


Hello!
If you've learned the simplex algorithm and a minimum cost flow algorithm, perhaps you've also heard about this fancy thing called network simplex which is supposed to be a specialization/optimization of the simplex algorithm for computing a minimum cost circulation. If your google search didn't turn up any interesting results or your interest faded, you might have moved on to other subjects.
Well I didn't! So this is a tutorial on network simplex (NS) for the minimum cost circulation problem. I'll describe and formulate the problem, show how it relates to the usual minimum cost flow problem, explain the theory behind the algorithm in-depth, and then derive the implementation details.
Introduction
The algorithm commonly used in competitive programming for this sort of task is a minimum cost flow algorithm based on finding augmenting paths in a flow network. A flow network is a directed graph with a designated source $$$s$$$, a sink $$$t$$$, and edges with capacities and costs. This algorithm computes minimum cost flows from $$$s$$$ to $$$t$$$ by finding the cheapest augmenting paths in the residual network and saturating them, one at a time. I will call this the MCF algorithm.
Now, the network simplex algorithm we'll see here works in a slightly different setting, on what I'll call a circulation network. A circulation network is also a directed graph whose edges have capacities and costs, but whose nodes have an additional supply value, indicating the amount of flow that should pass through the node (in a flow network this value must be $$$0$$$ for every node except $$$s$$$ and $$$t$$$). Flow "entering" a vertex increases the excess of the node, and flow "exiting" a vertex decreases it.
There is no designated source or sink. Instead we have nodes with positive supply — which can be seen as suppliers of flow — nodes with negative supply — which can be seen as destinations or consumers of flow; and nodes with zero supply, which are intermediate transshipments nodes. A circulation is then an arbitrary assignment of flow values to the edges. The circulation is feasible if it meets all the supply and capacity constraints, as we'll see below. In general, the sum of the supplies of all nodes should be $$$0$$$ for a feasible circulation to exist.
Under this setting, minimum cost circulation is simply the problem of finding the minimum cost feasible circulation. The contribution of an edge to the circulation cost is just the amount of flow going through that edge multipled by its unit cost, just like in the MCF algorithm.
The network simplex algorithm is a specialization of the simplex algorithm for this task. As you'll see below, this problem can be formulated as a pretty short linear program, and thus solved by any LP solver. However, a direct application of the usual simplex algorithm has a complexity of $$$O(VE)$$$ per pivot, and a similar memory requirement to represent the tableau. By analyzing the linear program more carefully and the structure of its solutions, we will find a way to perform a simplex-style algorithm directly in the graph and achieve $$$O(V)$$$ expected time per pivot with $$$O(V+E)$$$ memory, leading to an extremely fast algorithm for most instances.
A few more observations about this circulation network setup before we proceed. We can convert a circulation network into a flow network, and solve circulation problems as flow problems, as follows. Add two dummy vertices $$$s$$$ and $$$t$$$ to the circulation network, link $$$s$$$ to supply nodes, demand nodes to $$$t$$$, both using edges of $$$0$$$ cost and capacity equal to the supply/demand at the respective nodes. What we have just done is built a graph where any maximum flow from $$$s$$$ to $$$t$$$ that saturates all the extra edges out of $$$s$$$ and into $$$t$$$ can be converted into a feasible circulation (by just removing these dummy nodes and edges). In particular, the minimum cost circulation problem is now the minimum cost flow problem, which we can solve with the MCF algorithm. Example transformation of a circulation network with 5 nodes, 1 supply node and 2 demand nodes:
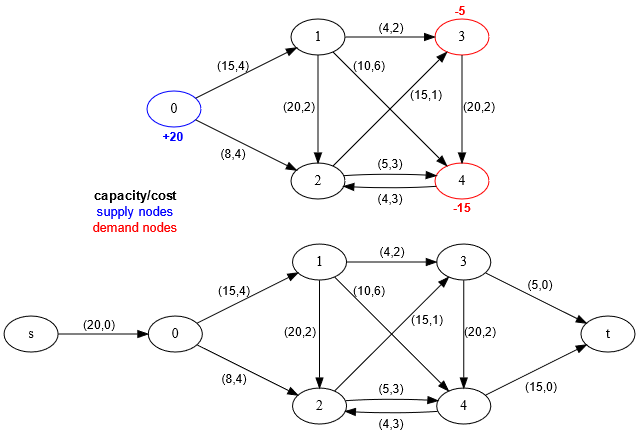
So if we can always perform this reduction, why do we need a specialized algorithm? First, the MCF algorithm cannot handle negative cost cycles since its core algorithm is Dijkstra, and in many cases the presence of such cycles is not an issue; LP solvers have no such problems, and so neither will the NS algorithm. In fact, the MCF algorithm has issues with negative edge costs in general, requiring a special initialization with SPFA/Bellman-Ford on the first run that can be very expensive. Secondly, the NS algorithm is just lighting fast in comparison, as it gets all of the benefits of the simplex algorithm for free, namely a very low number of pivots on average, proportional to the number of constraints. Network simplex will run with a time complexity of $$$O(VE)$$$ on average, and with a pretty good constant.
