


Topcoder SRM 712
Time: 7:00 am EDT Tuesday, April 18, 2017
Calendar: https://www.topcoder.com/community/events/
There are 3 more SRMs on schedule:
- 713 Wed April 26, 9pm
- 714 Thursday May 11, 11am
- 715 Tuesday May 30, 9pm
I will add them tomorrow since 'You can create no more than 3 blog entries per day'.






Auto comment: topic has been updated by cgy4ever (previous revision, new revision, compare).
Contest will start in 18 hours.
Will start in 4 hours, and that means the registration is open now.
Looks like the 600 problem is very similar to this problem: LINK
I don't think it's even simillar. The limits are different, and we are calculating "variance", not "mean".
How to solve Div. 2 1000 ?
Can anyone please explain solution for Div1 600? TIA.
Let's take a look at a subtree consisting of N nodes whose values are X1, X2,..., XN. The variance of this subtree is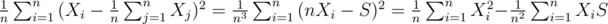 where
where 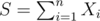 . Which means, whenever a node i belongs to a subtree of size N, it contributes to the "final answer"
. Which means, whenever a node i belongs to a subtree of size N, it contributes to the "final answer" 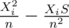 (here the "final answer" means the sum of variances over all subtrees, not the average one). Hence, iterate over all node i in the tree, the problem now changes to Find the number of subtree of size j containing the node i, and the sum of values of all nodes over all such subtrees.
(here the "final answer" means the sum of variances over all subtrees, not the average one). Hence, iterate over all node i in the tree, the problem now changes to Find the number of subtree of size j containing the node i, and the sum of values of all nodes over all such subtrees.
But S changes when we change subtree. Shouldn't we iterate over pairs of vertices and compute number of subtrees containing both of them?
Hmmm. I think my idea is appropriate with my thinking flow and the found solution is not hard to implement. Btw, could you tell me more in details about your idea?
You defined S here for each subtree.
If you mean S = Sigma(Xi), then I think it contradicts with your definition before.
Btw it's good to share solutions, but if you didn't verified it, please let people know that it is not verified. (By "verifying" I mean AC, or something better)
Ok, I didn't notice that what you did was to state a reduction, not a whole solution. This looks good to me, but it still is not trivial how complete the solution (but definitely doable, I did very similar thing)
var(X) = E(x^2) — E^2(x)
I realized it too late, I should have given my probabilities classes in college more attention :(
Same here xD
I would have realized it faster if he didn't mention the other rule :D
Can you explain what is the approach for 1000 pointer?
yaswanth Sure.
I will tell you my idea, but I didn't implement it yet.
We need to sum the variances where a variance of a sequence S = s1, s2, ..., sn = VAR(X) = E[(si)^2] — E^2[si].
So if we have k sequences S1, S2, S3, ... , Sk
The answer will be = ( ∑ (E[Sij^2] — E^2[Sij]) ) / k = (∑ E[Sij^2] — ∑ E^2[Sij]) / k So we need to know four things :
1- To Know all the Sequences we can make.
2- How to compute E[X] for a Sequence.
3- How to compute E[X ^ 2] for a Sequence.
4- The number of Sequences K.
Ok, Let's Sort the Array and call it A. Now for every A[i], Consider all the Sequences that ends with A[i]. Get the smallest j where j <= i and A[i] — A[j] <= R (The index of the smallest element we can include in a set where A[i] is in) and Call that index Left, and call our index i (Right). So know we want to get ∑E[X] for all the sequences that ends with Right, ∑E[X ^ 2] for all the sequences that ends with Right, number of Sequences K that ends with Right.
If we got these 3 things then the problem is solved.
So I will tell you how to compute The total number of sequences K, ∑E[X] for all sequences that ends with Right and you should be able to continue from there.
So now we fixed Right and for sure any element between indices : [Left, Right — 1] may be included in our sequence and may not, so the total number of sequences here are :
K = 2 ^ ( (Right — 1) — Left + 1).
now I will tell you how to compute E[X] for this sequence S = s1, s2, ..., sm.
for sure s1 < s2 < s3 < ... < sm
You can solve it using dynamic programming. The state would be (curIdx, endIdx, left).
curIdx it the idx of the element you are deciding currently to take it or not (for sure you will add both ways to the answer).
endIdx is the last element you can take.
left is the # of remaining numbers you need to take.
