


Hello! As the tasks are not uploaded on the official website of BOI2013 and I couldn't find them around the web (sorry if they are already posted), i decided to post them myself, as i was a participant in the competition itself. Unfortunately I lost the English papers for day 1 and had to translate the Bulgarian versions, please excuse my English in the day 1 statements. Also I have no scanner so i had to type myself the whole tasks in word, so I hope there aren't any mistakes :).
Day 1 tasks:
Day 2 tasks:
Ancient cryptography [10s time limit, around 2GB memory limit]
The codebook [around 1.5s-2s time limit]
The Kebab eating contest [around 0.5~1s time limit]
Here are my solutions/ideas to the problems, do not read if you plan to solve them yourself.
Mastermind
To anyone who has played Bulls and Cows as a kid that shouldn't be a very difficult task. It is with relative scoring so you can pretty much play greedily. The solution is to keep all currently possible codes. Once you get a question, you iterate over all possible answers you can give, and check what codes actually correspond to those answers, then you give the answer that will result in the most codes remaining. The algorithm is good enough to get full score.
Old computer
The idea is simple, we want to choose a maximum set P of those pairs a[i],b[i], in some order such that a[p1]<a[p2]<a[p3]... and b[p1]<b[p2]<b[p3]. Well the simplest way to do that would be to sort the pairs in increasing order of a, and then get the Longest Increasing Subsequence in b. However we must sort them in increasing order of a AND decreasing order of b secondary, to avoid taking a few pairs with the same a.
Complexity of the algorithm is O(m*LOGm). If (as it happened for some people), this time limits in subtask 3, where m<=4,000,000 , then you can write a separate O(n^2) solution for it.
Resting residence
Biggest problem in this task is understanding the statement perfectly. So well, we can assume that every time you move through an edge, you receive "one magic point", that you can later use to rotate a pentagon without using energy (because it will be equivalent to rotating it while you were taking those "magic points"). Also you are able to do a "combo move" by rotating a neighbour and immediately moving to it. Such moves take only 1 energy and don't give you a magic point. Now how to solve the problem? Well we can "expand" our graph, creating a state [current vertex][rotation of current vertex][magic points left]. With some thinking we can realize what edges would come out of each vertex and actually construct such graph of size around N*5*N. After that we can simply use Djikstra to compute the path to N, note that it will be a good optimization to break as soon as we find the best path to N and not wait until Djikstra finishes, since the optimal path will hardly ever be too long.
Ancient cryptography
Now if you have heard of Aho–Corasick, then probably that was the first thing in your head. I had only heard the algorithm at the time of the competition and didn't know how to implement it, so I panicked a little bit thinking it might be the only solution, however fast enough I came up with a good idea that the constraints allowed.
We can observe, that in the largest subtask 5, w<=15 and in the others w is usually a relatively small number too. So we don't have many different lengths. So how to use that? Well what we can do is actually use a hash on all words in the dictionary, and put them in sets separated by their length. Then what we can do is we can iterate from w to 1 and check for every possible length if there is word with that length. We can do that by simply doing a "rolling hash" over our large string and checking if the current hash is the same as some word from the dictionary with the corresponding length after every roll.
The total complexity is O(w*x*logm). 10s should be enough.
Note: Of course, if you can implement Aho-Corasick, that would be a way better solution :)
The codebook
Now obvious solution is O(N!), however that would work only on the first two subtasks. First, note that basically what you have to find is (P-1)*B+Q-th lexicographical correct(according to their rules) permutation. Let's create a graph. The nodes will be the values of A and there will be an edge between vertices i and j, if and only if GCD(A[i],A[j])>=K. So, one can easily notice that every correct permutation corresponds to a Hamiltonian Path in our graph. Well, finding such a path is NP-complete problem which can be solved in O(2^N*N). We can do exactly that here, we will use DP with state [bitmask of used vertices][current vertex] that will give us the amount of Hamiltonian Paths that can be created from that state. It is now not that difficult to get the (P-1)*B+Q-th lexicographical path, which would be the answer to the problem.
The total complexity is O(2^N*N). Surprisingly there is a chance that recursive implementation is too slow, so iterative would be the safest way.
