original order after.
Imagine that we have decided that we want to use the minimum level X and now we're choosing which skills we should bring to the maximum.
At first, let's rise all skills below X to level X, this will set some tail of array to X. But the original array was sorted, and this new change will not break the sort! So our array is still sorted.
Obviously, the skills we want to take to the maximum are the ones with highest current level. They are in the prefix of array. It is easy to show that any other selection is no better than this greedy one.
Now we have shown that the optimal strategy is to max out the skills in some prefix. Now let's solve the problem.
Let's iterate over prefix to max out, now on each iteration we need to know the highest minimum we can achieve, let's store the index of the first element outside the prefix such that it is possible to reach the minimum level ≥ arrindex.
It is easy to recalc this index, it slightly moves forward each turn and, after precalcing the sum of all array's tails, you can update it easily (just move it forward until the invariant above holds). And knowing this index is enough to calc the current highest possible minimum level (min(A, arrindex + ⌊ sparemoney / (n - index)⌋).
How to restore the answer? Actually, all you need to know is the count of maximums to take and minimum level to reach.
Author: cdkrot
Developers: cdkrot, crossopt, ch_egor
Surprisingly, the nice cuts can't be put randomly. Let's take a look on the first picture above (red lines represent nice cut points). But since the necklace is symmetrical relative to nice cuts, the cut points are also symmetrical relative to nice cuts, so there is one more cut (see picture two). Repeating this process, we will split the whole necklace into parts of the same size (picture three).


If the number of parts is even, then each part can be taken arbitrarily, but the neighbouring parts must be reverses of each other (e.g. "abc" and "cba"). This is an implication of the cuts being nice.
If the number of parts is odd, then each part is equal to each other and is a palindrome, this is an implication of the cuts being nice too.
Anyway, the number of characters in each part is equal, so amount of parts can't be greater than 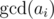 . Actually, it may be zero,
. Actually, it may be zero, 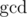 or its divisor.
or its divisor.
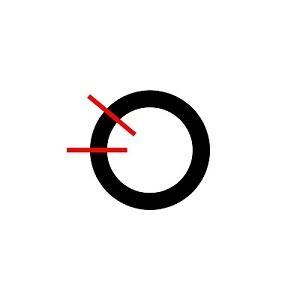
If the number of odd-sized colors is zero, then the sum is even and gcd is even, this way we can construct a building block containing exactly
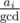 beads of i-th color, (gcd being gcd of all counts), then build beads of gcd parts, where each part equal to building block, with neighbouring parts being reverses. Since gcd is even, everything is ok.
beads of i-th color, (gcd being gcd of all counts), then build beads of gcd parts, where each part equal to building block, with neighbouring parts being reverses. Since gcd is even, everything is ok.If the number of odd-sized colors is one, then the sum is odd and gcd is odd. Building block have to be built as a palindrome containing
beads of i-th color, exactly n - 1 of colors will be even and one odd, put the odd one in center, others on sides (aabcbaa). Everything is ok.If num of odd counts is geq2. Gcd is odd, all its divisors too, so our building block has to be palindrome. Let k denote the number of parts. A building block will contain
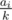 beads of color i, at least two of these numbers are odd, it is impossible to build such a palindrome. The answer is zero.
beads of color i, at least two of these numbers are odd, it is impossible to build such a palindrome. The answer is zero.
Complexity: O(sum), just to output answer.
Bonus. How to solve problem, if you are allowed to discard any subset of beads before constructing necklace?
Bonus. Given a necklace scheme (like one you were asked to output), how to determine number of nice cuts, O(sum), no suffix structures or hashes?
Authors: ch_egor and others
Developer: cdkrot
Obviously, the answer is -1 iff two important cities are adjacent.
If there was a single query, can we answer it in O(n) time? Let's choose a root arbitrarily. We can note there is an optimal answer that erases two types of vertices: vertices that lie on a vertical path between two important vertices, or LCA of some pair of important vertices.