The rest of the tutorial is structured roughly as follows. First we'll formalize the problem as a linear program. Then we'll study the structure of corner points solutions and prove the main correctness theorem. This will show us how to visualize what the simplex algorithm would do in the context of our graph. Then we'll go over all the tasks the algorithm must perform and solve them one by one, as if we were designing it from scratch. At the end I'll provide a simple implementation that you can also follow while reading.
Prerequisites: Obviously, you need to be familiar with the setting of flow problems in general, but no in-depth knowledge of any algorithm is actually required. A good understanding of linear programming and the simplex algorithm is needed to follow along in the theory section comfortably.
References:
- Main reference from MIT OCW.
- The LEMON library has a reference implementation with many optimizations, and includes a paper with benchmarks and some implementation notes.
- Cornell Lecture notes, Williamson
Theory
Linear program formulation
Let $$$G=(V,E)$$$ be a directed graph with node set $$$V$$$ and edge set $$$E$$$. Let $$$\text{out}(u)$$$ and $$$\text{in}(u)$$$ be the set of edges exiting and entering vertex $$$u$$$, respectively. Every edge $$$e$$$ has a positive capacity $$$\text{cap}[e]$$$, a cost per unit of flow $$$\text{cost}[e]$$$ (no constraints on sign), and a flow amount $$$\text{flow}[e]$$$ to be determined. Every vertex $$$u$$$ has a supply value $$$\text{supply}[u]$$$.
We will represent a circulation in $$$G$$$ by $$$E$$$-dimensional points such as $$$x=(\text{flow}[e_1],...,\text{flow}[e_E])$$$.
We can formalize the minimum cost circulation problem as a linear program over $$$E$$$ variables, the edge flows, as follows:
The first set of constraints are the flow conservation/supply constraints. These require the amount of flow passing through vertex $$$u$$$, the excess of $$$u$$$, to be exactly equal to $$$\text{supply}[u]$$$. The second set of constraints are the capacity constraints. There are exactly $$$V+E$$$ constraints, so there really is hope of solving this efficiently, even with the simplex method.
Observation: The problem is never unbounded, as the feasible region is contained in the box between $$$(0,...,0)$$$ and $$$(\text{cap}[e_1],...,\text{cap}[e_E])$$$.
So now let's see how we would solve this linear program using the simplex method.
- Find an initial feasible solution.
- If the origin $$$x=(0,...,0)$$$ is in the feasible region then we are done.
- Looking at the graph, if setting $$$\text{flow}[e]=0$$$ for every edge satisfies all constraints, then this is trivial and we are done.
- Otherwise, the origin might violate some constraints. Add one artificial variable to each such constraint whose initial value is the right hand side of the constraint, and solve the transformed artificial problem to find a feasible solution.
- Looking at the graph, only the supply constraints might be violated. Just suppose they are all violated, and add $$$V$$$ artificial variables $$$a_u$$$, one to each supply constraint/vertex. We get the transformed constraints shown below. This case virtually always applies.
- If the origin $$$x=(0,...,0)$$$ is in the feasible region then we are done.
- Optimize the solution: Perform a pivot for as long as there are variables that can enter the basis.
How does the initial simplex tableau get built? The capacity constraints are inequalities, so they each get a slack variable with $$$0$$$ cost and initial value $$$\text{cap}[e]$$$.
Now most simplex implementations will assign a cost of $$$1$$$ to all artificial variables, temporarily set the cost of all normal variables to $$$0$$$, and optimize to find a minimum cost solution of the artificial problem. This must have $$$0$$$ cost for a feasible solution to exist, meaning all artificial variables were set to $$$0$$$ and can be discarded. Then the original costs of the normal variables are restored, and the algorithm is run again to find the optimal solution of the original problem.
We will do something different. We can assign a cost of $$$\infty$$$ (to be defined) to all artificial variables, $$$0$$$ cost to slack variables as usual, and retain the cost of all normal variables. If our $$$\infty$$$ is large enough, then the optimize step will just find an optimal solution to the original problem outright, or fail if one doesn't exist. The value of $$$\infty$$$ must be large enough for this to work.
Corner points are spanning tree solutions
The simplex algorithm moves along corner points of the feasible region (also called extreme points). These are points that lie on the boundary between the feasible and infeasible region, and are not the half-way point of any other two distinct feasible points. We will now take a moment to study these corner points in the context of our program.
Consider an edge $$$e$$$ which has a certain amount of $$$\text{flow}[e]$$$ passing through it. We can imagine an implicit backward edge that has $$$\text{cap}[e]-\text{flow}[e]$$$ flow going through it. Many flow algorithms will represent these edges explicitly in a residual graph; we will not do it here.
With this notion, we can push $$$\text{cap}[e]-\text{flow}[e]$$$ extra flow forward along $$$e$$$ before it saturates, and we can push $$$\text{flow}[e]$$$ extra flow backward along $$$e$$$ before it saturates/empties.
