


This is the editorial for Croc Champ 2012 - Final
Remarks
One day, I applied to write another round in Codeforces. To my surprise, I was offered to write CROC instead. I'm quite surprised they offer me (an unknown programmer from a notorious country) to write for such an important match! So I happily oblige — kudos for the open culture nurtured by Codeforces!
I like most the problems of this final round. I think all of them are beautiful in some aspects :). Oh, and all of them emits such concise solutions ;).
Problem A
Author: dolphinigle
Ad Hoc I supppose...
This problem is equivalent to calculating the number of reachable locations from point (0, 0) by doing the allowed moves.
The naive solution is to process the information one by one from first to last, and to keep track on all the reachable positions.
Claim: At any moment in time, all reachable locations as described above forms a "diamond".
An extremely informal proof is by induction:
For instance, let's use the first example:
UR UL ULDR
Initially, there's only one possible location (namely, (0, 0)). It forms the basis of our induction: a diamond with width=1 and height=1.

"UR" (and also "DL") extends the width of the diamond into a 2x1 diamond:

Then, "UL" (and also "DR") extends the height of the diamond into a 2x2 diamond:
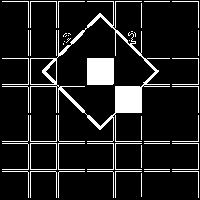
Finally, "ULDR" extends both the height and the width of the diamond into a 3x3 diamond:
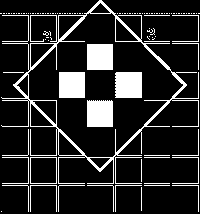
And so there's 9 possible locations.
To see that this claim is true, suppose by induction our locations so far forms a diamond. By symmetry we only need to see that in the "UR" case, its width is increased by one (I'll omit the similarly seen "ULDR" case). The idea is the new possible locations = the previous diamond shifted one step up UNION that diamond shifted one step right. Indeed, the union of these two diamonds accounts for both the "U" and the "R" moves.