Now what is E[x] for this Sequence S = s1, s2, s3, ... , sm (∑ (i : 0 -> m)) dp(1, m, i).
Which means that I will try to include 0, 1, 2, 3, ..., m Elements from this array.
BTW by S I mean the elements from Left to Right — 1.
Thanks Omar. I have a question. So using dp we have got the sum of means of all the subsets of S. Meaning we have got E1 + E2 + ... Ek. But we have to calculate E1^2 + E2^2 + ... Ek^2. How do we do that?
Use the above DP in computing E(X ^ 2), it should be easy now.
For ∑ E^[X] let's state the problem.
Suppose that we have an array A = [a1, a2, ... , an] For Every Subsequence S = [s1, s2, s3, ..., sm] from A we need to find E^2[X] for that sequence which is ( ∑si/m ) ^ 2, which is ∑si^2 / m^2, So now you can use the same DP, for every element you may take si ^ 2 or you may not.
I got how to compute E(X^2). That's a straight forward dp. For (E[X])^2, how does dp work? I mean E[X] = (s1 + s2 + ... sm) / m. m varies for each subsequence. Moreover, it is (s1 + s2 + ... sm)^2. How do we calculate the next state from this? Can you elaborate on this dp?
Thx a lot!
I always want to write brute force simulation of states immediately, today I resist doing so, but it turns out this is the exact thing to do for D1 300. So much time wasted for nothing :(
I think people who brute on A will all got TL. So don't worry.
I think if you memoize the states brute force can pass also as there are ≤ N states per level.
I tested, it seems to me on any test I generate there are <1600 distinct states visited. That is you can not create more than 1600 valid arrays starting from S, thus if we just do BFS and keep track of already visited states, solution is very fast. If you have counterexample or theory why not I would be happy to see :)
I can prove an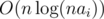 bound on the number of states.
bound on the number of states.
Handle the case when the sum of either array is 0 separately.
Let S be the sum of first array and T be the sum of second. Note that the operation multiplies the sum by 2 on each step, so we must end in at most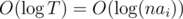 steps.
steps.
Now, for each step, we can have at most n distinct states. To see why, we note that the set of values we obtain will be the same no matter whether we use L or R. In fact, the states of each level are only cyclic shifts of each other. Thus, there are at most n states per level.
This proves the bound.
the operation is commutative anyways so the number of distinct states visited will be very less.
If we look at sequence a0, a1, ..., an - 1 as a polynomial a0x0 + a1x1 + ... + an - 1xn - 1, then operations are just multiplication by 1 + x and 1 + xn - 1 modulo xn - 1, so they commute. Because of that there will be only 100 + 99 + ... + 0 states (only number of operations of each type matters, not their order) at most and actually much less.
UPD. Fixed an error. Thanks to Swistakk.
Modulo xn - 1, not modulo xn : D
Oh I didn't thought about memoization... I said that because I hacked two codes without memoization.
And yes there are at most 2000 states. This is because LR is equivalent to RL. so just like bubble sort, you can transform the sequence as LLLLL...RRRRR.... and get same results. (actually this observation results in short O(lg(n*ai)^3) solution)
"There is an issue with one of the problems, which we are working on addressing. It may be several hours. We will post results when we are able."
Will it be rated?
Petr challenged my solution of Div1-Medium and we just have a fix.
Now we are running system test. Maybe there are some challenges were affected, but it should be rated.
The test case is:
And output should be around 0.0022541745919277614
Sorry for the inconvenience and thanks Petr for finding that.
Maybe you forgot to write: this is a precision issue.
The easiest solution is O(N4), but I guess it can be improved to O(N2) (I'm not very confident right now). Then, we can use slow BigDecimal to compute more precise answers.
Are there other ways to get a solution with high precision?
I'm using BigDecimal, but looks like Petr didn't use it and still can produce correct result. (The key is divide number of subtrees for each term, instead of divide it in the end). (Edit: No, tried and this can't work)
Actually, my trick is to subtract the mean from all weights in the beginning.
