


Hello CodeForces community,
SnackDown 2017 Pre-Elimination Rounds have finally concluded. We saw over 12K teams joining us for the Pre-Elimination Rounds, out of which 3403 teams (who were in top 1000 ranks of each of the Pre-Elimination Rounds) have been qualified for the Elimination Round.
Now, while we prepare to step into the Elimination Round, I would like to introduce the problem setting panel for the contest.
Problem setters: arjunarul (Arjun Arul), kingofnumbers (Hasan Jaddouh),Pepe.Chess (Hussain Kara Fallah), nssprogrammer (Snighda Chandan), Mediocrity (Fedor Korobeinkov), mgch (Misha Chorniy), fudail225 (Fudail Hasan)
Problem testers: kingofnumbers (Hasan Jaddouh), mgch (Misha Chorniy), Mediocrity (Fedor Korobeinkov), Alex_2oo8 (Alexey Zayakin)
Translators: Mandarin : huzecong (Hu Zecong), Russian : CherryTree (Sergey Kulik), Vietnamese : VNOI team.
Contest Admin: PraveenDhinwa (Praveen Dhinwa)
I thank each and everyone of them for their contribution in preparing the problem set.
Given below are the details of the contest
- Start Time: Saturday, 3rd June 2017, 1930 hrs IST. (Indian Standard Time +5:30 GMT). Check your timezone here.
- Duration:: 5 hrs
- Contest link: https://www.codechef.com/SNCKEL17
Additionally, we are also conducting a replay round of the Elimination Round for the rest of the community. It will take place at https://www.codechef.com/SNEL17RP and the top three winners of the contest will win cool SnackDown 2017 t-shirts. I would take this opportunity to invite the entire community to come and join us for the Replay of SnackDown 2017 Elimination Round.
Details of the SnackDown 2017 Elimination Round Replay:
- Contest link: https://www.codechef.com/SNEL17RP
- Start Date & time: Sunday, 4th June 2017, 2100 hrs IST. (Indian Standard Time +5:30 GMT) Check your timezone here.
- Duration: 5 hrs
Accepted Languages: https://www.codechef.com/wiki/list-compilers
Note: The Elimination Round will follow ACM ICPC style ranklist.
We hope you will enjoy the problems and we welcome your feedback in the comments below.
Good Luck!






How many problems will there be?
The admin preferred not to reveal number of problems.
additional information:
1- the contest will have ACM rules.
2- multiple machines for one team is allowed.
Thank you for information. I suppose, there will be about 9-13 problems (because of duration in 5h, ACM ICPC rules and permition to multiple computers).
n = 1 case in Add or Multiply problem... I got 10 WA for that!
I solved 2 problems, what do you think, is this good for my color?
I think thats pretty good, congrats mate. :)
Thanks :)
Just curiously, did you participated, if yes, how many problems you solved? :)
My team did 5.
Wow, that's really good!
Just curious, were tourist and qwerty787788 participating both or just one of them? or maybe participating while driving? (just curious) :D
Both. You can see solutions in Java and C++ for different problems.
seems they were driving or using ipad
What makes you say that?
tourist and qwerty787788 didn't come first. Thats strange :D
I'd not to say so because of many very strong teams, which participated here. Not that mess_compress was weaker than somebody, but it's really hard to win with so strong rivals.
people said the same before WF 2015 and WF 2013. but they won easily. so it is strange when they dont win.
If wasting of 20-30 hours per week for training/upsolving == easily, then yes, they win easily.
And, FYI, there was much more strong teams comparatively with any WF because there was no age (or any other) restrictions.
Finally, these guys (as any other top team) shouldn't play on the full strength, because final round don't require top places.
Replay round in tomorrow, so we can't discuss and no editorials, right?
EDIT: We can look at submissions anyway
But we can see solutions of other people...
You can discuss the problems now. The editorials will be provided after the reply round.
