


Hello everyone,
So I recently prepared a lecture for a Bulgarian camp on the topic since I find it quite wide and interesting. I have never seen an article discussing different approaches for the problem so today I am going to share my knowledge. Don't forget to give me your feedback, please!
Let's start with first defining the problem we are going to solve. We are given a set of N d-dimensional points. Q queries follow, each containing a d-dimensional point. We should answer each query with the distance (we will use Euclidean distance) to the point from the set which is closest to the queried one. This will be our main focus but we are still going to consider inserting/deleting points from the set when possible. It's important to say that for d > 1 we will consider only average-case complexity and we will assume that the points are distributed uniformly. Unfortunately, even the average-case complexity is exponential in the number of dimensions.
One-Dimensional NNS
Without doubt, the problem is really simple when d = 1. In the picture below, the dark blue point is the queried one and all other points belong to the set.

It is easy to see that for any point, the one which is closest to it is either the closest to the left or the closest to the right. This leads to a pretty simple solution: First we sort the initial set of points and for each query we use binary search to find its position in the sorted array which automatically gives us its predecessor and successor points.
Now what about insertion/deletion of points?
Well, we can pretty much use the same idea. We need to keep the points sorted and quickly find the position of each queried point. At this moment, it should be obvious that any binary search tree will do the job and std::set is a good example.
Locality-Sensitive Hashing for Two-Dimensional NNS
When we usually use hashing, we try to avoid collisions no matter what, right? Well, not here. We would like to find a function which maps relatively close points to the same or close numbers and not-so-close points to different/not-so-close numbers. You can try to come up with some good functions on your own. They don't need to be perfect, the one I am going to present is not guaranteed to work but as you will see, after repeating it a few times we can have some pretty decent chances of getting it right or at least very close. DO NOT continue reading if you are planning to spend some time thinking.
So, let's draw a few random lines (excuse me for being so bad at faking randomness):
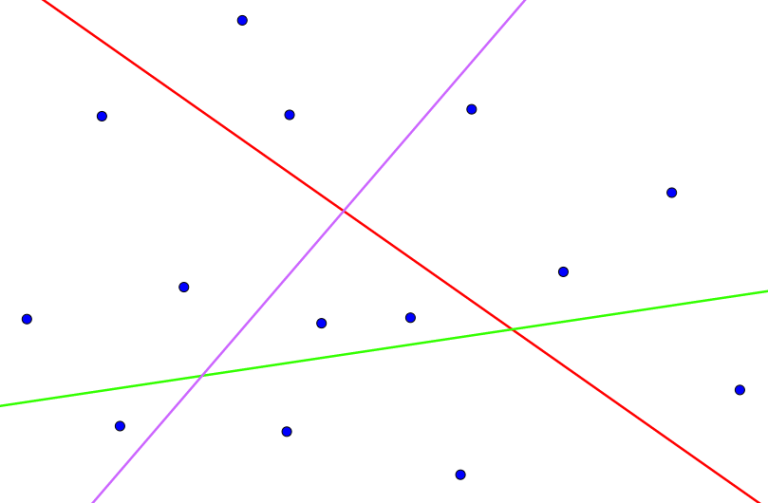
For each line, consider the two half-planes it creates. Let's write a zero next to each point from one of the half-planes and a one next to each point from the other. Something like this:
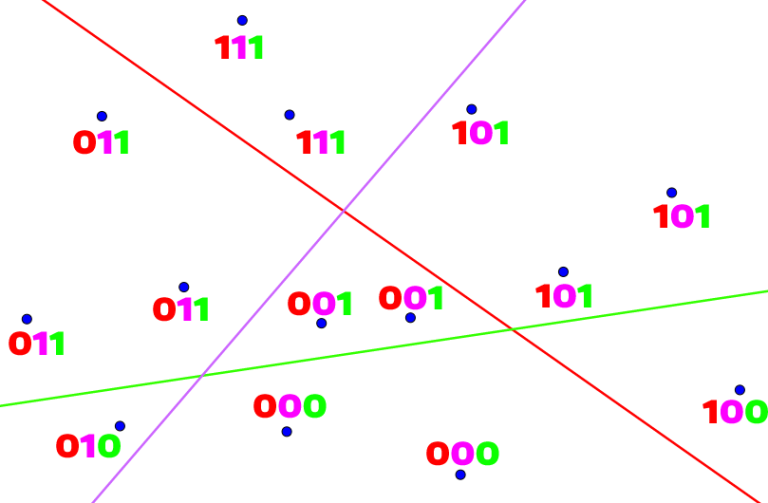
Now this binary code will be the hash for each point. When we are given a query point, we are going to find its hash according to the lines and only check the points having the same hash. Of course, we will need to get too lucky in order to answer many queries correctly with just one set of lines. So let's just generate as many sets as we can afford and check all points which have the same hash according to at least one set of lines. Let's say that we generate K sets with L lines each. Don't forget that we are talking about uniformly distributed points/lines and since there are 2L possible hashes for a set of L lines, the expected number of points in a bucket is 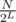 . So the complexity will be
. So the complexity will be 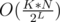 per query.
per query.
