


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3650 |
| 2 | Benq | 3582 |
| 3 | Geothermal | 3570 |
| 3 | orzdevinwang | 3570 |
| 5 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3532 |
| 8 | Radewoosh | 3522 |
| 9 | Um_nik | 3483 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |






Problem D-div2, B-div1 has a very weird situation, it's like what is the possibility that the given solution fail there must be,, it's just surprising to have such a problem and for B-div2 I think an overflow test in the pretests should exist
Yeah, this is the first time I've seen a non-deterministic algorithm used on CF. I assumed that their problems were always deterministic, so I just thought the problem was impossible and stopped working on it lol. That being said, I didn't actually calculate the probability of success when choosing k random indices, and you could write a program to calculate that probability for you and find the optimal k, so I do actually think it's a cool problem in hindsight.
Is this the first time that the intended solution to a problem was a randomized solution ?
I think so. This problem was also solved by many using randomized algorithm. However, the editorial came out and I found out there was a deterministic solution. I was quite impressed. The belief that contest problems did not intend randomized algorithm was still intact.
I was also wondering what the deterministic solution could be for this problem and I must say I am somewhat disappointed :/ I found the randomized algorithm for this problem quite early but there was always a chance for this failing so I did not submit
364D - Ghd
i don't like it when the same code got WA and AC
why the down votes?
I think it's for the bad English
Excuse me,am I the only one who has some difficulties understanding the editorial?
It is not ready. We will finish it tomorrow.
can someone explain Sorting by Subsequences more clearly and what is the maximum limit of cycles in subsequence . and thanks in advance _/_
Let b1, b2, b3, ..., bn be the sorted version of a. Fix x, 1 ≤ x ≤ n. Let x' be such that bx' = ax. Using DSU, merge the two sets containing x' and x. Do this for all x, and then count the number of disjoint sets.
I do the same but I get wrong answer http://codeforces.com/contest/844/submission/29757370
push i in findSet(i) in the list instead of parent(i) in the list as it is possible we haven't called findSet for that i yet and hence it will just show its parent. for e.g. Union(2,3) Union(1,2) so here we haven't called findSet of 3 hence parent of 3 will be 2 which will result in 2 lists first containing (1 and 2) and another one containing (3).
This Might sound alittle stupid but where did the 2^k — 1 come from in div2 B Thanks
https://en.wikipedia.org/wiki/Set_(mathematics)
Thanks,I get it now
Hedgehog? Bamboo? Anyone care to explain?
we need to convert each child of the centroid to star graphs hence i guess bamboo means chains and hedgehog means star graphs.
Bamboo makes sense for chains but how is hedgehog related to star graphs?
Because our friend the hedgehog
has many spines pointing outward, so she looks like a star graph.
In Russian star-graph usually called hedgehog-graph.
I still don't understand how to do that; how to transform each 'child' to a star graph? Wouldn't the centroid children change?
Could you explain to me why do we have to look for centroids whereas we could transform whole tree to "hedgehog" star graph by simply transforming it first to "bamboo" and then to star graph using exacly 2n operations?
Ok, I see it now, the "|Vx| > |Vy| condition must be satisfied".
Please upload the code for the model solutions as well. I understood the logic for Div 2 — C but it is hard for me to implement it.
you can see any other user's code.
can anyone please explain 843B(interactive LowerBound) , i couldnot understand it at all!
Let's suppose that we are following the approach of the editorial: we ask for the starting position plus 999 random points. Among all the answers to our queries, we get the greatest number less than or equal to x and we forward-iterate it 999 times.
For simplicity, fix n = 50000 and let's suppose that the answer is in a position such that it has at least 998 elements to its left (that is, there are at least 998 numbers less than the answer). We can see that if we have asked for at least one of the 998 numbers that are immediately previous to the answer or for the answer itself we are done, since we will iterate 999 times to the right and we will find the answer.
If we ask a question the probability of getting a number that is not the answer nor any of the 998 "good" numbers is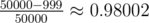 . However, we are going to ask 1000 questions, and the probability that all of these 1000 questions are about "bad" numbers is 0.980021000 = 1.7 × 10 - 9, which is very small. The probability to answer correctly 200 tests is (1 - 1.7 × 10 - 9)200 ≈ 1, which is ultra-high. This probability can be even greater if you make sure that you never ask for the same point twice.
. However, we are going to ask 1000 questions, and the probability that all of these 1000 questions are about "bad" numbers is 0.980021000 = 1.7 × 10 - 9, which is very small. The probability to answer correctly 200 tests is (1 - 1.7 × 10 - 9)200 ≈ 1, which is ultra-high. This probability can be even greater if you make sure that you never ask for the same point twice.
Finally, note two things: if the answer has less than 998 elements to its left then we will find it with probability 1 given that the first query is precisely the starting point. Also, the probability formula described above gives higher and higher probabilities as n becomes smaller, so you can be sure that this approach will work.