How to solve ANCESTOR ?
Hints:
Calculate the eulerian tours of both trees
Now the problem is like finding intersections of prefixes
It's like a euler tour on trees technique. First, So we keep starting and ending time of each node in the first tree. Now, when we are doing dfs on the second tree, so while visiting a particular node say x, we will add 1 to all the nodes who are in the subtree of x in the first tree, i.e add 1 to all the nodes whose starting time > start[x] and ending time ≤ end[x] [Remember start[x] and end[x] are for the x in the dfs of first tree]. We can do this with BIT, and when we're done with dfs of x in second tree, we will reverse the operations i.e. add - 1 to the above stated nodes for x. So, answer for a particular node i will value of 1's added to start[i].
I have a little different approache for the task. We can calculate eulerian tours for both trees, than we will have four different times for each node : (start1, end1), (start2 , end2) — coming and leaving times for both trees. Now let's represent each node as point in the plane with coordinates x=start1 and y = start2. We have n points in total. Also we can represent recetangle with left-bottom point (start1, start2) and right-up point (end1,end2) for all nodes x. All points (nodes) in the recetangle will have x as ancestor in both trees.
Now we need to do inverse task — calcualte amount of recentagles which contains certain point and this is known problem.
It looks like this problem: https://www.codechef.com/SNCKEL17/problems/SPCLN is almost an exact copy of this problem: https://www.codechef.com/problems/RIN
How do we get such information man? Did you solve the question previously? Just Curious.
Yes, it is the exact same question.
The editorial for problem RIN at this link : http://discuss.codechef.com/problems/RIN
has the same test case which is provided as the sample test case in https://www.codechef.com/SNCKEL17/problems/SPCLN.
Any comments from admins? For me it seems the author of yersterday's problem simply copied it from cgy4ever's problem. And it may have ruined the selection of onsite teams.
UPD Now having noticed the output format "print the average sum rounding to two digits after decimal point" I'm 100% sure that problem copying is the case. Haven't seen such an impudent copying of the problem in official competition before.
Kostroma, Currently we are investigating this possibility. We will soon notify about it.
We have confirmed that the author has deliberately copied the problem. Author's code is exactly same as that of one of the submissions in the problem RIN. Also, author's short editorial/explanation contains images that are taken from the editorial and are edited slightly. The author will be banned from Codechef problem setting. We apologize for the situation. Specifically, I feel very sad in failing to find this before the contest.
We will be taking all the submissions of problem RIN and will be applying plagiarism checking program, and after that, we'll declare the final ranking. We are again sorry for such a situation.
So you are going to ban somebody for copy-pasting solution of the original problem, aren't you? Is it fair? Is it along the codechef rules?
They are going to ban some teams for choosing the right strategy.
If I found the problem was plagiarised during the contest, I wouldn't bother wasting time to recode the solution.
Also from this: https://www.quora.com/Can-I-use-others-code-in-a-CodeChef-contest it seems fine to copy others code, as long as the code was online before the contest
No, we are not going to penalize for copy pasting if the code is authored by you and was submitted to this problem earlier, or you have provided the reference link to the solution code.
Seems that it is very bad way too. If somebody copied code from old codechef contest (even if it is not his code) it is allowed by rules of codechef, because it is open source code.
Codechef code of conduct cannot agree with you:
You're kind of correct.
Any updates about the list of finalists? The contest is just in 20-30 days, finalists need to obtain visa, book flights and so on.
We have already contacted the finalists regarding this.
I think it would be better to remove his name as the author of the problem in the problem's page.
Hi , so to me seems like a notorious coincidence. Though I have come across a similar technique in a programming article ( it was in Russian ) way back.
Don't try to fool us. It has become obvious you just copied this problem.
Btw what's the reason? They pay so much money for problems of elimination?