Inserting and deleting points is pretty much trivial since this algorithm is dynamic in its essence — the lines are generated before any points are read and then we hash them one by one and insert them in the proper buckets.
Although it is an elegant approach, it doesn't guarantee to give us a correct answer so let's move on to this structure called k-d tree.
K-Dimensional Tree for Small Values of d
So this structure can solve the problem for small number of dimensions (say up to 5) in O(logN) per query on average. We will see why it works only for small number of dimensions and that it is not exactly O(logN) but something more special after a few moments. I am going to explain it for d = 2 since d being 3 or 4 or 5 really makes no difference.
Let's start with the root of the tree which will be responsible for all N points. Let's sort the points by their X coordinate. We will draw a line which we will call a splitting line somewhere between the points in the middle in order to split them evenly. The X coordinate this line passes through we will call a splitting value for the current node (the root in the beginning):

Now all points from the first to the middle position go to the left subtree and the others — to the right subtree. For the subtrees we will repeat the same process but this time we will sort the points by their Y and the splitting line will go through some Y:
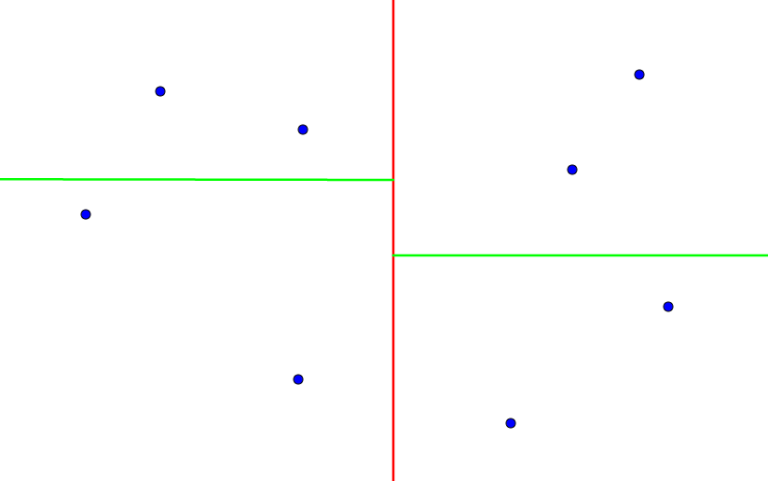
We will keep building the tree, alternating the axes we are splitting by until we reach a subarray with only one point which results in the so called leaf nodes. That is, each leaf node contains a point and each non-leaf node contains the splitting value and the axis it is splitted by:
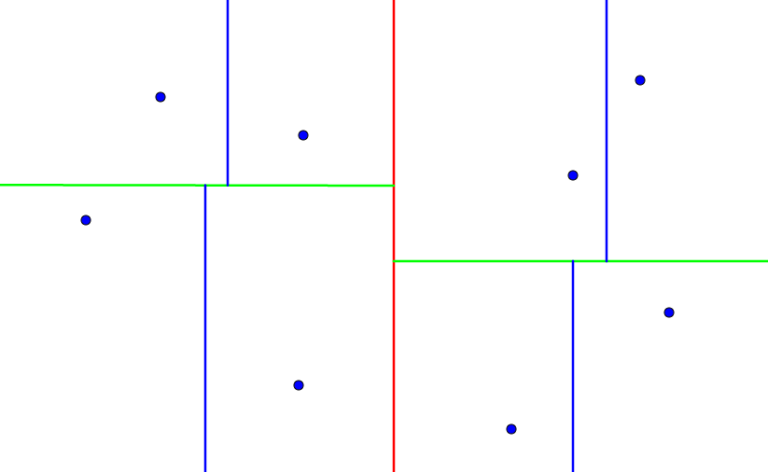
I will first explain how the NNS works and then discuss the complexity. It is actually a pretty simple recursion, you won't believe how simple! We start at the root with our answer (closest distance) set to infinity. If we reach a leaf node at any moment, we will just compare the current answer and the distance between the queried point and the point stored the current leaf. Now, I am assuming that we are in a non-leaf node. On each step, we check whether the queried point falls into the left or right subtree (assuming it was there). We don't need to be exact, if it lays on the splitting line, it doesn't matter if we consider this left or right subtree.
We will first recursively traverse the subtree our point falls into. "But we need to traverse the other one afterwards", you may say. And so will we but only if we need to. And by "we need to" I mean "there is a chance of encountering a closer point in the other subtree". Let Ans be the closest distance encountered so far, after traversing one of the subtrees and D be the distance from the queried point to the splitting line. It's easy to see that all possible candidates for better answer must be in the circle with center the queried point and radius Ans. So we will traverse the other subtree if and only if Ans>D, that is there are some points in the other subtree which are in the circle with center the queried point and radius Ans. And this is it — as simple as it is. Notice that the distance between the queried point and the splitting line is just the absolute difference between the splitting value and the corresponding coordinate of the queried point.