Regarding div2 D (div1A — 843B — Interactive LowerBound) apparently I am getting WA when I use rand() and I am getting AC when using 78*rand()%MOD+rand() (or any sort of strange transformation. Why is that? Isnt rand() random enough?
rand() is bounded by RAND_MAX which while it is guaranteed to be at least 32,767 on any standard library implementation, and a size of 2,147,483,647 or similar is relatively common it doesn't change the fact that the guaranteed maximum is 32,767 which is smaller than 50,000. If we were to place the solution in the ~17,000 where the random sampling would not reach, this would produce an WA.
Also, WA on tc 107 if you use random_shuffle once, and AC if you do it twice.
How is the checker for D2E/D1C implemented? Link/cut tree?
Centroid decomposition with FFT can be used to calculate count of each distance since maximum distance is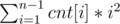 .
.
n - 1(cnt[i]is a number of pairs with distance between them equals toi). Then checkActually the sum of squares can be calculated with a single DFS in linear time. You just need to maintain the size of each subtree, the sum of distances from root of current subtree to all the vertices in it and the sum of squares of distance from root of current subtree to all the vertices.
We've used approach similar to Dynamic Connectivity Offline solution to check correctness of sizes in .
.
problem 2E/1C: I'm still inquisitive but I can't finish the "exercise" myself, is there additional explanation?
How to solve DIV-2/C using DFS?
You have to find all connected components in a graph, where edges are (original position in the array, position in sorted array). For example:
10
3 7 10 1 9 5 4 8 6 2
After sorting we have 1 2 3 4 5 6 7 8 9 10.
You have edges (4, 1), (1, 3), (3, 10), (10, 2), (2, 7), (7, 4); (5, 9), (9, 6), (6, 5); (8, 8). So we have 3 connected components, it's easy to see we can't have more than that. You can find the number of components using DFS.
Refer to my code for details 29740082
Thanks very much for this explanation. It is easier to understand than in official solution.
In Div-2 B why you didn't say that the subsets with different order are considered different ? I thought that {1, 2} is the same as {2, 1} :"D
it is the same
Div2 843D — Interactive LowerBound I had exactly the same solution in mind after I've solved A, B, C.
I sat for one hour during contest convincing myself that there should be a deterministic solution because it's CodeForces.
Good to know there are problems on CodeForces which require randomized algorithms to solve,
P.S. Proposal: Making special CodeForces Round devoted to randomized algorithms.
Guys, how to pass the 107th test on Div2 D? I've got no idea. Pls, help...
Test 107 is a hack against random_shuffle, after adding a second random_shuffle right after the first one it gets AC.
Thanks
Help me, please!
I tried to solve problem C. Here is my program: http://codeforces.com/contest/844/submission/29760854. But my solution was too slow.
I tried to fix it, but nothing happened. (http://codeforces.com/contest/844/submission/29775215 ).
Please, explain me why my my solution is too slow and how to fix it? Is recursion the only thing that helps to solve this problem?
Div 2 C/ Div 1 A: Why "We can split this permutation into simple cycles. The subsequences in the answer are subsequences formed by these simple cycles." ? Can someone prove it?
Assume we have a subsequence containing the element in position i in the original sequence. Let j denote the position of this element in the sorted sequence. Then to sort the sequence this subsequence must also contain j since i has to be moved there. Now we repeat the reasoning for j and so on and we eventually get a cycle.
bad solution
Can someone explain how to get star graph from a chain graph using centroid decomposition? As I understand, if we apply CD as it is to the chain graph, we get something similar to binary tree with log(n) levels, but not a star. Help, please! Thanks in advance :)
I think that there are graphs which cannot be changed into start. Degree of centroid in tree is unchangeable so if centroid don't have degree equal n-1 than we would never get a star.
Now I see They are not changing into a star. They are changing into centroid with stars.
I've made an experiment for 843B task (LowerBound).
It can be solved even like this :)
http://codeforces.com/contest/843/submission/29779241
http://codeforces.com/contest/843/submission/29779421
http://codeforces.com/contest/843/submission/29779484
I suppose the tests are chosen not to find the solution using any deterministic distribution.
That's why non-deterministic algorithms are not very good. Probability is an uncontrolled evil in this case.
Finally... It's back
Help please! For Div 2 D, I am getting WA on test 62. I am using mt19937 for generating random numbers. Code
Anyone can elaborate a bit more on Div2 problem E?
When it says "A centroid-vertex remains a centroid during such process. If we have two centroids in a tree, the edge between them couldn't change."
Is it a pre-requisite knowledge one should know in order to solve this problem; OR Is it a constraint / property of the tree we have to follow in the process in order to solve the problem?
If it's the latter, can someone explain why and a brief proof on it...?
I was wondering this problem too...Can someone give an answer please... If the tree has two centroids,if I change the edge between them,must the sum of squared distances between all pairs of vertices change to greater or it's not good enough...?(
Can anyone explain the last line of 843D tutorial please?! I can't understand how the dijkstra must be implemented!
DIV2 B.. using pow function (C++ stl) result in Wrong Answer on Test case 18... instead, use an array to store the powers of 2 (upto 50 (2^50) ).