This time I've decided to play with spoilers to faciliate the presentation as some of the guys here did before. Tell me what you think about this write-up!
Problem A. Shifts
Topics: dynamic programming.
Summary: the first "hard" problem of the contest. Knowing your basic DP problems helps a lot, but coming up with the precisely correct solution may take a lot of persistence.
Solution: Suppose that we are allowed to make left circular shifts as well as right ones.
Can you solve the problem in this case?First of all, making a shift is effectively moving a character to a different position in the string. Clearly, moving a character more than once makes no sense since we could have just moved it to its final destination instead without wasting any operations. Also, it obvious that the number of occurences of each character should be the same in both strings since it is preserved by shifts.
Now, consider the characters that are not moved by any operation made, and match them with their final destinations in the second string.
Do these two sets form anything familiar?Both sets have to respect their relative order since we are not allowed to move them around. Hence, they have to form a common subsequence of the two strings. Note that if the solution made k operations, the common subsequence will have length n - k.
Moreover, we can make any X into a solution...Moreover, we can make any common subsequence of size k into a solution that makes exactly n - k operations: just move all non-stationary characters to their destinations.
And optimizing X is the problem of...We can see that the minimal number of operations is exactly n - k, where k is the size of the longest common subsequence
If this is not clear,...... think about how the answer could be larger or smaller than this quantity, and try to reach a contradiction with the help of the previous spoilers.
Refer to the link above for the discussion of the O(n2) DP algorithm to the LCS problem.
We have to stop somewhere with all these spoilers, you know! What is the difference when we have only right shifts?Much stays the same...Clearly, the number of occurences of each character must still agree in both strings. Further, it still makes no sense to move the same character twice. Further, the stationary characters still have to form a common subsequence. However, the second sample case shows us that the answer can be greater than n - LCS(s, t).
Can we find additional restrictions?Consider a stationary character si and its destination counterpart in the second string tj. Respective to si, we are only allowed to move characters from right part of s to the left.
This implies a necessary condition on matched pairs...Consider a symbol x. Count its occurences to the right of si and tj, denote the counts A and B. The above reasoning must imply A ≥ B. For si and tj to be possibly matched, this condition must hold for all symbols.
Are these restrictions enough?..A reasonable line of action is to implement the DP solution for LCS while requiring the conditions above. But are the conditions strong enough to allow only valid solutions (that is, stationary sets of characters that can be extended to a sequence of operations)?
It may not be easy to prove or disprove right away. This is a totally OK situation, even for experienced participants.
What would an experienced participant do?If you have a plausible guess that you can't prove but have to confirm, a good idea is to stress test it: implement a brute-force solution that is sure to be right, and check if it agrees with your hypothesis on many random cases. If it does, you are very confident that the guess is right, and if it doesn't, you have a counter-example and can investigate further.
Okay, seriously, can we prove it?Happily, yes!
We have to prove that a satisfactory common subsequence of length k gives rise to an operation sequence of length n - k, or, equivalently, that all non-stationary characters can be moved to correct positions. If there are no stationary characters, then everyone can be rearranged in any order with one operation per character, hence we are done.
Consider the rightmost stationary pair si and tj, and the character collections A and B that lie to the right of si and tj. We must have that  in the sense that no character occurs more times in B than in A. We can easily obtain B in the final configuration by choosing an equal sub(multi)set in A and arranging them in the required order while staying to the right of si.
in the sense that no character occurs more times in B than in A. We can easily obtain B in the final configuration by choosing an equal sub(multi)set in A and arranging them in the required order while staying to the right of si.
What should we do with all the rest elements A' = A\ B? We must spend one operation per element of A' to move them to the right of si into their final positions. However, we may as well postpone the decision and "merge" A' with the next group of characters to the left of si. We then continue with the new rightmost group, and so on until there are no stationary characters left.
Challenge (hard/research):Can you solve the problem much faster than O(n2), or provide hard evidence that a faster solution does not exist?
HintThe problem is closely related to the LCS problem. What does the world know about the complexity of LCS? If we were to show that this problem is at least as hard as LCS, how would we do that?