Let's see why this is O(logN) (not exactly O(logN), as I said, but we will get back to that soon). I don't think this qualifies as a formal proof but just to give you an idea. Take a look at the last picture and you will see how every leaf (point) is bounded by some rectangle. So we get some N rectangles in total. We can assume that our plane is bounded by some very big square. For our uniform distribution, we can expect each of those bounding rectangles to have similar sizes or to be more precise similar sides. That is, we can expect our big square (the plane) to be divided into  by small squares or something really close to such configuration.
by small squares or something really close to such configuration.
Consider some query. What the recursion will first do is find one of these small squares our queried point falls into and set the distance between the queried point and the point in that leaf as the current answer (O(logN) so far). Say that it is Ans. Of course, traversing only this small square is not enough, and we will need to consider some more (those within radius Ans). However, by gives us a tight bound on Ans —  . Which means that we will only need to consider the squares surrounding this current cell (which happen to be 8), if the distribution is perfectly uniform. So the average complexity turns out to be around O(8 * logN).
. Which means that we will only need to consider the squares surrounding this current cell (which happen to be 8), if the distribution is perfectly uniform. So the average complexity turns out to be around O(8 * logN).
"But we don't consider constant factors when talking about complexity", may come to your mind. This is true. As you remember I said that the complexity is not really O(logN) and is exponential in the number of dimensions. Do you see where this is going? This 8, the number of surrounding squares for a unit square, is actually 3d - 1. And here you go, the average-case complexity for a k-d tree query is actually O(3d * N).
Inserting a point is actually pretty straighforward — we find the leaf which would contain this point if it was in the set (but actually contains another one). Then we just find a splitting line between the two points — the one in the current leaf and the one being inserted and treat this as an internal (non-leaf) node.
Deleting a point will be just finding the leaf that contains it and detaching it from the tree.
Vantage-Point Tree
This is a data structure which is a representative of another class of trees — ball trees. It is really similar to the k-d tree in the way it works and has similar complexity but it uses circles instead of lines to form the left and right subtree.
I won't be posting pictures but only explain the idea quickly since it has only minor differences with the k-d tree. The root again contains information about all N points. On each step we randomly choose the so-called vantage-point for the node among all points this node is responsible for. Then we sort all points by their distance to the vantage-point. We choose a radius (the so-called threshold), which is the distance between the vantage-point and the middle point after sorting. Then we build the left subtree over the first half (those inside the circle) and the right subtree over the second half. It's not a problem if some of the points from the right subtree lie on the circle. Then we recursively build the left and right subtree.
When we query some point, we again start at the root with our answer set to infinity. Every time we visit a node, we compare the answer and the distance between the queried point and the vantage-point for the current node. Then we check if it falls inside the circle or not. Depending on that, we first traverse the left or the right subtree, respectively.
After that, we will visit the other subtree only if there is a possibility of finding a better answer. Say that the threshold for the current node is T, the current answer is Ans and the distance between the queried point and the vantage-point is D. If we first visited the left subtree, then we will go to the right one if and only if D + Ans > T. If we first visited the right subtree, then we will go to the left one if and only if D - Ans < T.
For reference, consider this problem: http://www.spoj.com/problems/FAILURE/
My k-d tree solution: https://ideone.com/yDBOyc
My VP tree solution: https://ideone.com/o1wTNS
It is also worth mentioning that the linked problem is a special case of the nearest neighbor search — it only asks about points from the set which has a pretty neat O(NlogN) divide and conquer solution but I am too tired to explain it right now.







I like the hashing.
So, what is the complexity of search if we use Vantage-Point tree?
It is again "O(logN)" for small dimensions but I don't know how exactly the number of dimensions affects it and if it is again O(3d * logN). I find it way harder than k-d tree to get some intuition of why it is around O(logN) so I am just talking based on the papers/blogs I have read some time ago. I wouldn't go for it when I encounter a problem because of this reason but I think it is still an interesting alternative I knew about so I mentioned it.
I also like the first tree.
The second tree sounds even better than the first one.
Finally I read the blog and I liked it very much.
Wow, I just saw the part about the problem in 1D and found it really intriguing.
Hi,
I tried to solve the problem given in the end of the blog — FAILURE. But I got WA. Would somebody be kind enough to look in my messy code and try to find my bug?
code
Thanks in advance!
Thanks for your great interest in my blog :D
The code gets accepted after replacing
with
on line 74.
Thanks :)
Can somebody provide me with some problems on this topic?
Actually, there aren’t many problems on this topic. Maybe because it works only for random points.
Nice problem for this is finding Euclidean minimum spanning tree.
I think there's a typo in this line:
"And here you go, the average-case complexity for a k-d tree query is actually $$$O(3^d * N)$$$."
Shouldn't it be $$$O(3^d * logN)$$$?