Could you share your code in copypastable format?
Thanks.
Wasn't able to get an error anything close to 1e-9
Here's a rough argument why this trick is enough:
Suppose maximum absolute value of a weight after shifting the mean to 0 is x. Then there exists an edge in the tree with difference in weights of ends of at least x/50. Both ends of this edge belong to at least ~1/50 of all trees (to see that, take any tree that doesn't have them, and add the shortest path to them with them; at most ~50 trees would merge into one here). So at least 1/50 of all trees would have a variance of at least (x/100)*(x/100)*2/50, which means that the return value will be at least x**2/12500000. On the other hand, the "positive" component of the formula is at most x**2, so the most precision we can lose by subtraction is on the scale of 1e7*machine_eps=1e7*1e-16=1e-9. Of course all bounds above were super generous, and in reality the loss is much less than 1e-9.
My solution writes each term of the sums as Integer + Float, where 0 <= Float < 1, then sums them by 'components', as in all Integers are summed into a __int128, while all Floats into a double. Since the Floats are of form a/b for b <= 50^2 I assumed it would be enough to get high enough precision :\
Is it connected to fact that equality Var=EX^2-(EX)^2 introduces big cancellation errors? Does it mean that most of solutions will fail systests? I thought that it should be a good idea for setters to request computing it modulo some prime.
Yes, basically when we do subtraction of two big numbers, the relative error can be huge. (Even we try the case where all weights are 10^9, we will output something much larger than 0).
Somehow when I did the analysis I thought we are just adding O(n^2) numbers and that should be fine. And I didn't test it thoroughly.
Btw, seems reducing weights to 1000 should be enough for avoid precision error.
There will be another problem: suppose that we have to compute it modulo p = 1e9+7, then the number of trees coulde be equal to p. In that case if the numerator of our huge fraction is also divisible by p, then we should know this numerator mod p^2... I guess bignums are needed in that case.
Uh, but that can be disregarded in few ways. Either guaranteeing denominator will not be divisible by P, or requesting to output 0 in that case (or setting P to something larger than 2^P xD)
Better way is to print sum of variance for all possible subtrees, rather than expectation. This don't change the problem significantly, and also a / b is always divisible.
Another problem is that debugging can be harder. For example everyone knows 0.4 is 2/5, but it takes some time to understand that 800000006 is 2/5.
Was 10^-9 precision necessary? or was it intentional (so making this problem "challenging")? I just don't understand the reason behind such tight bounds
And I don't understand the authors not proving precision in their double solutions.
cgy did that but did a mistake. And proving precision is terrible thing to do ;__;. And tight bounds always suck. IMHO doubles should be used only in problems without subtraction / division or when no possible way of doing it modulo P exists.
I'm the kind of person who always say "prove this! prove that!" but still I ignore precision issues (unless I use epsilons for comparisons). Though I know it's not a very good thing. Do you know how to prove precisions?
Yes. There's quite elaborate theory in terms of relative error and machine epsilon. For example, one can estimate relative precision of d-dimensional dot-product (or Sigma(X^2) or like) as (d+1)*machine_epsilon. In this problem one may deduce something like O(poly(n)*machine_epsilon), n is the tree size. It seems 10^-9 may not be enough precision, if computations are held in double, that is 10^-14, and we assume (it's not proof) poly(n)=O(n^3) or higher degree, max n = 50.
Details on general theory look, for example, in the book Applied numerical linear algebra by James Demmel.
The problem here is not the error slowly accumulating over the last bits. It is catastrophic cancellation. So, at some step, the analysis must take the magnitude of input values (or input precision) into account.
For example, if the given weights were integers up to 1000, not to 109, the whole precision issue would most likely be gone.
I agree. I believe there exists solution with +/* operations only, i.e. cumulative DP possibly with increased complexity, but I have not come up with a correct one at the moment. It's interesting to see such a solution, if one exists.
The 1e-9 comes by default — so if we want to override it into 1e-6 we need to write checkAnswer(), and when we don't think that is necessary we use 1e-9.