OK,so that article was so great, and it could predict which sample test case you would use in this contest! I googled your sample test case appending "codechef", and I found exact same problem, even with same sample test case. Do you think competitors are idiot? I respect problem setters who prepare good problems and great contest, or at least try to do so. Not a thief who just copies someone's problem and pretend to say "It's my problem!". Good job, you ruined the whole problemset, just by copying one problem!
It couldn't be more obvious :|
One of most terrible and shameful moment I've ever seen in competitive programming. CodeChef you guys are awesome
Kostroma, dotorya, PrinceOfPersia, ko_osaga
Guys, this desperate comment didn't even deserve that you bother replying it.
anyway, I expect that there will be an announcement about this issue from the admins soon.
This is not so important to me, even I didn't read problem during the round :D
But that is CodeChef mistake too... I can not believe when someone think that coder with rating 1200 can prepare the hardest task on the team div 1 round ! At least you should have tried to google it !
Yeah told kingofnumbers the same before the start of the round. But he told me that optimistic stuff of that the color is not related to the knowledge and skills, and there are people who are theoretically perfect and it's not proper to accuse him in that way.
He could have came across this problem on his job or in his research work.
Is it original problem then ?
And second thing I didn't say it is impossible at all, I said than you need to check three times before you use the problem.
You don't need to be a bug to write a hard problems. Anyone can write a HLD problem by thinking about HLD (for example).
Don't judge people by their color. Maybe he just doesn't take them seriously. I know some badasses with low ratings.
I believe creating an original maxflow problem is just on another much higher level than writing an HLD problem.
In any case, just guys who does that in the same rude way must take the consequences.
I already had discussion about judging people by their color. And I will tell agian, I do not have any bad opinion about such coders. I can not say I am not very good programmer too and I hope they will be better than me now !
But if someone has low rating, several bad contests and suggesting you the hardest task on the round, you need to check that thing at least 3 times.
nssprogrammer I am not a very good coder myself but I must say this, how did you post such a comment after getting caught? I mean, the problem needs good understanding of Min Cut Max Flow, and also, the tag of the original problem is hard! If you are that awesome, that you just recreated a problem exactly in the same way, even generated the exact same test cases, just by "having come across a RUSSIAN article WAY BACK", then I must ask, how come you are still Pupil??? A notorious coincidence, ehh???
Btw, was confused during the contest with
average energyinSPCLN(why not just the total energy), but turns out that in terms of the original problem (RIN) it actually makes much more sense to have theaverageas an output =)Approach for Waiting in Queue, anyone?
Submit on Codeforces
Where on codeforces? We've finished our source shortly after the end of the competition (well, not so shortly, maybe 25 minutes) and I'm curious whether it passes or not. However, I don't understand why there were so few AC sources. Our idea involved just a treap and some tricky information stored in it (it wasn't trivial), but still, there were much harder problems (from the point of view of their ideas) solved by more teams. Anyway, the problems were interesting and most of them were really nice. About the problem lewin has pointed out I'm not that happy, but apart from that, the contest was a complete success. Congrats!
In my opinion it was more like implementation problem for people familiar with treap and can do lazy propagation.
Store in treap not bi, but bi - i. What job will be completed first? The job with lowest index, such that bi - i ≤ 0.
If you store in each node minimum of subtree, you can determine such node by recursively going down (recursive function: if there is a possibility to go left and minimum in left is small enough, then go there; otherwise try middle element; if still not go right)
What to do when you found such node? Delete it, add some const to all elements before this node (so that it matches definition bi - i, add some const to all elements after this node, and rotate the array cyclically.
One more case. If the whole array is greater zero, then you should advance time by few whole rotations. Thing like the minimum divided by size of treap and ceiled up will do the trick.