Solution?I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
Problem B. Number as a gift
Topics: greedy.
Summary: a gatekeeper for inexperienced and/or impatient contestants. Many details to take into account, but otherwise tractable.
Solution: Since we aim to maximize the number, let us look what is the largest first digit we can possibly place. Let d denote the first digit of n.
There are several cases... - d > y
- d = y
- x < d < y
- d = x
- d < x
In some of these cases the rest is easy to find...In case 1 we can place y, in case 3 we can place x, and in case 5 we are forced to make the number shorter by one digit (effectively, placing 0). Since the new number is already compared less than n, the rest can be maximized without restraint, that is, filling with y's.
While in others we have to involve further...If d = x or d = y we may have a chance to match the first digit. However, we cannot tell right away if the first digit can be actually extended to a complete number that does not exceed n, e.g. n = 20, x = 1, y = 2.
How to proceed?We may proceed over digits of n until we meet a digit d' other than x and y, or the end of the number. In the latter case, the answer is just n.
In the former case, we apply our rule once more...If d' > x, then the number can be extended to the end (refer to the initial rule for the first letter). If d' < x, the number can not be extended further and we have to roll back and make some of the eariler digits smaller.
Which ones?Naturally, we can only decrease y to x, hence we find rightmost placed y, change it to x and maximize the rest of the number (since we placed smaller digit at an earlier point).
What if we can't?It follows that n starts with x and proceeds with a digit smaller than x. We can see that there is no satisfactory number of the same length, hence we should decrease the length.
And what is the answer then?Come on, this is easy to come up yourself (or find in the above spoilers). I mean, seriously?
The complexity is...One can see that this is an O(n) solution since we make at most one backward pass, and at most two forward passes.
Still WA?You may want to check the following:
- Can your answer start with a zero?
- Can your answer be a zero?
- Do you handle n = 10100 000 correctly?
- Okay, I don't know. Try stresstesting!
Challenge (easy):How many (modulo 109 + 7) positive numbers are there that consist only of digits x and y and do not exceed n? Solve in O(n) time.
Solution?:I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
Problem C. Recursive Generator
Topics: hashing/string algorithms.
Summary: while this is a simple problem, some approaches are better than others in terms of complexity, memory, and implementation tediousness. Pick your poison!
Solution: As a start, how can we prove why the Fibonacci sequence as described in the statement is not 1-recursive?
Assume that it is...Then there must exist a function f(x1) such that f(ai) = ai + 1. But then we must have simultaneously f(1) = 1 and f(1) = 2, a contradiction!
Can we make this into a criterion for k = 1?Indeed, suppose that any occurence of a number x is followed by the same number y (or the end of the sequence). It means that the function defined by f(ai) = ai + 1 has no contradiction, and the sequence is 1-recursive.
What about extending this to any k?We can see by now that k-recursiveness is all about non-contradicting continuations of k-tuples: if there are two consecutive k-tuples of elements followed by different numbers, then the sequence is not k-recursive. Otherwise, the function defined by f(ai - 1, ..., ai - k) = ai is consistent.
How to check is the sequence has no k-contradictions?We could do that explicitly by writing out all k-tuples along with the subsequent elements, and check for conflicts. This takes O(n3) time when done explicitly,
or... time if we sort the tuples and compare only the adjacent pairs,
time if we sort the tuples and compare only the adjacent pairs,
Finally...The rest of the solution is binary search on k, with the resulting complexity 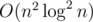 , or
, or  .
.
Challenge (easy/exercise):Solve the problem:
- in with simple string algorithms (no hashes!)
- in O(n2) with simple string algorithms (no hashes!)
- in
 with harder string algorithms (no hashes either!)
with harder string algorithms (no hashes either!)
Solution?:I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
Problem D. Trading
Topics: greedy, sorting, implementation.
Summary: while the solution is not exactly evident from the start, one has to jumps a lot of hoops and dodge a lot of spikes to avoid all possible mistakes with precision, query limit and whatnot.
Solution:
Can we solve the problem if we know the vendor's values of d?Suppose that we're willing to spend some amount of goods so that vendor's perceived price is a small ε.
