


Задача A. Письма долгого хранения.
В данной задаче требовалось просто просимулировать описанный в условии процесс. Например, можно в любой структуре данных (массив, очередь, дерево) поддерживать множество ещё не обработанных писем и по очереди рассматривать все моменты времени. При рассмотрении момент времени x сначала проверяем, есть ли новое входящее письмо, и, если да, то добавляем его в структуру. Далее проверяем, не наступило ли хотя бы одно из условий, при которых Бомбослава разбирает почту. Для симулирования разбора почты вычисляем число k и последовательно вынимаем k наиболее старых писем из структуры. Даже самая простая реализация этого процесса будет работать за время O(nT).
Упражнение: решите задачу за время O(n).
Задача B. Девчата против автомата.
Для начала заметим, что если Дуся и Люся поделят число n на x и n - x, то они получат в качестве сдачи ровно такой же набор банкнот, как если поделят n на x + 5000 и n - x - 5000. Таким образом, достаточно будет только проверить всем способы разбиения, где x проходит диапазон от a до min(a + 5000, n - a). Для каждого способа вычислим сдачу за время O(1) по следующей формуле: если какая-либо из девушек хочет заплатить величину y, то размер полезной сдачи будет (5000k - y) mod 500, где 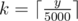 .
.
Упражнение: докажите, что достаточно перебрать значения x в диапазоне от a до min(a + 499, n - a) включительно.
Задача C. Эффективный менеджмент возвращается.
Существует множество различных решений данной задачи, и почти любое из них уложится в ограничение по времени, поскольку в ответе будет использовано не более 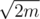 команд (упражнение: доказать это утверждение). Данный разбор будет содержать описание одного из возможных линейных решений.
команд (упражнение: доказать это утверждение). Данный разбор будет содержать описание одного из возможных линейных решений.
Будем добавлять вершины графа по одной. После рассмотрения первых i - 1 вершин (v1, v2, ..., vi - 1) мы будем поддерживать распределение их между ki командами T1, T2, ..., Tki, так что все указанные в условии задачи ограничения выполнены. При добавлении вершины vi найдём любую команду Tj, такую что не существует вершины  and
and  . Полагая
. Полагая 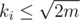 это может быть легко реализовано за время
это может быть легко реализовано за время 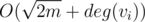 просто с использованием массива булевых пометок и проходом по списку соседей вершины. Если подходящего Tj не существует, то положим ki + 1 = ki + 1, то есть создадим для данной вершины отдельную команду. На самом деле, нам не требуется использовать факт про то, что количество команд есть
просто с использованием массива булевых пометок и проходом по списку соседей вершины. Если подходящего Tj не существует, то положим ki + 1 = ki + 1, то есть создадим для данной вершины отдельную команду. На самом деле, нам не требуется использовать факт про то, что количество команд есть 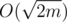 , поскольку вместо обнуления булевого массива мы можем использовать массив специальных пометок. За время O(deg(vi)) расставим пометки всем соединённым с данной вершиной командам, а потом просто пройдём по массиву до тех пор, пока не найдём непомеченную команду. Разумеется, при выполнении этой части будет просмотрено не более deg(vi) + 1 элементов массива и вообще при добавлении вершины будет сделано O(deg(vi)) действий. Таким образом, суммарное время работы есть O(n + m).
, поскольку вместо обнуления булевого массива мы можем использовать массив специальных пометок. За время O(deg(vi)) расставим пометки всем соединённым с данной вершиной командам, а потом просто пройдём по массиву до тех пор, пока не найдём непомеченную команду. Разумеется, при выполнении этой части будет просмотрено не более deg(vi) + 1 элементов массива и вообще при добавлении вершины будет сделано O(deg(vi)) действий. Таким образом, суммарное время работы есть O(n + m).
Задача D. Афера.