Btw even we change the precision to 1.0 lots of solution will still fail.
Would it be possible to change default value to 1e-4 or 1e-6? I think 1e-9 is a very strict precision tolerance and it is really not fun to reject solutions that differ from correct answer by 1e-8 instead of 1e-9. What would be cons of such decision?
Hmm I don't know why it is 1e-9, that decision was made before I can write Hello World.
And I agree that maybe 1e-6 is a better solution.
Btw, it is still much better than output 6 digits after the decimal points and then compare strings — I used one task in local OI contest many years ago that the answer is something like 0.12345650000000000001, so in order to get 6 digits right you need to be accurate for 1e-20.
So what's the point? I changed long double to float128 and got AC.
I was tester this time, so that's my fault too.
I implemented python solution (code) and I wrongly assumed it has enough precision and that's not an issue at all.
Sorry for that.
Probably good idea to stress solution with solution using double-precision decimals or ask answer by modulo. I like second way more.
I think this time the key is to consider that corner cases. Our solution are wrong but they will give out different result and that is enough to catch the precision error. And if we test the case that all weights are 1e9 we can easily know our solutions are wrong.
I did the stress test with random weights between 1 and 1e9 and our solution can always agree.
Rank 14, yanQval has 299.84 points in the 300 pointer. Does it seem legit?
What is the intended solution for 900pts?
I implemented a very complicated solution (like something in each node in the tree, we color related nodes in two colors and use knapsack to distribute the connect components into two subtrees). And I think it worth more than 900pts.
That's what I thought about too, but when I saw that I need to use knapsack too, I gave up. To do it, were you solving the problem first for subtrees of nodes that have maximum height and appear as a c in some of the constraints? That was my idea but I thought that having just 900 points, it was impossible to be that difficult
Yes, I think it's exactly what I implemented. I didn't finish it during the contest time. And I failed in the practice room once because of a corner case.
I think it is really difficult to pass using this solution during the contest.
Wow, I thought about this solution and suggested 900 to be too easy.) What's the problem with knapsack?
If you're asking me, there was no problem, except for the fact that I already had 150 lines of cod at the time I realized knapsack was needed. It's not the algorithm itself, but the overall implementation was really hard to code. It's true that the idea itself is not very hard, but the implementation was close to being impossible. The problem was nice, but hard to code, at least for me. 900 is not too much for the idea, but too little for the time spent coding on it
I agree with you, I was coding this solution too, I had about half an hour for that during the contest, but I think I needed at least half an hour more.
I think it was unnecessary to say anything about length of result in 300pts (or change 100 to 1e5). I think it would be interesting part of solving that problem to note that result is always short.
Also this:
For 1e5, I/O would be a bottleneck. Input or output of more than a few thousand values would probably hit some internal limitations of the contest platform. At least that was the case a year or two ago.
How to solve div2 1000 ?
Waiting for Editorial. Is it available?
How to solve div1 250 ?
Both operations are commutative. ( Order does not matter like Multiplication). It is the number of L's and R's in the String that matter. ( To get an idea why is this correct, see how applying operations on {x,y,z} gets you to).
Answer will overflow very quickly however because each operation doubles the sum of S, so you need to prune "No solution" cases or you will get wrong answer because sometimes overflow will make them equal. I think this is the reason of most failed system tests or challenges.
How will you generate test cases to hack solutions that did not check for overflow, and numbers become equal eventually?
No idea but my solution originally failed in the contest. After some time debugging, I took care of overflow, and AC. I was failing on {1,0} {0,0}.
If someone can explain how, it would be very interesting. I originally thought the probability was very low so didn't handle it. ( << so stupid).
Input some arbitrary vector s (preferably of size 2) into an overflow solution and print the vector after each operation. You'll get a working vector t very quickly.
It's easier than that, just put s = {1,1} and t={0,0}, every time elements of s double and after 64 operations of either L or R, s={2^64,2^64} in long long which is {0,0}.
Who is yanQval? He is 14th-place in this SRM with taking 299.84pts in Div1 300pts, so it means only 40 seconds to solve.
I think it is impossible without cheating, but is it really OK?
can anyone explain Petr's solution for div 1 300?