What is the optimal way?Suppose that we choose to spend only i-th good, then we have to spend ε / di, with our perceived value being ε·ci / di. Hence, it is optimal to choose the good that minimizes ci / di.
Can we guess how the solution looks?Breaking x into small ε portions and applying the previous argument, we can see that we should gradually use goods by increasing of ci / di until the vendor agrees to sell. Note that goods with equal ci / di can be taken in any order.
What to do if we do not know d_i's?According to the considerations above, it is beneficial to know the order of goods sorted by ci / di.
What do we need to be able to sort objects?A key idea is that it is unnecessary to know the values of ci / di, but only be able to compare them.
How do we do that?Our query capacity is very limited: a simple YES/NO answer, that we have to apply to precisely comparing numbers. A correct way to do this would be to obtain a configuration with 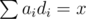 with high precision, and then make alterations to it so that the balance is decided on ci / di comparison.
with high precision, and then make alterations to it so that the balance is decided on ci / di comparison.
How to find a balanced configuration?Simply make all ai equal and binary search on their common value. About 40-50 iterations should result in a practically precise double value (more on precision issues below).
How to perform comparison?Let us choose a small, but positive Δ. To compare fractions for i-th and j-th goods, alter the balanced configuration by performing ai - = Δ·cj, aj + = Δ·ci. The value of 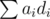 will be changed by the value of
will be changed by the value of 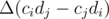 , which has the same sign as ci / di - cj / dj. Note that comparison takes only one query (except for the equal fractions case which may be undecided as of now, more on that later).
, which has the same sign as ci / di - cj / dj. Note that comparison takes only one query (except for the equal fractions case which may be undecided as of now, more on that later).
We've sorted goods, what now?Since we now know the order, we can binary search on the total volume of goods we're paying. Greedy considerations above tell us to distribute them greedily from the lowest ci / di to the highest.
The resulting solution makes roughly 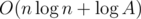 queries, in practice this number is about 450 on the present constraints.
queries, in practice this number is about 450 on the present constraints.
This pretty much concludes the idea description.
Still, there are many nasty details...How to choose Δ?The only constraint is that we can't choose Δ to be too large since we may over/underflow ai. We know that the common value of ai in the balanced configuration will be at least 0.1 away from the borders. To keep the alteration within this distance we have to satisfy Δ max(ci) ≤ 0.1, hence Δ ≤ 10 - 5 is pretty much fine.
Note that the value of will be 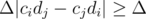 away from x provided we are comparing distinct fractions, hence we are free from precision problems at this point.
away from x provided we are comparing distinct fractions, hence we are free from precision problems at this point.
My solution relies on consistent comparison of equal fractions, can I do this?This is a bad spot to be. One possible situation when this issue arises when you're using std::sort to sort the fractions with the custom comparator that makes the queries itself. std::sort likes to make additional comparisons to check certain properties of your comparator, such as transitivity. Not only that provides an overhead on the query number, but can also lead to RE if your comparator does not behave well on comparing equal objects: it must always return false on equals.
The reason why our comparison is bad for this prupose is that the value of 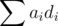 changes ever so slightly when add practically zero number to it, so that it can dance around x and returns random values on comparisons (note that there is no tolerance in
changes ever so slightly when add practically zero number to it, so that it can dance around x and returns random values on comparisons (note that there is no tolerance in ? query!).
One solution would be to make slightly larger than x so that not to suffer from precision fluctuations (warning: this can break most of the present analysis, do at your own risk).
Note that most sort algorithms are resilient to this kind of problem (e.g., merge or insertion).
Challenge (medium):Can you solve the problem in 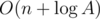 queries, where A is the maximal value of ci, di?
queries, where A is the maximal value of ci, di?
Solution?:I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
Problem E. Manhattan Walk
Topics: maths, shortest paths in graphs.
Summary: even if you don't come up with a simple mathematical solution, graph algorithms save the day. Easy!
