


Hi. I am having problem trying to solve JOI 2013/2014 — Historical Research. The english problem statement can be found here.
For those who understand Japanese, the editorial can be found here
The input and output data can be found here
My approach is as follows:
Let product = element × frequency in subarray [L, R]
We use a BST to answer our max product queries and element updates efficiently, Each element of the BST would be < product, element, frequency > and the elements in the BST are sorted by product.
Let N be the number of elements in our array and Q be the number of queries.
Perform square root decomposition on the queries by breaking them into  blocks and sorting them in increasing order of left bound followed by increasing order of right bound. Time-complexity of this operation is O(Q × logQ).
blocks and sorting them in increasing order of left bound followed by increasing order of right bound. Time-complexity of this operation is O(Q × logQ).
We keep 2 pointers to track the left and right bound of the subarray that we have calculated the element frequency for. Every time we shift the left pointer, we remove the elements from the left side of the subarray from the BST. Every time we shift the right pointer, we add the new elements in the subarray to the BST.
Of course, we have to update the product accordingly. Time-complexity of this operation is 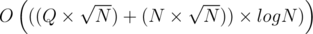 . This is because each query can only be in one block and block size is
. This is because each query can only be in one block and block size is  . Hence, the left pointer can only move by on each query (i.e.
. Hence, the left pointer can only move by on each query (i.e.  in total) and the right pointer moves by O(N) in every block and we have blocks. Hence, right pointer moves by
in total) and the right pointer moves by O(N) in every block and we have blocks. Hence, right pointer moves by  in total. Finally, each movement incurs an update operation in the BST which is O(logN). That proves the time-complexity for this part.
in total. Finally, each movement incurs an update operation in the BST which is O(logN). That proves the time-complexity for this part.
Every time we need to query the maximum product, we just query the largest element in the BST, which is O(logN).
Hence, the total time-complexity is 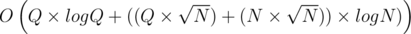 . However, 1 ≤ N, Q ≤ 100, 000, which implies that the algorithm will perform
. However, 1 ≤ N, Q ≤ 100, 000, which implies that the algorithm will perform 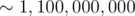 operations in the worst case (do note that the time-limit is only 4s). I tried coding this solution and as expected, it passed all but the last subtask (which uses the largest input).
operations in the worst case (do note that the time-limit is only 4s). I tried coding this solution and as expected, it passed all but the last subtask (which uses the largest input).
Could someone please advise me on how I could optimize my solution's time-complexity?







The worst in your complexity is N*sqrt(N)*log(N). You can just compress all numbers in the beginning (but save somewhere their original value) and use Mo's Algorithm (link). So your solution will have complexity O(N*sqrt(N)).
How did you manage to get rid of the logN factor? We still need the BST to perform efficient updates and queries right?
We compressed numbers and if we need to add num x that originally was o[x], we just ++ cnt[x] and update max, mx = max(mx, cnt[x] * o[x]).
Hi. According to the article that you mentioned earlier, MO's algorithm requires 2 methods: add() and remove().
While trying my hands at the implementation, I ran into a problem: how to implement an efficient remove() function? For add(), we can just use the O(1) method that you described. However, when we remove elements from the current range, we need to recover the maximum product of the previous range efficiently.
For example, I have queries which are reordered as follows:
(1, 3), (1, 4), (2, 3) ...
The problem occurs at the 3rd query. When we shrink the left/right side of the window, how could we re-discover the maximum product of the previous range efficiently?
I thought of preprocessing each block of the array to hold the maximum product for each block. But the union of maximums will not give the overall maximum. Preprocessing the element frequency for each block seems useless too because we need to still need to recalculate the maximum product of the entire range which is O(N) per query.
block of the array to hold the maximum product for each block. But the union of maximums will not give the overall maximum. Preprocessing the element frequency for each block seems useless too because we need to still need to recalculate the maximum product of the entire range which is O(N) per query.
Please advise me.
For example you have situation like in this picture: Instead of removing [L1, L2) we will remove all items in [L1, BR] (without updating maximum) and then add [L2, BR] (with updating). Because of this we don't need to update maximum after removing, but what is complexity of solution? For every block we shift R not more than N times (because they are only increasing). In total we shift L about O(Q*sqrt(N)) times (for each firstly to BR and then to the next L). So complexity is N*sqrt(N). Case with L > BL and R < BR we can brute force because length of such a query is < sqrt(N).
Instead of removing [L1, L2) we will remove all items in [L1, BR] (without updating maximum) and then add [L2, BR] (with updating). Because of this we don't need to update maximum after removing, but what is complexity of solution? For every block we shift R not more than N times (because they are only increasing). In total we shift L about O(Q*sqrt(N)) times (for each firstly to BR and then to the next L). So complexity is N*sqrt(N). Case with L > BL and R < BR we can brute force because length of such a query is < sqrt(N).
Instead of removing [L1, L2) we will remove all items in [L1, BR] (without updating maximum) and then add [L2, BR] (with updating)
I didn't understand this part. How do we add [L2, BR] (with updating) efficiently? If we update the maximums of the entire window, the operation might cost up to O(n)?
If we need to delete items in [L1, L2) we'll delete items in [L1, BR] (without updating maximum, just -- cnt[x]), it works for O(sqrt(N)) because length of block is O(sqrt(N)), then we'll add all items in [L2, BR] (with updating maximum, ++ cnt[x], mx = max(mx, cnt[x] * o[x])), this part also works for O(sqrt(N)). For each block we shift R O(N) times, for each query we shift L O(sqrt(N)) times, so complexity is O((Q + N) * sqrt(N)).
Thank you so much for your help! I managed to obtain a sample of this exact implementation and passed the time limit. Actually, I think that this is a really clever trick which splits the query into 2 portions (assuming that the left and right pointers lie in 2 different buckets). We evaluate from the start of the left pointer's adjacent bucket to the right pointer. Then we start from the left pointer and evaluate until the end of its bucket. The removal of elements from left pointer until the end of its bucket will ensure no double-counting in the next iteration.
In the case that both pointers are in the same bucket, we can just use the brute-force which will still be efficient enough (because of small block size).
I think that this should be the gist of the more efficient solution.
Once again, thanks so much for your help!