It's not hard to proof that the union of two diamonds with equal dimension that is displaced by vector (1, 1) forms the same diamond with its width increased by 1.
So, the solution is to keep track the dimension of the diamond, starting from a 1x1 diamond. Then, simply return width * height.
Reference: See 1631223 by Endagorion (my favorite CF author! :) ).
Problem B
Author: dolphinigle
Geometry
Since there are at least one flamingo, all binoculars will be able to see at least one flamingo. When a binocular is able to see more than one flamingos, then those two flamingos and the binocular must form a line. How many such lines are there?
Instead of iterating for each pair of binocular and flamingo, we iterate over each pair of flamingos. These two pair of flamingos completely determine the line as described above. If there does not exists a binocular in this line, we can ignore this pair and continue. Otherwise, calculate the number of flamingos in this line, and let it be one of the possible number of flamingos visible from that binocular.
After this is done, simply sum the maximum number of flamingos of each binocular. This works in O(M^3). Note that this problem can be made to run in O(M^2 log M), but coding that solution is sort of... boring ;3.
For instance, see vepifanov's 1631294
- Remarks
Actually havaliza prepared a much nicer B problem. Unfortunately, we found out at the last moments that the problem may be too similar to a problem (that is used a looooooooong time ago), so we decided to switch that problem with something else. And that's why this problem is here.
It's too bad, the problem proposed by havaliza is actually very nice. Perhaps we will see it in one of the upcoming rounds :)
Problem C
Author: dolphinigle
DFS
Let's drop the (modulo K). That is, the rule becomes:
- X->Y implies that Y = X+1
- Y->X implies that Y = X-1
While we still dropping the "modulo K" thingy, we try to calculate the values of each node. We iterate over each node, and if we haven't processed the node:
- Number the node 0 (or any other number you like). let's denote this by no[i] = 0.
- DFS the node:
- DFS(X): if there exists X->Y, then no[Y] = no[X]+1. This follows from the first rule.
- DFS(X): if there exists Y->X, then no[Y] = no[X]-1. This follows from the second rule.
- If Y is renumbered (that is, the algorithm has renumber it in the past and we renumber it again), consider the difference between the two numbers. We claim that this difference, if not zero, must be a multiple of K. To see this, suppose the two numbers are A and B. By the way our algorithm works, that node must be able to be numbered A or B. Hence, A == B (mod K) must holds. But then, A-B == 0 (mod K) implies that (A-B) is a multiple of K.
- If a non-empty multiple of K (let's say it's CYCLEN) is not found in the step above, we claim that the answer is the maximum possible answer: N. Indeed if no such value is found, it means that renumbering the nodes into no[i] % N be correct, since every edge is already consistent with no[i].
- Otherwise, we can simply brute force all divisors of CYCLEN and try each of them. Since "trying" uses O(E) time (that is, by setting each number into no[i] % K and checking whether the two rules holds for all edges) , we have a O(number_of_divisors * E) algorithm, which with the given constraints is less than O(E * sqrt(N)).
For instance, sexyprincess91 implemented this. 1632321
Problem D
Author: dolphinigle
Dynamic Programming, Probabilities, and a little Greedy
Suppose we have decided to bring N1 T-shirts of size 1, N2 T-shirts of size 2, ... NM T-shirts of size M. By the linearity of expectation, the expected number of engineers that will receive a T-shirt is equal to the sum of the expected number of engineers that will receive a T-shirt of size K, for all K.
Suppose we bring Ni T-shirts of size i. Define a random variable Xij as the number of engineer that will receive the j-th T-shirt of size Ni that we bring. Hence, the expected number of engineers that will receive the Ni T-shirts of size i that we bring is equal to the sum of Xij over all j. Since Xij is either 0 or 1, Xij is equal to Pij, the probability that there will be an engineer that will receive the j-th T-shirt of size i that we bring. This is equal to the probability that there will be at least j engineers that fits inside T-shirt of size i.
As a result of our discussion, to maximize the expectation, it boils to maximizing the sum over Xij. Hence, we receive our first solution: Calculate the value of all Xij, and pick the N largest value. A DP implementation allows us to accumulate all Xij value in O(N*N*M) time, yielding an O(N*N*M) solution.
We will now reduce the time limit to O(N*N + N*M). Notice that the algorithm above only need us to find the N largest values of Xij. Denote by f(n, i, j) the probability that, amongst engineers numbere 1 through n, at least j of them fits inside T-shirt of size i. f(n, i, j) can be computed with the following recurrence: f(n, i, j) = f(n-1, i, j-1) * fit_chance(n, i) + f(n-1, i, j) * (1.0 — fit_change(n, i)) Where fit_chance(t-shirt, engineer) is the probability that engineer fits inside the t-shirt size.
The formula above can be inferred from simple logic: if the n-th engineer fits inside t-shirt of size i (with fit_change(n, i) probability), then f(n, i, j) is obviously equal to f(n-1, i, j-1). Otherwise, it'll equal f(n-1, i, j).
Now, observe that Xij = f(N, i, j). Indeed, this is one of the possible DPs that can lead to the O(N*N*M) solution. However, we will show that we do not need to compute f(n, i, j) for all possible inputs if we're asked to find only the N largest values of Xij.
The key observation is the following obvious fact. If Xij is included in the N largest values, then Xi(j-1) must also be included there. Inductively, Xik for k < j must also be included in the N largest values. Indeed, it's obvious that Xij must be non-increasing with respect to j.
Hence the algorithm works as follows. First, we create a pool of numbers Xi1, for all i, totalling M numbers. Then, we iterate N times. In each iteration, we pick the largest number in the pool, say, Xij. Then, we add Xij as one of the K largest values. Then, we take out Xij from the pool, and insert Xi(j+1) as its replacement. That it correctly picks the N largest Xij values follows immediately from our argument in the paragraph preceeding this.
Now, if we use the recurrence f(n, i, j) above to compute each Xij, what is the complexity of this algorithm? If we memoize f(n, i, j), we claim that it's O(N*N + N*M). To see this, we notice that the only values required to compute f(n, i, j) using the recurrence above are the values f(m, i, l) such that m <= n and l <= j. However, we notice that due to how our algorithm works, when we need to compute Xij, we must have already computed Xi(j-1) before, so that all values f(m, i, l) for m <= n and l <= j-1 are already available. So the only NEW values that we need to compute are f(m, i, j), m <= n. There are n such values.
Since we need to compute at most O(N) values of Xij, the total complexity this part contributes is O(N*N). Depending on how you implement the "pick largest from pool" algorithm, the total complexity can be either O(N*N + N*M) or O(N*N + N*log M).
Yes, somebody did this in the contest :). Dmitry_Egorov 1632270 saved my problem from loneliness :)
Bonus Section: Now here's an extremely interesting solution shown by the following Python pseudocode:
values = []
for size in range(M):
i = 1
while (val = f(N, size, i)) > epsilon:
values.append(val)
++i
end
end
Print the sum of the largest N values in array values.
Its correctness is immediate as long as epsilon is reasonably small (since f(N, size, i) is non-increasing with respect to i). What is the complexity of this very simple algorithm?
I am unable to come up with a hard, solid proof, but since f(N, size, i) exponentially falls (except if some probabilities are 1, in which case some other T-shirt must have less value to worry on), the complexity is somewhere near O(N * N). Indeed for the current set of test cases, its speed exceeds that of the intended solution.
Although rng_58 do not implement this exact algorithm, he used the <EPS ignore idea in his solution 1631960
Remarks
I really really wanted to link Gerald's handle in the statement :). Too bad Codeforces doesn't support it.
Problem E
Author: dolphinigle
Very greedy
Brute force P: the number of Packages each kid will have at the end. There are at most N/M possible such value. We will assume that P is fixed during our discussion.
If we know P, we know that if kid i purchases a total of X candies, then kid i+1 must purchase at least X+P candies (1 more than each package purchased by kid i). Hence, assume that money[i] <= money[i+1] — P.
Two consecutive packages purchased by the SAME kid must differ by at least M. Indeed, otherwise there are less than M-1 packages for the other M-1 kids to buy from (Pigeonhole rocks by the way).
For the sake of our discussions below, we refer to the following example with N=8, and M=3 kids. The allowances of the kids are 7, 10, and 14.
Suppose we know all candies kid 0 purchased (red bags denote the packages kid 0 purchased).