Solution:
Looks standard, right?We can construct a graph with vertices for each configuration (x, y, d), where (x, y) is the current point, and d is the direction last travelled (note that we only need to remember if the direction was horizontal or vertical). Assuming that we never leave the square with coordinates bounded with 100 by absolute value The graph has < 200 000 vertices and < 400 000 edges, hence we can find the shortest path with a simple BFS.
I'm lazy, can I do better?Denote Δx and Δy the absolute differences of x and y coordinates respectively.
The answer is...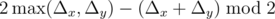 .
.
Why??Without loss of generality, suppose that Δx ≥ Δy. First, we cannot make less than moves. Indeed, we have to make at least Δx horizontal moves to get to the finish, and, because of alternation, at least Δx - 1 vertical steps. We also change the parity of sum of coordinates after each step, and that determines the parity of y-steps.
Second, this number of steps is enough. To see that, first travel to the point (Δy, Δy) in 2Δy steps with a repeated UR step pattern, and then repeat the RURD pattern until you reach the target. One can check explicitly that the lower bound on the number of steps is reached exactly.
Challenge (easy, I gueess):How to solve the problem if we are travelling in k-dimensional Manhattan, that is, the position is given by a k-tuple of integer coordinates, and we're allowed to change one coordinate at a time, and must change the "streets" (coordinates we change) after each step? Solve in 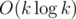 time.
time.
Solution?:I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
Problem F. Tree Game
Topics: game theory, graphs, math.
Summary: frankly, I anticipated a lot more solutions on this problem. All ideas seemed basic to me, and the code is very easy. Still, it seems that cracking the whole thing was not that simple. Did you enjoy solving it? =)
Solution:
Phase 1!For the, say, Red player we must have kR = vR - eR, where vR is the number of red vertices, and eR is the number of edges with both endpoints red.
Phase 2!Red player wants to maximize kR - kB, which is equal to (vR - eR) - (vB - eB) = (vR - vB) - (eR - eB). Note that vR and vB are independent of the players' actions, and 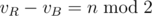 . It follows that the equivalent game would be to minimize eR - eB.
. It follows that the equivalent game would be to minimize eR - eB.
Phase 3!Let us keep a counter on each edge. When Red player moves to a vertex, all counters of incident edges increase by 1, and when a Blue player moves, all incident counters decrease by 1.
What is the total value of all counters in the end?On one hand, the is clearly (sum of degrees of Red's vertices) — (sum of degrees of Blue's vertices).
On the other hand, a red edge (with both endpoints red) has +2 on it, as a blue edge has -2. A neutral edge has 0 on it. It follows that the same total is equal to 2(eR - eB).
Assemble?The above discussion implies that moving to a vertex of degree d effectively gives you d / 2 penalty against your score.
It is now clear that the optimal strategy is to always move to a free vertex of the lowest degree, regardless of any previous actions.
This is easily implemented into a clean O(n) solution.
Challenge (nasty):How to play this game on a unicyclic graph (a connected graph with n vertices and n edges)? What can you say about complexity in the case of a general graph?
Solution?:I will post the solutions to challenges at a later time, enjoy solving yourself for now. =)
I'll be glad to hear all your opinions in the comments. Thanks for participating!









D and (especially) F are great! Thanks.
Thank you for the great round. I enjoyed to solve A, very interesting problem:D
Let's define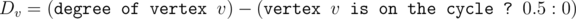 . Then the strategy "choose vertex with the lowest value of Dv among remaining vertices" is optimal. Is this correct?
. Then the strategy "choose vertex with the lowest value of Dv among remaining vertices" is optimal. Is this correct?
And I'll be surprised if the complexity is less than O(POLY·3V) in a general graph.
BTW, I was reminded of Euler Getter from F.
Yeah, looks good to me! I had something complex (and probably wrong), but now I see that this should work. I will probably leave the proof out for now though. =)
I stupidly used map<vector, int> in C and it passed in less than a second))
I also did it, but I don't consider it stupid ;p. However that's why I didn't submit it blindly because I was a little scared about getting TLE.
Why is binary search possible in problem C?
Suppose it is true for a certain length L that all different consecutive L-length tuples have different neighbours to their right(if they exist). I was not able to find any condition mathematically which could show for any length k (k>L), the given sequence is definitely k-recursive.