That's exactly what we did. I think it was the only solution. However, we didn't need any sort of lazy propagation. Just storing minimum of bi — i for a subtree in the treap was enough. It's just that we considered what problems to think about next by looking which one was solved by more people and we let this one at the very end of the competition. When we read it, the solution was obvious but we didn't have time to solve it. I guess that could be a good lesson: not to judge a problem after the numbers of accepted solutions
Suppose at time moment t the queue contains people with arrival times b0, b1, ... bn - 1. If b0 ≤ t then first customer in queue will be served now, otherwise if b1 ≤ t + 1 then first customer will be moved to the end of queue and second will be served now, ..., if bn - 1 ≤ t + n - 1 and bi > t + i for all 0 ≤ i ≤ n - 2, then n-th person will be served now and all others will be moved to the end of queue, preserving their order.
If bi > t + i for all 0 ≤ i ≤ n - 1, then in seconds from t to t + n - 1 inclusive everybody gets moved to the end of queue and situation just repeats at moment t + n.
So, what happens with queue? If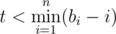 , then everything comes full circle and t is increased by n. Otherwise, we need to find the leftmost position j, such that bj - j ≤ t, process customer at that position and move everybody before that position to the end of queue (preserving order).
, then everything comes full circle and t is increased by n. Otherwise, we need to find the leftmost position j, such that bj - j ≤ t, process customer at that position and move everybody before that position to the end of queue (preserving order).
How many full circles will happen (let's call this number k)? If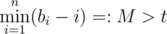 (if M ≤ t then k = 0), then exactly
(if M ≤ t then k = 0), then exactly 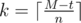 full circles will happen. To simulate them, just increase t appropriately.
full circles will happen. To simulate them, just increase t appropriately.
Now only the case when M ≤ t bothers us and we want to find smallest j such that bj - j ≤ t quickly. To do this, let's keep queue in implicit treap and in each vertex remember minimum value of bi - i in its subtree. Idea of remembering something that changes when we do operations on tree sounds kind of dangerous, but actually it is completely ok in this case. When we do merge and split we just need to do an update operation to some vertex (where info is no longer correct, but info for it children is up to date), we need to just decrease minimum in right subtree by
1 + (size of left subtree)and bi - i for root is justb - (size of left subtree). So this kind of information can be keeped while we do basic merge and split by length operations.To find smallest j that bj - j ≤ t, just do tree descend and check whether minimum of bi - i in subtree is still less than t. After that serve this customer, delete him and move all customers that stand before to the right (by splitting them out from the left and merging them on the right).
Do we really need treap?
When we delete a node x, we should add one to the values of by - y for all y > x, and set bx - x to infinity. Can't we do this with a segment tree?
How can you find "first good" node, if order changes after each deletion?
UPD: Oh, I see. If you already have previous element, you already know where new queue begins. So you can just find "first good one" at suffix after previous element first and on prefix after.
I'd be glad if someone could help me hack this code. here
I've first checked if all 4 points are collinear, then if 3 points are collinear. (Solution is trivial in these cases)
After that, I've checked if any of the point lies inside triangle formed by other 3 points. In this case, answer should be "NO".
After that, I've solved the problem for points which do not form parallelogram. (Take two points. Say points are a,b. Other points are c and d. Check if there exists any point e, such that c lies on a-e and d lies on b-e or vice versa)
For parallelograms, extend a-b by some margin, and do as mentioned in case of non-parallelograms.
Are Bangladeshi contestants allowed to have t-shirts if their rank is below 301?
https://www.codechef.com/snackdown/2017/prizes Any team within Top 300 will get it
Yes, I know. I asked the question because recently HackerRank has declared that they will not give any prize like t-shirts to Bangladeshi contestants even if they are eligible for it. I was thinking if Codechef did the same :( I don't know why HackerRank did so.
How to solve the first problem ? PLUSMUL?
Hints:
https://www.codechef.com/snackdown/2017/prizes Any team within Top 300 will get it
You replied to the wrong comment bro ;_; I guess you were tryna help out Nuruhuhuhu
Thanks to mention. I couldn't delete the comment . but I copied the comment above. I guess I was sleepy then. :D
sum[i] = sum[i-1] + dp[i];
dp[i] = ( dp[i-1]-sum[i-2] ) * ar[i] + sum[i-2] + dp[i-1] + ar[i] * pow(2, i-1);
ans = dp[n-1];
complexity : O(n).