Для начала будем несколько иначе воспринимать все ставки. Определим ci = ai + bi, тогда принимая ставку i мы можем считать, что получаем доход bi и должны будем выплатить ci в случае наступления соответствующего исхода. Определим A как некоторое подмножество ставок, 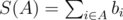 , то есть итоговый доход с данного подмножества без учёта возможных выплат. L(A) положим равному суммарным выплатам, если команда проиграет, то есть
, то есть итоговый доход с данного подмножества без учёта возможных выплат. L(A) положим равному суммарным выплатам, если команда проиграет, то есть  . Аналогично введём величины D(A) и W(A), тогда гарантированный доход Остапа с подмножества A равен S(A) - max(L(A), D(A), W(A)).
. Аналогично введём величины D(A) и W(A), тогда гарантированный доход Остапа с подмножества A равен S(A) - max(L(A), D(A), W(A)).
В данном виде пока ещё непонятно как решать задачу, поскольку требуется с одной стороны увеличивать S(A), и минимизировать максимум с другой стороны. Зафиксируем max(L(A), D(A), W(A)) = k, тогда задача звучит как: какова максимальная стоимость по bi подмножества ставок с исходом "поражение" ("ничья", "победа"), которое можно принять так чтобы сумма их ci не превосходила k. Соответствующие значения 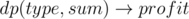 можно независимо посчитать для каждого исхода с помощью динамического программирования решающего задачу о рюкзаке. Сложность такого решения будет O(nL), где
можно независимо посчитать для каждого исхода с помощью динамического программирования решающего задачу о рюкзаке. Сложность такого решения будет O(nL), где  .
.
Задача E. Случайная величина моды.
Сперва рассмотрим решение задачи за время O(n2) с помощью динамического программирования. Положим dpleft(i, j) равным оптимальному ожидаемому времени в торговом центре, если Глеб уже обошёл все магазины с i по j включительно и сейчас стоит рядом с магазином i. Аналогично положим dpright(i, j) равным оптимальному ответу если Глеб обошёл магазины с i по j и стоит около магазина j.
Мы не будем приводить всех формул в данном разборе, но, например, dpleft(i, j) может быть вычислено как минимум из двух возможных переходов (в i - 1 или j + 1) следующим образом:
,
Для ускорения решения задачи заметим, что если не существует магазинов с pi = 0, то мы посетим большое количество магазинов с очень маленькой вероятностью, поскольку уже вероятность в один процент, то есть 0.01 является достаточно большой. Вероятность посетить k магазинов с pi > 0 и всё ещё не найти подходящий плащ составляет 0.99k, что для k = 5000 составит порядка 1.5·10 - 22. используя что ti ≤ 1000 и n ≤ 300 000 получаем, что на посещение всего торгового центра потребуется не более 109 секунд, то есть уже при k = 5000 влияние на ответ составит не более 10 - 12. На самом деле, учитывая, что нам разрешается допустить относительную ошибку 10 - 6 достаточно будет k = 3000.
Теперь найдём не более k магазинов с pi > 0 и i < x и не более k магазинов с pi > 0 и i > x (то есть слева и справа от стартового). Далее сожмём магазины с pi = 0 и применим квадратичную динамику. Итоговое время работы составит O(n + k2).
Задача F. Семь раз отмерь, один раз раздели.
Каждой вершине требуется назначить неотрицательное целое число xv равное номеру итерации описанного в условии процесса, на которой данная вершина будет удалена. По причинам, которые станут понятны читателю в дальнейшем, мы будем считать, что xv = 0 означает удаление на самой последней итерации, то есть б**о**льшие значение x будут соответствовать более ранним итерациям процесса. Можно показать, что фиксированные значения xv корректно описывают процесс, если и только если для любых двух вершин u и v, таких что xu = xv максимальное значение xw по всем w лежащим на пути от u до v больше xu. Другими словами, наличие на любом пути между двумя одинаковыми значениями другого значения, которое больше их обоих, означает, что любые две вершины, удаляемые на одном шаге, будут к этому моменту находиться в разных компонентах.