PS: I tried singe hashing first. It failed. Then I tried hashing with two primes and two big primes. It failed then too. The anti-hash tests were too strong. Can any one tell me which primes did they use for hashing? (in general also).
I think different consecutive L-length tuples arent necessary to have different neighbours to their right. Like a function having different parameter can give out the same value.
It is K-recursive if for every i, j that a[i — k... i — 1] = a[j — k... j — 1], a[i] = a[j].
Now assume It is K-recursive, then it is L-recursive (L >= k). Because first if a[i — k... i — 1] != a[j — k... j — 1], a[i — L... i — 1] != a[j — L... j — 1], so we dont have to consider them. If a[i — k... i — 1] = a[j — k... j — 1], now a[i] must equal a[j], so no matter a[i — L... i — 1] is equal to a[j — L... j — 1] or not, it is still valid.
This editorial is like Christopher Nolan movie. I keep peeling it and new layers keep coming up. At the end I am not sure if I understand the intended story :)
I hope I didn't go too far on the postmodern side in spite of clearness. Would you like something to be explained better?
It's nicely formatted editorial. I had some difficulty following the description for C. I don't understand the transition from Fibonacci series to "if there are two consecutive k-tuples of elements followed by different numbers, then the sequence is not k-recursive". e.g. 1,1,2,3,5,8 seems to match the given condition (1,1 and 2,3 is followed by 5,8) however it is 2-recursive. Source code accompanying the explanation would have been clearer for me.
Take random element, compare it with others and recurse to only one half instead of both (after determining which one). If elements less than this element already contribute at least x than we do not care about order of bigger elements.
Basically it's randomized k-th element algorithm.
Absolutely correct!
In fact it is also possible to adapt standard algorithm searching for median in deterministic way, that works the same way and ensures pessimistic linear complexity, however it would be more complicated to code (but we can make use of nth_element with custom comparator).
Pretty good problems and solutions both. Upvote without any hesitation. Problem A is very instructive to me to think more about LCS. However, I have some confusions about the contest rank. In the rules, it only tells that "Top 512 participants according to the cumulative result of all four elimination stage rounds will receive a contest T-shirt." But, what does the "cumulative results" mean? Does elimination stage show final rank? Sorry for disturbs:(
Yes, the rank is calculated according to the aggregated table at your link.
Here is my derivation for F:
Let's rewrite the score, for kR we can rewrite it as vR — eR; where vR is the number of vertices colored by Red and eR is the number of edges with vertices on both endpoints colored by Red.
Same for kB, we arrive at: (vR — eR) — (vB — eB) which is equal to: (vR — vB) — (eR — eB).
Firstly, observe that the term (vR — vB) is just a constant equal to n mod 2 as both Red and Blue take turns after each other.
Secondly, let's further rewrite the other term, we can observe that edges in the final graph are one of three types:
- eR, eB and eX: edges with different coloring of vertices on their endpoints. We'll rewrite eB as E — eR — eX, where E is the total number of edges. This results in the equation: n %2 — (eR — (E — eR — eX)), which we can simplify as: n %2 + (n -1) — (2*eR + eX).
Finally, we can observe that the last term: (2eR+eX) is exactly equal to the sum of degrees of vertices colored by Red, because, for each vertex colored by Red, all edges connected to it are either of type eR or eX, and edges of type eR are counted twice in the summation of degrees. Remember that the degree of a vertex in an undirected is the number of edges connected to it. So, the goal for Red or Blue becomes to minimize the sum of degrees of vertices colored by them, regardless of previous actions!
Consequently, the optimal choice for Red and Blue will be to color the minimum degree vertex that is uncolored. This results in Red choosing the vertices with the 1st, 3rd, 5th, 7th, 9th, ... (up to nth for odd n or (n-1)th for even n) minimum degree vertices, let's refer to the sum of degrees of these vertices as S.
The final score can be calculated directly as: n%2 + (n-1) — S.
S is calculated after taking the input and sorting vertices based on their degrees, this means complexty is O(n log n).