


Hi!
Hints
A: Tag: Greedy!
B: Tag: Greedy!
C: For each vertex like v find exv, the expected length of their journey if they start from v.
D: Tag: Inclusion exclusion.
E: Find the maximum clique.
Solutions
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
NikaraBika's solution: 29458745.
Tutorial is loading...
P.S. Please notify me if there is any problem.







I want to say that many wrong solutions for B still passed final testing ! So results are not still totally good.
Many of the shortest codes gives Wrong Answer on this case :
3 11
2 2 2 2 2 2 2 2 2 2 2
Answer is "NO" as solution in editorial, but you can check many codes gives "YES">
Have you drawn this configuration? I didn't find any. In my opinion it's still "NO".
[comment misinterpreted]
forget it XD
It's obvious that authors should have made more tests for this problem, especially when they did mistakes. http://codeforces.com/blog/entry/53773?#comment-378173
It should be a strong requirement for YES/NO problems to make no less than 100 test cases. It is not difficult to randomly generate some decades of short test cases, and to compose more tests of edge cases. There were only 78 tcs.
Yeah. There're a lot of submissions which implement via a strange condition. A test case of large sum of 2s can hack them.
In Problem D the reference code link of 2nd method is wrong.
Not the first time in last rounds obvious and intuitive authors' solutions turned out to be wrong. And what we see in editorial for problem B? Some greedy solution without any proof. Nice.
What do you mean? It's not the real solution?
Well, I thought samee after 3 seconds of reading :D
Personally, I would like to hear proof for dotorya solution, or some other short code with math :)
My proof is exactly same with editoriL. Here's a link I wrote before editorial posting: http://codeforces.com/blog/entry/53773?#comment-378295
I think he's talking about problem B's proof for greedy.
Oh, It was my mistake. Sorry. Talking about B, actually I didn't prove it during the contest. I tried to prove it, and I think it's correct. Main idea is to fill people in some pre-defined order. Until sum <= 4*N, Put them having no neighbors. Then, First put them in {1,2} and {7,8}, 3rd place in each {3,4,5,6}, and 4th place in each {3,4,5,6}.
Here's my proof: (Warning: Very tedious)
Lemma 1. If some line has x people in {3,4,5,6}, and some line has >=x+2 people in {3,4,5,6}, it can be switched to have difference less than 1.
Proof) 0-2, 0-3, 0-4, 1-3 : just shuffle it to 1-1, 1-2, 2-2 and don't let them be a neighbor. 1-4, 2-4 : it means that line with 4 people are in all same group. Split them into 2 and 2, put them in {3,4} each. Put remaining people in {6}.
Lemma 2. If some line has 1 person in {1,2}, and some line has >= 3 people in {3,4,5,6}, it can be switched to have 2 people in {1,2}. (Same holds to {1,2} -> {7,8})
Proof. Take two consecutive people from {3,4} or {5,6} and put them to {1,2}. Put person already was in {1,2} to that position. It still holds.
Lemma 3. If some line has 2 person in {1,2} and some line has <= 1 person in {3,4,5,6}, it can be switched to have 1 person in {1,2}
Proof. Just switch it.
Proof for original problem:
Case 1) sum <= 4*N : Obviously can put them. (Only using 1, 3, 5, 7)
Case 2) sum > 4*N && sum <= 6*N :
If {3,4,5,6} of some line have >= 3 people, we can assume that all {3,4,5,6} have >= 2 people. (By lemma 1) It means there are >= 2*N+1 people in all {3,4,5,6}. So, some {1,2} or {7,8} will have 1 person there. (If all of them have 2 people, sum >= 2*N+1 + (2*N) * 2 = 6*N+1) We can shuffle this 1 person and {3,4,5,6}'s >= 3 people. (By lemma 2) It means that all {3,4,5,6} have <= 2 people. In almost same way, we can prove that there should be no <= 1 people in {3,4,5,6}, and it means all {3,4,5,6} should have exactly 2 people. So the only way is to use {1,2} and {7,8} as long as you can, put people one by one.