Can anyone please explain this recurrence relation ?
dp[i] stores the sum of results of all possible expressions using elements from ar[0] to ar[i].
For next element( ar[i] ) we have to add and multiply it to all our previous expressions.
There are total 2^(i-1) different expression exist at position i-1.
Addition can be done by ( dp[i-1] + ar[i] * pow(2, i-1) ).
For multiplication subtract prefix sum of dp until position i-2 and then add this term after multiplication ( ( dp[i-1]-sum[i-2] ) * ar[i] + sum[i-2] ). By observation.
How to solve ROBOTDAG?
Binary search + max flow inside it
The constraints for this problem are tricky somehow. Especially when you first think of Max Flow. Create n versions of each node. Each node will have an extra copy for every time second. and for each edge u->v add it for all nodes [u][s] -> [v][s+1] where s is a second ranging from 1 to n. I think most people got AC with binary search, but you can throw throw out binary search and add edges to the sink representing each second while going on and after adding each layer call your augmenting path function. I think this runs in K * N * M. But in particular it's kind of impossible to force maxflow algorithms to reach worstcase.
You can easily improve your solution to O(N*N*M),what leads to much better runtimes than with KNM. This probably explains why additional binsearch doesn't hurt.
Can we use Dinic algorithm directly on the graph with N*N nodes? I think it will take the shortest path each time but I got a WA :( Is that correct?
The shortest path in reality might be a longer augmenting (is that the right word?) path because it might need to use backwards edges to complete it when there's a "faster" path just going forwards.
We can create a new graph where each node (i, j) represents that we are on node i at time j. Now when we are creating edges , we should create edges from a nodes (u, t) to (v, t + 1) if (u, v) edge exists in our original graph. So, our initial problem is transformed into finding the edge disjoints paths in our new graph which is a standard problem. Now we can binary search on minimized maximum length by creating a graph in which the nodes are stated as above and t is the length we want to check. To check for a particular length, we'll need to check if the total disjoint paths in our new graph ≥ k and change the limits of binary search accordingly.
Actually i didnt understand this ""To check for a particular length, we'll need to check if the total disjoint paths in our new graph ≥ k and change the limits of binary search accordingly.""
To be specific what is the variable we binary search on ?? And do we create new graph or modify it in any way each time we do new binary search iteration ??
Yes. You create a new graph for each binary search iteration and the variable is the number of layers (time) used on the graph.
ok thanks !!
Prefix XOR: in the problem statement, we're asked to answer queries online rather than offline. But why? The solution is absolutely the same as for the offline version (precompute longest sequence for each position, then answer queries using a segment tree), except that one has to use persistent segment tree instead of segment tree. Is it a test for knowledge of "modern" data structures/googling skills/prewritten code?
There is no need in persistent segment tree. We need to store vector in each vertex of segment tree and do binary search.
Wouldn't this be asymptotically worse? I.e. you do log n binary searches on each query.
Pretty bad meme tbh fam.
sorry i had nice ideas but image editing skills are r3kt
I was trying to do the same using merge sort tree but giving tle even with fast input/output. Solution Link: https://www.codechef.com/viewsolution/14081153
Any suggestions for this??
You are building mergesort tree in time. Probably, good optimization is to build this tree in
time. Probably, good optimization is to build this tree in  time. It can be built with following pseudocode:
time. It can be built with following pseudocode:
Where merge function has linear complexity.
xc
any reason for downvotes??
Where can i find tests for the problems?
I dont think you can view the tests on codechef.
Do you know something about upsolving?
Yes , are you saying that the test cases are visible in practice problems ?
