


I use this post to try and explain an alternative to HLD that I have been using for more than a couple of months.
As many of you might be familiar HLD is a very tough thing to implement and is time-taking and must be implemented carefully.
Also if HLD sums are asked in short contests then it is going to be difficult to implement. Hence I came up with this technique.
I will try and explain this concept with the july long contest problem.
In this problem the value of number of nodes is given to be 10^5 which means maximum depth of the tree is 10^5 (worst case). What I do is I perform a dfs in the tree and for every node whose depth%1000=1, I store the values of all its ancestors.
In worst case the memory complexity is (1000+2000+...10^5)= 1000(1+2+3+....+100) = 5*10^6. After this I sort all these values and take a prefix xor.
Now for each query I have to travel up atmost 1000 ancestors and arrive at an ancestor whose depth%1000=1 and from there we can find xor of all elements less than k. We do this for both nodes U and V(source and destination). Because of the property of XOR all the values of the ancestors are canceled out.
Hence each query is (1000*Q) in the worst case.
Though this is somewhat testing the upper limits we can actually dynamically change the value in which we store the ancestors(1000 in this case). However this has not been required so far for me.
This is because we such situations(which test upper limits) rarely occur but even for that depending on the tree we can change the depth value.
Another question I solved using this techique is GPD in codechef. GPD can also be solved using persistent trie but this method is far more easier.
My solutions for : PSHTTR : GPD
In case for sum of values in the path between 2 nodes we can store sum of ancestors and we can find answer by:
sum upto U + sum upto V — sum upto LCA(U,V)
Upd1: If the maximum depth of tree is less than 1000 you can directly climb up the tree and do the calculations.
Also as Diversity pointed out there can be cases where there are 10^5-1000 nodes which have depth%1000=1. For overcoming this we can have an initial dfs that has a count of depth%1000=1,2,3,4,...,999 and we can choose values which satisfy the memory limit using count(This is the dynamic change of value I mentioned).Also I believe we can strech upto depth%2000.
Note: I have not tried implementing this technique of changing node depth of storing values dynamically.







Auto comment: topic has been updated by sdssudhu (previous revision, new revision, compare).
Auto comment: topic has been updated by sdssudhu (previous revision, new revision, compare).
If I understood correctly, isn't this just sqrt optimization i.e. perform updates and queries in buckets of sqrt(n).
Yeah it is similar to sqrt decomposition but the bucket size is not necessarily sqrt(n) and I thought by this post more people will come to know about this as it is very useful for short contests
Consider tree of single root with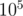 children all having
children all having 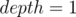 ...
...
Well, at least there is good news: there always is such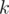 that there are at most n / p vertices having
that there are at most n / p vertices having 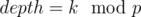 . But you should find that
. But you should find that 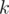 .
.
I believe we can find the value of k by performing an initial dfs and store count of depth%1000=1,2,...
wow it's simple and elegant.Thanks for the blog :D
Can you provide link to more questions which can be solved using this technique?
I don't remember anything right now. I haven't seen anything recently related to it. Will update if I get some other problems
sqrtdecompton would love this