We claim that the optimal solution can be computed rather... easily with the following greedy algorithm: (assume that the candy packages kid 0 purchase is sorted in an ascending order). We iterate over the remaining kids, starting from kid 1. First, let the kid purchase the minimum possible candies:

Next, if the allowance is still greater than the sum of candies, and if one of his package(s) can still be shifted to the right while maintaining the condition that a possible solution exists, do so. If there are multiple package(s) that can be shifted, shifting any of them does not change the optimal answer.

Note: since we've assumed that money[i] <= money[i+1]-P, the only condition is that between the package purchased by kid 1 an the next package purchased by kid 0, there exists at least N-2 packages. For instance, this is illegal, since there is no package that kid 2 will be able to purchase between 4 and 5.

We iterate this once more for kid 2, obtaining:

And we're done. It's arguably the maximum possible value, since there is no reason why we shouldn't shift a package for a kid to the right if we can (formal proof by contradiction).
Claim: If we know the packages for kid 0, the maximum total candies purchased can be computed in O(M), where M is the number of kids.
The algorithm simulates our discussion above. However it is not obvious how to do that in O(M). So, suppose kid 0 purchase the candies like this:

Now, try putting the other P-1 packages into the minimum possible locations:

The packages inside the yellow boxes denote what we will call FREEDOM. Basically FREEDOM is the count on how many times we can at most shift a package to the right as in our discussion above.
Now, consider kid 1. First, as in our discussion, kid 1 takes the minimum amount of packages, which is equal to sum[kid 0] + P. Next, he will attempt to shift the packages if possible. Notice that the only thing that affects the overall sum of the candy is only the number of shifts performed, not which package actually got shifted. So, this means that, the amount of shift can be easily calculated by min(money[1] — (sum[kid 0] + P), FREEDOM). And then, FREEDOM is deducted from this value, while the amount of candies purchased by kid 1 is incremented by this value.
Hence, simulating the algorithm in our discussion if we're only to output the total amount of candies can be done in O(M).
The result of our discussion so far is this. Notice that the last algorithm only depends on how many candies kid 0 purchased, and FREEDOM.
Now we will remove the assumption that we know which packages kid 0 decides to purchase.
Claim: It is optimal for kid 0 to purchase as many candies as possible.
Suppose kid 0 does not purchase the maximum possible of candies he can purchase. Now, consider whether or not kid 1 "shifted" his candies.
- If he shifted any of them, say package X, then instead of purchasing package X-1, kid 0 should purchase package X, improving the overall amount of candies. That is, instead of

It's better to

- If kid 1 did not "shift" his candies because the amount of money he spent is already equal to his allowance, then the amount of candies purchased by kid 0 must be maximum since money[i] <= money[i+1] — P.
- Otherwise, we can apply this inductively to kid 2 and so forth. That is, instead of

It's better to

Okay, now we know the sum of candies that we should give to kid 1. Since the performance of our algorithm increase with FREEDOM, we should next try to maximize FREEDOM.
Claim: FREEDOM depends only on the position of the FIRST candy package purchased by kid 0.
This can be shown by simple computation, and its equal to N — pos — M*P (or something like that).
Hence, we should try to minimize the first candy package purchased by kid 0, while keeping the sum maximum. This can be done in O(1) using a bunch of N*(N+1)/M * P formulas.
Hence, since there are N/M package numbers to be brute forced, and each iteration uses O(M) time, the total complexity is O(N/M) * O(M) = O(N).
For instance, see 1632210 by rng_58 (again :) ).
Epilogue
Thank you for participating in the match!

Hope to see you again!