Case 3) sum > 6*N & sum <= 7*N
Almost same with above case. Proof that all {1,2} and {7,8} should have 2 people in each row, and proof all {3,4,5,6} should have 2 or 3 people in each row.
Case 4) sum > 7*N
Same way. Only thing changes is that {3,4,5,6} should have 3 or 4 people.
By above cases, this order is (one of) optimal way to put all people. If we can't do that in this order, we can't do it in other way.
See this for Problem D https://explainalgo.wordpress.com/2017/08/14/d-winter-is-here-editorial/
nice explanation :)
Out of curiosity: can you please share the difference between model solution for problem B provided in editorial and original (wrong) solution for it?
Original (wrong) solution missed this part: If no seat found, divide this group and make it two groups with size 1.
The code attached for problem D is actually a solution for problem A. Please fix this.
Sorry, I'm waiting for NikaraBika.
Oh, God doesn't like liars :-s
I told you please submit your code in problemset section in order to I can publish your solution. But you have submitted it in contest section and because you are admin of the contest, your code couldn't be published. Now it's up for judging, who is liar?!
You XD
You lied again...
In problem C,
I attempted to calculate the expected value by calculating the probability to reach each leaf node and distance to each leaf node (Using BFS in my solution) and loop over all leaf nodes and sum the multiplication of their probability * distance
Fixed code if anyone's interested Code Link
Hey , I interpreted the question as "We start the jorney from node 1 and have to reach all the leaf nodes , since we can't go any beyond them , and hence calculate the expected value of the jorney ".
So I just used a BFS to cal distances and then divided it by the number of leaf nodes. Since I have misinterpreted the question , can you please help me find , what I understood wrong ?
You interpreted it as that you reach each leaf node with equal probability.. That is not correct. The correct interpretation is.. If you have a node X that connects to node A,B,C IF you are currently at node X the probability that you go next to A,B or C is equal..
If you need more clarification I'd be glad to help
So if a node 1 is connected to 3 nodes A,B,C and node C has a leaf node D , then the answer contributed by node D would be ((1/3) * (1/1)*(dist[D])) ?
Yes.. And To make things more clear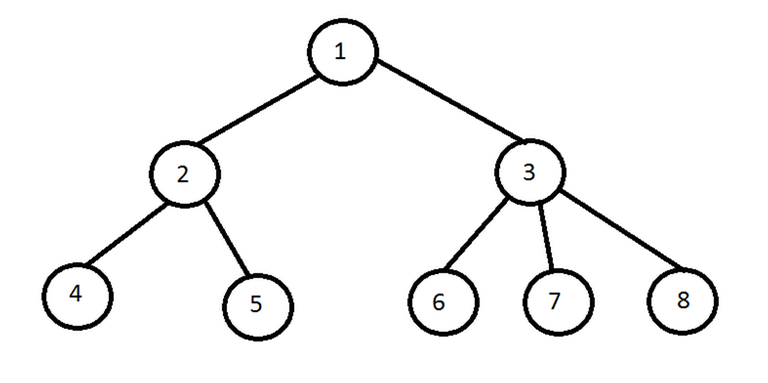
Look at this image here.. The node 1 (Root Node) has a probability of 1) Since It is guarenteed that we start at node 1
Therefore each of its children will have a probability of 1/2.. more formally=>
Probability of child = Probability of parent/ number of children
Consequently
Probability of 2=0.5,, Probability of 3=0.5,, Probability of 4 = Probability 5=0.25,, Probability of 6 = Probability of 7 = probability of 8= 1/6.
Thank you very much , I already implemented it that way :)
i still cant understand why "+1" for ans[i] ?
Look please at this sample and draw it if it's better to you:
5
1 2
1 3
2 4
2 5
The expected value of length of journey if we start it at node 1 (let it exp[1]) equals to:
sum of(lenght from node 1 to 2 (let it len(1,2)), exp[2], len(1,3), exp[3]) divided by 2 (because 2 is the number of children of node 1).