I don't know) But it is great opportunity to finish my work with the problems)
Can Chef and Pairs be solved using ternary search( finding x using ternary search )?
I know we need strictly increasing and later decreasing, but still is there any way to find extrema in function which may not be strictly increasing and then decreasing, but just increasing and then decreasing.
no you dumb fuc
I really enjoyed problem about black subgraphs. A really cool one. Still, I don't understand why so many teams solved it. It was two leagues harder than the damn "copy paste persistent tree" problem.
Which problem in your opinion was about "copy paste persistent tree"?
Just out of curiosity, how often do nontrivial data structures come up in ICPC WF? Can someone give me a rough estimate of the number of (nontrivial) segment tree / treap / other ds problems that have come in WF in the last 9-10 years?
The xor one.
In my opinion, hardest thing was to find for each beginning how long intervals would be good, if you'd start from here. When you already have those n numbers, then yes, you must use persistent tree, but implementing it is standard skill, that most contestants should have. Also I think that problemsetters wanted online algorithm, because D&C approach would kinda break this problem and make it much easier.
http://bestcoder.hdu.edu.cn/contests/contest_showproblem.php?cid=726&pid=1004
I believe there are many online judges have the totally same problem.
What was the solution to the black subgraph problem? The fastest solution I could think of involved iterating to the correct subtree size and taking 2-dimensional fft's or something along those lines.
The solution was an O(n^2) dp. The main observation is as follows. For a subgraph of size s, find the min and the max number of black vertices it can have. Then, answer for all b's from the min to max will be yes, and no otherwise.
Finding min_b[s] and max_b[s] can be done using tree dp of time complexity O(n^2).
Would you share a proof of the claim, please?
riadwaw, The important observation is that you can transition from any s sized subgraph to another s sized subgraph by adding a vertex and deleting a vertex, and it will change the number of black nodes by at most 1. So, the set of valid b's for a fix s will be containing consecutive elements in the range min_b[s] to max_b[s].
Thanks, right. I did the same observation for fixed number of blacks, but for some reason couldn't apply the same idea here
You are talking about probably the easiest problem from this contest, right? I read this problem and 'wait, I spend 40 minutes on geometry while there was obvious DP?!' Still don't understand why so few teams solved it.
Just kidding :) Different people prefer different kinds of problems.
What were the tricks with the "4 points" problem?
We considered the following and ran on randomly generated tests, but still WA.
4 collinear points — choose the furthest points pairwise to form a triangle, and any other given point in the triangle. 3 collinear points — the furthest two points out of 3 forming a triangle, and the fourth point. 4 points forming rectangle (answer is NO). One point inside a tiangle formed by the other 3 points (answer is NO).
Bruteforce permutations of 4 points. Calculate intersection point between 2 lines formed by these points. Choose 2 points in each segment for the triangle and the intersection. Check if the specified conditions were met — namely (a) all points are on the triangle sides; (b) intersection coordinates are within the bounds.
4 points forming rectangle (answer is NO)
it is not correct answer is "YES" in that case.
There is answer for a rectangle... and it's kinda easy. The only case without answer is when one point is inside triangle made of 3 other. I had such cases: 3 (or more) collinear points, points forming a parallelogram, other cases. It's easy to consider every of them separately, hardest thing was about "find intersection of two lines".
I will send this message to my teammate, who couldn't get AC for last 2 hours :D
Here is another solution for the noncollinear case. We need to check if the points in the convex.
Then, assuming ABCD is a convex quadrilateral we can draw the line through C parallel to BD, and intersect it with AB and AD to get E, F. Then AEF is our desired triangle.
I tried to minimize the number of cases, so here's what I did :
If three of the points are collinear, sort them by increasing order of x-coordinate, then y-coordinate. Let's say the points are P0, P1, P2 in this order. Now, we just take P0P3P2 as our triangle.