Let's do a subtree DP that counts the answer for the subtree of v, as well as if there is any important vertex still connected to v in the answer. How do we count it? If v is important, then we should disconnect it from any still-connected vertices from below by erasing these children which contain them. If v is not important, then we erase it iff there are more than one still-connected important vertices below. All calculations are straightforward here.
How do we process many queries now? There are many possible approaches here (for reference, look at the accepted solutions). The author's solution was as follows: if we have a query with k important vertices, then we can actually build an auxiliary tree with O(k) vertices and apply the linear DP solution to it with minor modifications.
How to construct the auxiliary tree? We should remember the observation about LCAs. Before we start, let us DFS the initial tree and store the preorder of the tree (also known as "sort by tin"-order). A classical exercise: to generate all possible LCAs of all pairs among a subset of vertices, it suffices to consider LCAs of consecutive vertices in the preorder. After we find all the LCAs, it is fairly easy to construct the tree in O(k) time. Finally, apply the DP to the auxiliary tree. Note that important cities adjacent in the auxiliary tree are actually not adjacent (since we've handled that case before), so it is possible to disconnect them.
If we use the standard "binary shifts" approach to LCA, we answer the query in 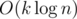 time, for a total complexity of
time, for a total complexity of  .
.
Author, developer: Endagorion
The key observation: any way to cross out the word w looks roughly as follows:
..v<1.>>v.2<...
..>>>>^.>>>^...
That is, there can be following parts:
go back a symbols in one row, then go forward a symbols in the other row (possibly a = 0)
go forward with arbitrarily up and down shifts in a snake-like manner
go forward b symbols in one row, then go back b in the other row (possibly b = 0)
Note that the "forward" direction can be either to the left or to the right. It is convenient that for almost any such way we can determine the "direction" as well as the places where different "parts" of the path (according to the above) start. To avoid ambiguity, we will forbid a = 1 or b = 1 (since such parts can be included into the "snake").
Fix the direction. We will count the DP dx, y, k for the number of ways to cross out first k letters of w and finished at the cell (x, y) while being inside the snake part of the way. The transitions are fairly clear (since the snake part only moves forward). However, we have to manually handle the first and the last part. For each cell and each value of k we can determine if the "go-back-then-go-forward" maneuver with parameter k can be performed with the chosen cell as finish; this can be reduced to comparing of some substrings of field of rows and the word w (and its reversed copy). In a similar way, for any state we can check if we can append the final "go-forward-then-go-back" part of the path to finally obtain a full-fledged path.
This DP has O(n2) states and transitions. However, there are still some questions left. How do we perform the substring comparisons? There is a whole arsenal of possible options: (carefully implemented) hashes, suffix structures, etc. Probably the simplest way is to use Z-function for a solution that does O(n2) precalc and answers each substring query in O(1) time (can you see how to do it?).
Also, there are paths that we can consider more than once. More precisely, a path that consists only of the "go-forward-the-go-back" part will be counted twice (for both directions), thus we have to subtract such paths explicitly. Every other path is counted only once, thus we are done. (Note: this does not exactly work when w is short, say, 4 symbols or less. The simplest way is to implement straightforward brute-force for such cases.)







Can div2 D be solved using ternary search....basically we can divide m units into x and m-x...x units to improve minimum skill level and m-x units to perfect some skills....I have implemented it here 15405049 but its getting wa because my function over which I ternary search is not strictly inc/dec... I know its a overkill for this ques but for future reference is there someway around it( ternary search on func which is not strictly inc/dec )?
Ternary search will fail if there isn't exactly one extrema(maxima if you're using TS for finding maximum with one or more global minima, or else minima and one or more global maxima) in the search range.
I agree on that but here my extrema forms a continuos range so it still got the property of being convex function....I thought there maybe some trick existing for it.
See my submission 15397254. I tried much times using ternary search and finally got AC(to check every x when the range is smaller than 64 instead of searching to the end). But I don't think it's a correct solution.
nice idea for a contest...although it can be hacked easily :)
How? I have done it in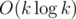 time and it wasn't obvious.
time and it wasn't obvious.