So exp[1] = (1+exp[2]+1+exp[3])/2
and this = (1+1)/2 + (exp[2]+exp[3])/2
and this = 1 + (exp[2]+exp[3])/2
Hope it answered.
EDIT 1: I'm sorry about untidy writing.
EDIT 2: I have just tidied the comment :D.
Got it .. Thanks :)
Welcome.
E was really cool. Thank you for preparing such a good problem!
Can someone explain formula on D-2? 1*(c/1)....
First of all, look at the first mention which f(m) is defined. this formula represents the value of f(c), because we have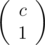 subsets with size 1 ,
subsets with size 1 , 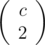 subsets with size 2 and so on ...
subsets with size 2 and so on ...
And this values is equal to c·2c - 1 by some mathematical calculations.
Thank you for such a fun round :) I especially liked problems D & E.
The biggest part on B failed with distribution of 8+ groups, just easily putting them on full rows and after using only ai%8 values :/
The link of solution of problem D is same as solution of A
P.S. MaGaroo's solution: 29412123. Arpa's solution: 29412123.
For C ,what is wrong in this ? http://codeforces.com/contest/839/submission/29421807
You check if a node is a leaf by checking adj[cur].size()==1, but that doesn't work when node 1 only has one child. This causes your method to return immediately with ans=0. Here is a simpler test case where your code fails: 4 1 2 2 3 3 4
Such a stupid mistake ! :/ . Thank you so much !! Now it got accepted. http://codeforces.com/contest/839/submission/29423632
A suggestion for future editorial writers. Please dont write hints on the very first few lines...you spoiled both Problem D and E for me.Try hiding them under the expandable section as is used for code samples.
For question no.B the answer is 'YES' or 'NO' for this test case 7 ? Still confused(may be my understanding of question is wrong)? If 'NO' why? can any one clarify?
The answer is NO as it is impossible to sit four groups of 2 without two groups being adjacent. Here is an illustration of the closest possible seating to a proper answer (Note: — represents a division) : aa-bbcc-dd. In this case 4(b) and 5(c) are adjacent to each other, and so this solution doesn't work. In short: It's impossible to arrange these people such that no two people from different groups are adjacent, so the answer is no.
anser is NO,,,,,,,,,look at this distribution, it's wrong 11 2233 44
simple solution for B
3 10 2 2 2 2 2 2 2 2 2 4 my code gives wrong answer for this test case yet it got accepted:(
I think the contest should be unrated!coz when the contest was running the solution of author for problem B was wrong (maybe It's still wrong,I did't see any proof about his greedy solution),It means that some coders could hacked your correct solution...and this can waste your time to debug your correct solution!(sorry for my poor english)
the problems of the contest were very nice but judging...
Please be fair and don't vote negative coz i said It should be unrated...!
It is sad there were issues with judging of B, because I loved the problem.
You see, I recently sat in a long-haul flight in exactly that row, in the MIDDLE OF THE FOUR!!
I was not happy. :-) But next time it happens I can think of this problem. It's very cool that it relates to "real life" .Well, except for airplanes in GoT. Maybe dragon powered airplanes ...
Anyway, if there is such a thing as an elegant implementation problem, this is it. Requires very careful thought to find all the cases and implement correctly. But ONLY thinking, no algorithm knowledge. If I had taken more time to think and try more cases instead of being lazy, I may have got it. But rush to submit is very tempting, so I am always very bad at such problems.
Perfect Div2B.
I don't wanna discuss about quality of the problems! look when the contest is running and the solution of judge is wrong for some problems then coders can hack your correct solution !and this is not fair...
No argument about judging. I'm sorry if you lost points because of it.
You weren't affected by the issue. The hack's solution is indeed YES, and you printed out NO. Stop blaming your mistakes on the judge. There were issues with hacks, but you weren't included.
