


Hello!
Guys, I'd like to know how to find the largest common pallindrom of N (1 <= N <= 15) strings. I know the Manachers algorithm finds in linear time for a string. How would I find the common N-strings?
Thank you: D
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | ecnerwala | 3648 |
| 2 | Benq | 3580 |
| 3 | orzdevinwang | 3570 |
| 4 | cnnfls_csy | 3569 |
| 5 | Geothermal | 3568 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3530 |
| 8 | Radewoosh | 3520 |
| 9 | Um_nik | 3481 |
| 10 | jiangly | 3467 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | adamant | 164 |
| 2 | awoo | 164 |
| 4 | TheScrasse | 160 |
| 5 | nor | 159 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 150 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Hello!
Guys, I'd like to know how to find the largest common pallindrom of N (1 <= N <= 15) strings. I know the Manachers algorithm finds in linear time for a string. How would I find the common N-strings?
Thank you: D






You could probably pre-compute some numbers like "what's the longest palindrome that is centered around position i" for every string and use suffix array with LCP + binary search on the length using a two-pointer algorithm to find the answer.
I'm not that sure since I've never used suffix array for anything nor do I know how Manacher's algorithm works.
Palindromic tree will work:
As the number of strings N ≤ 15, for every vertex in the tree we can save a mask of all strings in which the corresponding substring appears. This can be done by simply building the palindromic tree for all strings and then for every preffix vertex (the last vertex before adding a letter) we change its mask (we add the current strings index to the mask). Then after the building we iterate all vertices, starting from the longest one, and we add the current vertex's mask to its link's mask. After that, the strings we are interested in are the ones with mask equal to 2N - 1 (if we use 0-indexing for the strings).
PS: There is a way to do this for N ≤ 106 by building virtual trees. If anyone is interested I can explain.
Could you explain?
You build another tree (the vertices are kept the same but the edges are changed), such that there is an edge between u and linku for every u. This will help us, because now every node contained as a suffix in this node, is on the path from the root of our tree to this vertex.
Now for every of the N strings we mark every preffix vertex/node. All palindromic substrings occuring in the current tree are those which have a marked vertex in their subtree. We will add for all these vertices +1. This can be done by building a compressed tree of the marked vertices (virtual tree).
After this the strings/nodes which we are interested in are the ones with value equal to N.
The complexity will be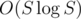 , where S is the sum of lengths of the trees.
, where S is the sum of lengths of the trees.
You can solve it with suffix arrays. You can binary search the length of the largest common palindrome: Consider you are verifying for length X. Go to the first string and find a palindrome of length X(you can do this in a lot of ways) and then check whether that substring appears in all the others with your suffix array. Considering you have L=max length of a string, the time complexity would be O(N*L*logL + logL*L*N*logL) or something similar(N*L*logL for suffix array and logL(binary search)*L(finding palindrome)*N(going through the other words)*logL(finding whether the palindrome I found in the first string appears in my current substring by binary searching on the list of sorted suffixes)).
Good day to you,
Firstly — if I'm not mistaken, the statement (might?) be similar to this. As long as it is true, I've just mentioned an approach here (even though I admit I write bad hints), which solves the problem using Binary Search + Hashing. If I'm not mistaken, it is slightly similar to arif.ozturk solution (even though it uses different machinery).
Complexity of the solution is O(n|s|log(|s|)2) (or O(n|s|log(|s|)) with proper sort :) )
Good Luck & Wish you a nice day!
.