


UPD. Everything that will be described below is already used by tourist for a long time, for example, in his last submission.
In ancient problems on russian competitive programming cites, memory constraints are often extremely small and equal to 16 MB, 32 MB, 64 MB. Most likely, for modern memory constraints of 256 MB and 512 MB, the method described below for achieving the minimum memory consumption for the segment tree is not relevant, but still consider a method that allows it to be achieved in the top-down implementation. We will use exactly 2·n - 1 nodes, and number the vertices in the Euler Tour order:
0
1 8
2 5 9 10
3 4 6 7
Then, if we are in the node v and this is not a leaf, then it has left and right subtrees. The vertex of the left subtree is v + 1, because, in the order of the Euler Tour, we will visit it immediately after the current node. As for the right subtree, we will go there only when we visit the current vertex and all the vertices of the left subtree. The number of vertices in a subtree depends only on the length of the segment corresponding to the tree node.
We assume that if we have a segment [l, r], then the left subtree corresponds to the segment [l, m], and the right one — [m + 1, r], where m = (l + r) / 2. Then the length of the left segment will be equal to m - l + 1, and the number of nodes in it is 2·(m - l + 1) - 1.
Finally, we find that for the node v corresponding to the segment [l, r], the left subtree in the numbering in the Euler Tour order will be v + 1, and the right one — the vertex v + 2·(m - l + 1), where m = (l + r) / 2 — the midpoint of the segment [l, r].







http://codeforces.com/blog/entry/18051 — same tree with different traversal
Simple and great idea! But I didn't get the last line.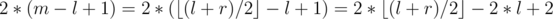 which is r - l + 2 if l and r have same parity and r - l + 1 otherwise.
which is r - l + 2 if l and r have same parity and r - l + 1 otherwise.
Looks like I forgot to multiply on 2 after division. I mean that we need to add 2·leftLen to v, but leftLen is the half of rootLen = r - l + 1 after division. Correct formula is
v + (r - l + 1 + 1) / 2 * 2 = v + (r - l) / 2 * 2 + 2, so with midpoint formula looks more easy, I will remove last abstractThis idea is mostly based on cache locality rather than memory consumption.
I've seen this while studying cache-oblivious data structures. Such tree works significantly faster than most others, because it is cache-friendly. (subtree of vertex v contains of some interval [l..r])
Had some benchmarks made for such tree, but can't find them right now.
Sorry, can't reproduce speed up from cache optimizations. Tried on problem with 1.000.000 items and queries increment values on segment by constant and get maximal value on segment.
0.7 svs0.7 sfor both orders: Euler Tour order, simple orderCan you, please, found experiments what you did?