I did't talk about myself!! I explained why the contest should be unrated!!
Anyone who was affected, and got negative rating change, will have it unrated, so no one will lose rating because of this issue. Though it still is slightly unfair, because some (for example me) could have hacked more, and get more positive rating change, but I don't think that +5-10 rating would matter that much, and very few people were included anyways.
If this is true(first line) It's good and fair
See here.
Thx man
can anyone check my solution for C. I have tried a lot of scenarios but it doesn't fail for me. Link for submission: **http://codeforces.com/contest/839/submission/29426907**
You also need to consider the probability that the horse will go there so if a node has three children then the horse will visit each children equal number of times and hence just considering average of length from root to each leaf wont give right answer. Also while calculating average you are adding 1 to sum when u have a child. This method is wrong as u need to add number of leaves of child to sum as all the leaves will get a length+1.
In problem B, are seats 3,4,5,6 considered to be neighbors because I don't seem to understand what's wrong I thought that every pair of seats considered to be neighbors which are proven wrong by test case 7
1 4
2 2 2 2
NO, while in my understanding it should be yes, can someone clarify?
Answer will be no because seats 3,4 and 4,5 and 5,6 are considered neighbors so in above senario possible configuration is 12 3456 78 AA BBCC DD here at seat 4 and 5 B and C are neighbors hence answer will be NO
look two person from two different group can't be neighbors. in this test case u should fill all seats, when u put some group on seats 3,4,5,6 one seat should be empty(first line).so u can't put all groups...
Can someone explain me promblem C? why my solution with float didn't pass, but when I changed it to double it passed( UPD: it's still running )? Is there any BIG difference??? I'm pazzled:(
double has about 16 decimal digits while float has only 7 digits
thank you very much:)
can someone explain what author is doing in method 2.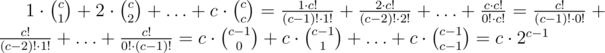
I am not getting this step,
`
Suppose,the number of elements in the given array which are multiples of i are c then the sum of size of all subsequences will be the above formula that is 1*(number of sunsequences of size1) + 2*(number of subsequences of size 2).....+c*(number of subsequences of size c).
(1+x)^n = nC0 + nC1*x + nC2*x^2 ....... nCn*x^n Now if you differentiate this this equation you will get n*(1+x)^(n-1) = nC1 + 2*nC2*x ....... n*nCn*x^(n-1) and put x = 1 in this new equation. After that you will get the desired equation result.
The link of solution of problem D is same as solution of A.
Could you please clarify D-1 formula?
For better understanding the “Inclusion–exclusion principle” we used. consider this problem :
You want to find the number of subsets of a set , that their gcd is equal to 1.
Let ans be the answer. First of all add the number of all subsets to ans. Then we are going to exclude the sets that their gcd is not 1. So decrease ans by the number of subsets that their gcd is a multiple of 2, 3, 5, 7, ... and every prime. Then there are some sets that have been decreased from ans twice or more (like the multiples of 6). So again we have to increase ans by the number of subsets that their gcd is a multiple of 6, 10, 15, ... and every number that is multiple of two primes. Then there are some sets added to ans twice or more , so we decrease it in the next step and so on.
In this problem also we can use a similar Inclusion–exclusion that is explained in the Editorial.
See this :) https://explainalgo.wordpress.com/2017/08/14/d-winter-is-here-editorial/
Thanks, this was really helpful:)
If you wonder where does this formula came from, note that i*C(x, i) = x! / ((i-1)! * (x-i)!) = x* C(x-1, i-1). Sum of C(y, i <= y) is well known as 2^y.
An easier way:
Imagine i * C(N,i) as choosing i elements then a leader for them. It's the same as choosing the leader first, so we can choose a leader in N ways then complete all the remaining ways in 2^(N-1),
What's wrong with my solution in E? I just used Bron Kerbosch algorithm for finding maximal clique. http://codeforces.com/contest/839/submission/29455500
1 << n does not work for n > 32, because it uses 32bit integer. If you change it to 1ll << n your code works.