You're right, it's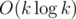 . I had in mind sorting important vertices along with the LCAs in pre-order, and then determine parent-child relations by processing all of them with stack.
. I had in mind sorting important vertices along with the LCAs in pre-order, and then determine parent-child relations by processing all of them with stack.
Still, I suppose there's a faster and still simpler approach.
Well, I still don't understand how to build that tree and I've met 2 problems since the contest where I needed to build exactly the same tree. Can you, or anyone who solved it without doing very hard things, explain a more detailed solution? (I'm talking just about building the tree).
Thanks in advance.
OK, I'll try to explain step by step. We're building a tree "spanned" on vertices v1, ..., vk.
Finally, we know the parent-children structure of the spanned tree.
Thanks a lot, I think I got it.
In problem E you don't need any string algorithms to compare substrings, just a simple DP like this:
Also I didn't do any brute-force for small strings. I just ran DP from left to right for original word and for reversed word, so the only paths counted twice are the ones lying in one column (which means word length <= 2), and they're easy to exclude.
Codeforces Round #339 (Div. 2) 614A - Link/Cut Tree 15399737 I don't get what is the error in my submission. Please suggest.
It happens because of the overflow of long , you need to check whether the number would overflow or not before multiplying .
for input 237171123124584251 923523399718980912 7150
237171123124584251 <= 239852470977948384 <= 923523399718980912 right?
Yes, but if you use an online calculator, you will see that 239852470977948384 is not even a power of 7150 (the lack of trailing zeros also points to that). Since 7150^5 is more than the limit of long, it overflows and the result is the number that you have got as the output. Check to see if the overflow takes place before you multiply.
https://ideone.com/p73Kr7 This is my solution for "Peter and Snow Blower", which was not been accepted during the contest due to exceeding error. Can anyone suggest something to bring down the error?
Well, I don't think 22/7 is close enough to pi. You should also read the editorial because your solution does not seem to be correct.
There is 8 authors, but cdkrot made up 3 problems of the seven ones. What have other authors done? Respect to cdkrot
Look attentively.
In div2 614C - Peter and Snow Blower I expected you to mention a hint for how to calculate the distance between center point P and segments of the polygon!
I'm sure you can find that very easily by googling. It's a very standard problem.
HidenoriS please can you help me out how this problem can be solved using ternary search/binary search as the tags of the problem suggest.
15446844 can anyone see my code and tell me where is the mistake. It is for div2 3rd problem and i am getting wrong answer on test 38. Thank you!
I believe that you have a rounding error because your code is using int, so try using float or double (or the equivalent in Python). The same thing happened for 15741131 but was fixed in 15741274.
Also, you need the consider the segments in between each two consecutive points. Consider:
The answer should be 3141592.65359 since the segment between the first and second points passes very close to the center.
Hey, i tried and solved problem A div 1(Peter and the snowblower), here is my solution:http://pastebin.com/E6YXf2wH it says that it wrong on test 3.do you know why?
These lines won't work properly if points A and B are vertical/horizontal.
I'm not getting how to solve problem DIV2D please help
In A, I don't understand the part with the segment. Why do we need it? What is the purpose of it?
See this comment which shows a good example. The closest point to the center might be on one of the edges of the polygon.
613B: "At first, let's rise all skills below X to level X, this will set some tail of array to X. But the original array was sorted, and this new change will not break the sort! So our array is still sorted."
How to compute X?? Why we need X? imagine example 2 1 1 1 and suppose we have m=1 and A=3. Using your explanation i should to increase some low level skill, but in this case it'll be wrong. Can somebody explain this problem in a bit more details?
You don't need to calculate the level X.
This part your are referring to is proof of the fact, that for any given min level X it is always optimal to take to maximums skills in some prefix (actually the longest prefix you can).
For div 1 B is the complexity O(n log^2 n)?
O(n log n) as per the editorial solution,