Otherwise, build the convex hull of the four points. If the size is at most 3, the answer is NO. Otherwise, we have the points A, B, C, D as the vertices of a convex quadrilateral, in this order. In this case, take the lines AB, AD and the line parallel to BD passing through C as the sides of our triangle. The vertices are just the three intersection points of these lines.
Can someone please tell me the recurrence relation required to solve the first problem PLUSMUL
Here
In problem BLACKCOM, how to do that DP ? I have no idea how to do it in O(N^2).
A similar problem to this is problem "Barricades" from Algorithmic Engagement 2007. You can find a solution in the first half of the "Looking for a challenge" book (which you can download here). The book explained why the DP is amortized from O(n3) to O(n2) (which is the same case for this problem).
I guess the estimation of time complexity for your DP is not strict.
Let T(x) be the time complexity of a DP with x nodes. If you write a DP whose time complexity is like T(L+R) = T(L) + T(R) + L*R (Somehow you can convert the tree where some vertex could have three or more children into as a equivalent binary tree), the time complexity is O(N^2) in total (N is the number of nodes) as xuanquang1999 said.
Why? Let's assume T(x) <= x^2, then T(L+R) = T(L) + T(R) + L*R ≦ (L+R)^2 = L^2 + R^2 + 2*L*R. You can find this is obviously true by comparing each term in the left side and the right side.
This fact is a little amazing. I can't understand it intuitively actually.
Let's introduce the potential function as the number of pairs of vertices in the same connected subtree. At first, the number is equal to 0 (all vertices are in distinct subtrees). In the end, the number is equal to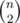 .
.
If you connect two trees of size L and R, respectively, you increase the potential by LR, which is proportional to the time of merging the trees. Thus, the total runtime is proportional to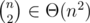 .
.
Straight-forward DP has complexity N^2. You can read cheater2k's very simple explanation here in Vietnamese.
How to solve Chef and Pairs.
My approach was that as we are moving the points from left to right the maximum matching will increase and then decrease , but there can also be plateaus . Also I am not sure about the above claim . Can someone share their approach .
That property of increasing and then decreasing doesnt hold !!
Sort the arrays a and b.
The problem is equivalent to finding the maximum matching of arrays a and b such that if m, M are the minimum and maximum value of A - B where (A, B) is a pair in the matching, then M - m ≤ 2y.
My idea is since n and m are small, I can brute force all possible (i, j) so that we pair ai, bj and m = ai - bj. For each such pair, I can find the maximum number of pairs I can still make without violating m ≤ a - b ≤ m + 2y in O(n) time by greedy.
My team solved 4 problems and ranked 251. Nice contest
How to solve MEXDIV ?
My solution : For each position i, find the leftmost position l such that the mex of the subarray [l..i] is at most k. Note that the mex is larger than k iff all numbers from 0 to k inclusive has appeared in this subarray. Note that if [l..i] has mex larger than k, then [l..i+1] must also have mex larger than k, so the sequence of leftmost position is non-decreasing. We can compute this leftmost position for each i with the help of two pointers. Call the leftmost position for position i as L[i].
Once we build the array L, we just have to do a simple dp. dp[i] is the number of ways to divide the first i elements into subarrays satisfying the condition. dp[i] = dp[i - 1] + dp[i - 2] + ... + dp[L[i] - 1], and the latter can be computed in O(1) time if we maintain the prefix sum for dp[i].
Complexity : O(n).
can you please share your code?
Code
How to submit?
Currently replay round of the contest is taking place ! You can submit there ! Or else after this contest all the problems will be added to practise section. For a problem from contest just remove the contest code from URL to go to practise version of that problem
eg https://www.codechef.com/SNEL17RP/problems/CHEFPRAD -- contest
https://www.codechef.com/problems/CHEFPRAD -- practise
Top 3 teams will win cool SnackDown t-shirts.You are kidding, right? Solutions were made public after contest.