Выберем любую вершину в качестве корня дерева. Обозначим через C(v) множество непосредственных детей вершины v, а через S(v)~--- поддерево вершины v. Теперь, если в поддереве v уже зафиксирована некоторая корректная расстановка значений x, то нас интересуют только те xu, 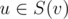 , которые ещё никем не перекрыты, то есть на пути от u до вершины корня поддерева (вершины v) нет значения больше xu. Через d(v, mask) обозначим булево значение, возможно ли так расставить x в поддереве вершины v, чтобы незакрытыми оставались только значения из множества mask. Поскольку благодаря центроидной декомпозиции мы знаем, что величина ответа не превзойдёт
, которые ещё никем не перекрыты, то есть на пути от u до вершины корня поддерева (вершины v) нет значения больше xu. Через d(v, mask) обозначим булево значение, возможно ли так расставить x в поддереве вершины v, чтобы незакрытыми оставались только значения из множества mask. Поскольку благодаря центроидной декомпозиции мы знаем, что величина ответа не превзойдёт  , то интересных значений mask не более
, то интересных значений mask не более 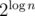 , то есть O(n). Значения d(v, mask) можно вычислить если известны d(u, mask) для всех
, то есть O(n). Значения d(v, mask) можно вычислить если известны d(u, mask) для всех 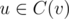 за время O(n3) используя следующие соображения (обозначим через u1, u2, ... детей из C(v), а через m1, m2, ... рассматриваемые в них значения динамики):
за время O(n3) используя следующие соображения (обозначим через u1, u2, ... детей из C(v), а через m1, m2, ... рассматриваемые в них значения динамики):
- Значение xv должно быть больше любого i, которое встречается более чем в одной маске mi.
- Значение xv должно быть равно какому-нибудь i, которое не встречается ни в одной mi.
- Если мы положим xv = i, то все j < i будут равны 0 в m.
Заметим, что согласно описанному выше процессу если маска m1 является подмаской m2, то она всегда лучше влияет на ответ, чем m2. Теперь мы утверждаем, что если рассмотреть минимальное m, такое что d(v, m) = true, то для любой m1 > m найдётся m2 подмаска m1, такая что d(v, m2) = true. В самом деле, рассмотрим первый (старший) бит i, в котором m и m1 отличаются. Поскольку m1 больше m, то в этой позиции у неё будет записано 1, а у m будет записан 0. Если после этого в m вообще нет 1, то она сама является подмаской m1, в противном случае это означает, что xv < i. Выставим xv = i и получим подмаску m1.
Доказанное выше означает, что достаточно только рассмотреть лексикографически минимальную маску, которую можно получить в каждом из поддеревьев S(v). Для этого будем объединять ответы по всем используя вышеописанную процедуру. Такое решение может быть легко реализовано за время  или даже O(n) при эффективном использовании битовых операций.
или даже O(n) при эффективном использовании битовых операций.






Deleted because of low rating. You have really disappointed me in that newcomers can't even ask for help for the simplest problems. Not everyone wants to look for solutions for the hardest problems, when they struggle even with the simplest ones.
suppose array is [0, 1, 2]
you will print 0, then remove it (getting [1,2]) and then print [2] (index 1 currently)
In problem D, the total time complexity is O(n*L), the iteration through k takes O(L), so, the dp should be calculated in O(n), is that right? but how to finish dp in O(n)?
First you calculate DP in O(nL) then iterate through k and try to update answer. link
Thanks a lot! (๑•̀ㅂ•́)و✧
Кто-нибудь умненький может объяснить переходы ДП по задаче E?
feels bad to be тупенький :С Еще и дизлайкают
Автокомментарий: текст был переведен пользователем GlebsHP (оригинальная версия, переведенная версия, сравнить).
For implementation details of C and D: https://www.youtube.com/watch?v=_ZUyzpOMMXw (Screencast by Petr) Very Helpful!!!