The Kebab eating competition
Well, as every experienced contestant would guess, we will process everything chronologically. So what we need is a structure that supports the following 2 queries :
- Add a restaurant that serves sandwiches with A kebabs (called when restaurant is opened)
- Return the sum of the B largest numbers (obviously optimal buying, called when a competitor can buy)
Well, it turns out that those queries aren't difficult at all. One competitor from my team solved it using AVL trees, another solved it using Treap, and i solved it using Segment Tree (simplest in my opinion). My idea was that simply a node in my Segment Tree would hold the amount of restaurants in its segment, and their sum. I process the queries the following way:
- I increase the A-th leaf's restaurants with 1, and its sum with A, and update the path to the root.
- I start from the root, if the right child has more restaurants than money i have, i go there recursively. Else i get the sum of the right child's tree (i buy all the sandwiches there), remove the money i had to pay (the amount of restaurants) and go recursively to the left child.
The total complexity of the algorithm is O( (n+m)*LOGmax_size ), and since size[i]<=20,000, then max_size=20,000 and the algorithm is obviously fast enough to solve the problem :)
Sorry if my solutions are unclear or there is a mistake in some of the statements, i tried my best :)







Yeah, those problems were really easy.
Kebabs can be solved with a BIT (Fenwick tree) + binsearch, which we can imagine as an array supporting operations "A[pos] +=x" and "return sum(A[i]); i <= pos" in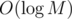 time.
time.
First, sort the numbers of kebabs per restaurant in non-increasing order. As the restaurants are opened, we'll add them to a BIT (initialized with zeroes) to the same position as in that sorted order, and also change 0 to 1 in another BIT. From the second one, we get the largest K such that the sum of first K elements is at most B (index of the Bth largest kebab), and then from the first one we'll get the answer: sum of first K elements (B largest kebab packages from opened restaurants).
The number K we find by binsearching — the sum of first K elements of the 2nd BIT is obviously non-decreasing. Total time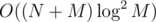 .
.
Added day 1 tasks (took me a lot of time to translate them), and my solutions for them, excuse me if my English isn't perfect in the tasks, especially "Resting residence", it was a difficult task to understand even in the original English version.
Oh, day 1. Nice. I guess the low score on "pentagons" was partly due to the confusing statement...
As to "computer": Fenwick tree strikes again! Possibly the best approach to LIS, due to its low constant (see 443701). The idea is pretty direct: the tree has size maxM, and for every element (value) of the sequence, we remember the LIS found so far ending with it. Since we compute it as 1+max(LIS ending with smaller elements), that's just one query, and then 1 update.
Note that if maxM > N, we need to compress the values into the interval [0, N). That can be done using an STL map, and is not necessary in subtask 3 (that'd probably TLE).
About "pentagons", yea that was one of the reasons of low score, it took me like over an hour to understand the correct statement and what I am supposed to do. Though i had more than enough time to solve it, I kind of failed there :D.
And about "old computer", yea that is exactly the approach I used in the competition itself :)
Thank you Encho, and congratulations for the gold!
Thank you, congratulations to you for your gold too! :)
Anybody have practice tasks ?
At the practice session we weren't provided with the paper statements, so I don't have them, there were 4 practice tasks, and only one of them was challenging, the rest were quite straightforward and simple.
It is a famous task — the two egg problem. However it was extended to be K-egg problem here. You have a N-storey building and K eggs. If you drop an egg from floor higher than P, the egg will break, else the egg won't break. Once an egg is broken it can not be used anymore, if it doesn't break, it can be used again. You are given N and K, and the task is interactive. You have to call DropEgg(A) which means you are dropping an egg from floor A, the function returns true if it breaks, or false if it doesn't. Your goal is to find P with minimum amount of calls to DropEgg().
For K=2 the task is famous and you can easily google a solution. For K>logN, one could obviously do binary search and for K=1, it is obviously linear. However in the rest of the cases, one should find a clever solution. I think only one competitor solved it for full score (my teammate Hristo Venev, who got a full score in the competition). He said that he solved it by dynamic programming.
For the last subtask, I believe the constraints were N<=10,000,000 | K<=10,000
So thanks.
Why we can't use Binary Search in this problem ?
Problem is, we have limited amount of allowed "breaks".
Imagine N=100, and K=3, so we have 3 eggs and 100 floors, and imagine that anything above floor 5 breaks. First egg we will drop at 50, it will break, next we will drop at 25, it will break, next at 12, it will break. Now we know that P is 1~11, but we don't have any eggs left. Therefor, we can not determine P.
Ok thanks , now i understood it. Yes you are right the problem's solution must be difficult.
Good share! Thank you!
The links to the problem statements appear to be down, I found them on Wayback Machine and reuploaded them here.