Oh, thanks! What a silly mistake!
For the Problem C, I basically calculated sum of expected value of terminal node using backtracking. I still don't get what's wrong with my code. I would appreciate if someone pick up the error of the following code. http://codeforces.com/contest/839/submission/29406965
I'm not sure, but I believe the problem is in getting data. The indexes of ends of edges can be in any order.
In other words, there is no guarantee that "to" is a child of "from".
Help me, please!
Here is my program for problem C: http://codeforces.com/contest/839/submission/29463210. But my solution is too slow. Tell me, please, how to fix it.
Arpa, Can you please explain the symmetry argument for the problem E in greater detail?
Precisely, this part :
It means that instead of x1 - a, x2 + a, .... Put x1 + a, x2 - a, ... and get the vise versa of the inequality, so it becomes equality.
I find problem B, statement very confusing!!! what does it actually mean by neighbour seat??? how the first sample test case describes the situation, authors solution seems unnecessary. Any help??
In each row, seats {1, 2}, {3, 4}, {4, 5}, {5, 6}, {7, 8} are nighbors.
I think the complexity of problem D should be n sqrt(k) because it will take this amount of time to calculate the values of the count array.
Look at NikaraBika's solution.
He calculated cnt here :
The complexity is n·log(n)
Oh yeah nice!.
does anyone have code of problem D's 1st method? I don't know how to implement the formula of ans[i]
Follow up for C:
What should be the starting vertex so that the Expected length is minimum ?
We can use rerooting technique.
for B, I found a case which did not appear in the testcases.
2 7 2 2 2 2 2 2 3
I thought the answer should be "NO" in the editoral. however, my code for this case is "YES" and I got accepted.
Can someone plz tell me what is wrong in my code in problem Div2 D.
https://ideone.com/tJhWMt Its getting error in test 44.
hello 839E can be found in chapter 6 of "Problems from the Book" ... the tutorial is exactly copied from PFTB ...
Can someone help me in problem C. I am summing up the expected values of leaf nodes :length(leaf node)* probability(leaf node). And probability of leaf node is calculated by subsequently multiplying the probabilities of the parents. Here is my code https://ideone.com/tgm1ro.
Can someone tell me the error in this code for ques C. cnt stores no. of leaf nodes. num stores sum of level of all leaf nodes. level of root node is taken as 0.
include <bits/stdc++.h>
using namespace std;
define pb push_back
define mp make_pair
define ll long long
vector adj[100005]; ll child[100005],level[100005]; bool vis[100005]={false};
void bfs(ll s,ll p) { queue q; q.push(s); vis[s]=true; level[s]=0; while(!q.empty()) { ll temp=q.front(); q.pop(); for(ll i=0;i<adj[temp].size();i++) { if(!vis[adj[temp][i]]) { level[adj[temp][i]]=level[temp]+1; vis[adj[temp][i]]=true; q.push(adj[temp][i]); child[temp]++; } } } }
int main() { ll n,x,y; cin>>n; for(ll i=1;i<=n-1;i++) { cin>>x>>y; adj[x].pb(y); adj[y].pb(x); } bfs(1,0); ll cnt=0,num=0; for(ll i=1;i<=n;i++) { if(child[i]==0) { cnt++;num+=level[i]; } } double ans=(double)num/cnt; cout<<fixed<<setprecision(15)<<ans<<endl; }
hmmm 839E seems to be copied from "Problems from the Book"
I have an another idea of Problem D(I don't know if anyone have said it before).
$$$\sum_0^n{C(n,i)*i}=\sum_0^n{C(n,i)*C(i,1)}$$$,it means that choosing i elements from n elements and chose one element from the i elements which we chose before.
It is also equal to chose one element from n elements and chose others in random.
So the answer is $$$n*2^{n-1}$$$.
My English isn't well,please excuse me,thanks.
Oh,sorry.It was problem D,not C.