Hi, We noticed that we have missed making the solutions of the elimination round private. Now we are already half way through the contest and the damage is done. Keeping into consideration of the series of events and the spirit of the competition, we are calling back the prizes (of the replay round) that were announced earlier. We shall be more diligent in our future events and we sincerely apologize for the inconvenience caused. Thank you for bearing with us.
Regarding problem CHEFPRAD
I am not sure why no one mentioned this issue yet, but the "expected" solution is O(N * M * (N + M)) per test case. Given there are 10 test cases, this amounts to 3·108 ops, which seemed pretty marginal for 1 second TL to me(given CC servers performance).
I was pretty surprised when my solution with that complexity passed in 0.11 secs(clearly CC servers must be fast and I wasted 1 hour trying to optimise my solution for no reason), but I made some random large test data and it was quite easy to get my solution to get TLE on codechef ide and ideone.com(which is also on sphere engine).
Here is rng_58's team's submission which takes 1.74 secs to run on the test, and team rhaegal's submission which takes 3.36 seconds(!)
I do not blame the contestants for writing slow solutions, but my question is why, if this was expected solution, are the test cases so weak(and TL so tight), and in case it wasn't the expected solution, why do these pass?
We had the same issue , our solution got TLE and we wasted time thinking a better logic. In the end , just changed vectors to arrays(optimized the constant basically) and it passed -.-
Getting 3 * 10^8 operations in a second is not entirely unreasonable. Also, in this problem it is not easy to create test data to force this up. We had the slowest solution running in 0.23 secs.
I thought codechef servers would TL that idea and wasted time trying to code N*M complexity.I feel there exist N*M soln.Is it right??
So finally here comes the question how many operations can we expect to be done in 1sec on codechef(assuming basic addition and multiplication with input size around 10^5 ).
And If that was the idea then what was the intention behind putting test cases around 10. Was it to not allow bit slow solutions with same idea??
(replying after revision 2)
Well, it's safe to say your generation was not strong enough and the test-data is very weak.
Besides, is there even a genuine reason to have 10 test cases per file? I don't see any way it would affect the problem, having 5 cases should be enough to get anything slower TLE.
I had written a very simple C++ rand() using generator: code
I've tried 10 different manual seeds, each takes > 1.65 secs on rng_58's teams submission, and > 3.1 secs on rhaegal's submission.
I know this contest is over and nothing can be done, but please don't add such un-necessary complications in problems in future that just spoil the main part of the problem. :(
Not sure if this is relevant. But I have tested problems for a private contest on codechef before, and my experience was that codechef IDE seems to be significantly slower. i.e, my solution passed on the task, but it was too slow on codechef ide.
Any updates as to when would the selected indian teams be announced?
When will editorials be uploaded ?
Please look into my code for MEXDIV and get me the frustrating bug I am unable to find.
https://www.codechef.com/viewplaintext/14092592
Thanks!
check with a simple case like this: n=3 k=1 array=2 1 0, you are printing 3 while the answer is 2.
Thanks a lot! Strangely enough, I had tried 3 1 ; 0 1 2 during contest and it worked. AC now after removing the else condition. T_T
For this test-case
10 4
8 4 3 1 5 2 0 5 6 0
your code gives rt array as [0,0,0,0,0,0,1,1,1,2] while the correct array should be
[0,0,0,0,0,0,2,2,2,2]. When the 0 is found at i = 7 ( 1- indexed ), you are setting rt for that = lt which is 1,
but for lt=1, the mex is still = 5. So lt should be = 2 , by removing 4 ( at i = 2) also.
Hope you got it!
Thanks a lot! The rt array helped to spot my error pretty quickly. Basically, when a new number was added, I did not bother to check the left position. So, lt was stuck at 1 till a repeat was found at position 10, after which it moved to 2. Removed 4 characters from the code (else) and got AC. T_T https://www.codechef.com/viewplaintext/14103201
Now That Both The Contest And The Replay Have Taken Place , Can You Please Make The Solutions Visible And Release The Editorials :)