I always enjoy reading the editorials written by you, they are piece of art. Thanks a lot.
For B, should it be O(M^3) instead of O(N^3) given M represents the number of flamingos? I really would like to know the detail of O(M^2 log M), would you explain it?
It would be handy if links to problems were added. Please post your solutions if possible.
Sorry I made this in a rather hurry. I'll add reference solutions today (if any).
UPD: the idea is to group "pairs of lines" with the same gradient and sort them. This way we are able to obtain for each pair of lines, number of dots that lies in this line.
I haven't grasped the idea yet. For the first part, to get groups of "pairs of lines", it costs O(M^2), sorting them costs O(M^2 log M). For the second part, "we are able to obtain for each pair of lines, number of dots that lies in this line", how? if by enumerating all the M flamingos, then it will add an O(M) factor to O(M^2 log M). I guess I must misunderstood something.
After grouping them by gradient, by sorting them with pair<X, Y>, we're able to group the lines that overlaps each other in a group, all in O(M^2 log M^2)
What's the sorting function like? I mean, according to which criterion?
A line is completely determined by its gradient and its X intercept (or Y intercept if the line is horizontal). Just sort them by both of these intercepts.
Yes. The sort function will be like:
void sort(Line a, Line b) { if (a.gradient != b.gradient) return a.gradient < b.gradient; return a.intercept < b.intercept; }After sorting, each group contains lines of the same gradient but different intercepts, right? (1)
But then we still need to decide every line of each group passing through which dot, right? (2)
In one word, I just didn't understand the advantage of sorting lines.
No, after sorting, each group contains lines of the same gradient and the same intercept (or in another word, same line). So, in a arbitrary group, suppose you have K lines with the same gradient/intercept in it, then K must satisfy K = P * (P — 1) / 2, with P is the number of flamingo in that group (it means all those P flamingoes lie in the same line, right?). You can easily find that number P for each group. If the line representing that group passes through a binocular, assign that number P to that binocular, or keep the larger number if that binocular has been assigned already.
Can I translate it into Chinese in my blog , in order to let more Chinese read it more conveniently ? Of course , I'll state that It's come from here.
Of course :) Thank you for doing that :)
why can't us send our solution after the contest? neither we can read the codes you've referenced...
Looks like they are still too busy finishing the onsite competition and haven't returned the website to normal.
thanks. I've read your editorial for question A but i really don't understand why UR increases the width and UL increases the height and UDRL increases both? may someone explain it to me? actually i didn't understand your description where you said the union of shifting diamond are equal to increase the diamond's width. and actually i don't understand you about shifting it. what do you mean about shifting? if you shift the diamond containing only 0, 0 to up then right it'll create a triangle not a diamond
What if in problem C instead of finding one multiple of K we just find all of them using your algorithm and then we say that answer is the greatest common divisor of them?
Then complexity will be O(N * log(M)).
Then it also should be correct :). But it's somewhat harder to proof (we need to proof that every smallest cycle = cycle that does not contain smaller cycle, are detected by our algorithm).
Quite easy to prove actually. Let's consider some fixed K. We do a DFS, dividing the edges in two groups: tree edges (edges to unvisited vertices) and non-tree edges (to visited vertices). Tree edges are used to set no[p]=(no[v]+-1)%K (where + or — is chosen based on edge direction). Non-tree edges force conditions no[p]==(no[v]+-1)%K. We can drop %K at this stage and just assign no[p]=no[v]+-1. Then non-tree edges leave us with a set of conditions of the form no[p]%K=(no[v]+-1)%K, which is the same as K%(no[p]-(no[v]+-1))=0. This set of conditions is the only restriction for K, so we can choose K as GCD of all (no[p]-(no[v]+-1)). My solution is quite short (ignore struct vec in the beginning).
I think problem B can be solved also in O(M^2). Am I right? Here's my idea (which is pretty similar to the editorial):
Use a hash-map to map a line (represented as a pair binocular-slope) to the set of birds it passes through. In the map, we include only those lines that pass through one binocular, and two or more birds. We build the map by scanning all pairs of birds, so it takes O(M^2), assuming that adding a key to the map, or two birds to a set, takes constant time.
Scan the map. For each binocular found in the map, pick the size of the largest set it is mapped to. The map has at most O(M^2) keys.
I disagree with this statement. Consider next input:
4 4
1 2
1 3
2 4
3 4
Here vertexes 2 and 3 must have the same number. So the total number of different colors we can use is 3. As for me it is much more natural to have correct answer 3 for this input rather than 4.
P.S. Sorry, I misunderstood meaning of no[i]. But it is still not natural :)
This problem is also solvable if we ask each color to be used at least once. But on the previous wording, that option makes the statement look strange. This new rewording was created like, contest minus 8 hours so I thought it would be bad if we would also change the solution.
Am I the one that don't have access to submissions?
It says "Access denied"
This has been fixed. Sorry for the delay.