Consider a cycle $$$C$$$ in the original network, one where we are allowed to go forward or backward along each edge. We can "send $$$f$$$ flow" or "push $$$f$$$ flow" along this cycle by adding $$$f$$$ to the flow of forward edges and $$$-f$$$ to the flow of backward edges in $$$C$$$. The supply conservation constraints are unaffected, since the same amount of flow was added and subtracted from every node in the cycle. We can also talk about saturating pushes: for any cycle there is one maximum such $$$f$$$, as any forward edge cannot go over $$$\text{cap}[e]$$$ flow and backward edges cannot go under $$$0$$$ flow. So if we saturate this cycle, which means we send this maximum $$$f$$$ flow through it, at least one forward edge $$$e$$$ will reach $$$\text{cap}[e]$$$ flow or one backward edge will reach $$$0$$$ flow. In either case we can say such an edge became saturated and did not allow more flow to be sent along the cycle.
Given a circulation $$$x$$$, we'll call an edge $$$e$$$ free if $$$0<\text{flow}[e]<\text{cap}[e]$$$, and we'll call a cycle free if all of its edges are free. Essentially, we can push a (possibly very small) amount $$$f$$$ of flow forwards or backwards along these edges/cycles.
The following example shows a free cycle on the left, as flow can be pushed through it in either direction. The other two cycles are not free, as they contain empty or saturated edges.
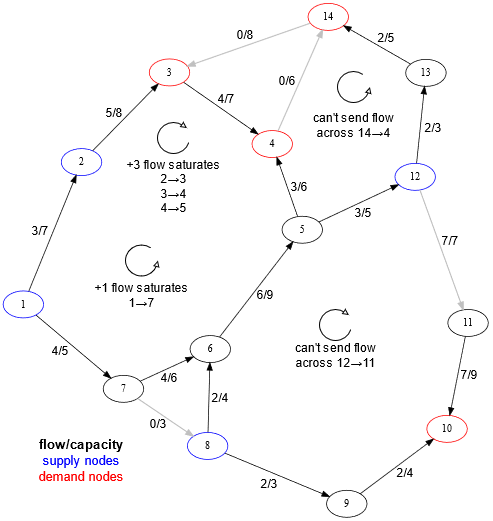
We'll now prove the main theorem behind network simplex.
Lemma 1. Any feasible circulation $$$x$$$ is a corner point of the feasible region iff there is no free cycle in $$$x$$$.
Let's look at lemma 1 the following way. If $$$x$$$ is a corner point solution, and the set of free edges cannot form cycles, it must form a forest. Then for the solution $$$x$$$, we can partition the graph's edges $$$E=T\uplus L\uplus U$$$ into three pairwise disjoint sets, as follows:
- $$$T$$$ Spanning tree set — A spanning tree or forest, whose edges $$$e\in T$$$ can have any adequate flow.
- $$$L$$$ Lower set — Every edge $$$e\in L$$$ has $$$flow[e]=0$$$.
- $$$U$$$ Upper set — Every edge $$$e\in U$$$ has $$$\text{flow}[e]=\text{cap}[e]$$$.
We explicitly allow $$$T$$$ to contain saturated edges (with $$$0$$$ or full flow, that would otherwise belong to $$$L$$$ or $$$U$$$). This means the partitioning maintains its properties when $$$T$$$ is a forest and we move an edge $$$e$$$ in $$$L$$$ or $$$U$$$ to $$$T$$$ without creating a cycle in $$$T$$$. For convenience we can assume $$$G$$$ is connected for now, so turning $$$T$$$ into a spanning tree by moving some edges is always possible. The algorithm later will do its work on a connected graph even if $$$G$$$ is disconnected.
Conversely, if a circulation $$$x$$$ can be partitioned this way, then it clearly has no free cycles. We will henceforth call these spanning tree solutions/circulations, and remember they are equivalent to corner points.
So why did we do all this work? Now is the time to get creative! Pick a spanning tree solution $$$x$$$ and pick any edge $$$e\not\in T$$$. If we added $$$e$$$ to $$$T$$$ we would form a (unique) cycle $$$C$$$. If $$$\text{flow}[e]=0$$$ we might be able to push flow forward through $$$C$$$, and if $$$\text{flow}[e]=\text{cap}[e]$$$ we might be able to push flow backward through $$$C$$$. If we make one such saturating push, such that another edge $$$e_{out}\in T$$$ becomes saturated/empty, we can remove $$$e_{out}$$$ from $$$T$$$, break the cycle, add $$$e$$$ to $$$T$$$, and get another, different, spanning tree solution!
The following image shows an example. The spanning tree $$$T$$$ is initially made up of all the edges shown except $$$e_{in}=(6,10)$$$. After identifying the cycle $$$C$$$, we see that the maximum amount of flow we can push through it (which goes backwards through $$$e_{in}$$$) is limited by $$$(1,2)$$$ and $$$(7,8)$$$, which are the candidate $$$e_{out}$$$ edges.
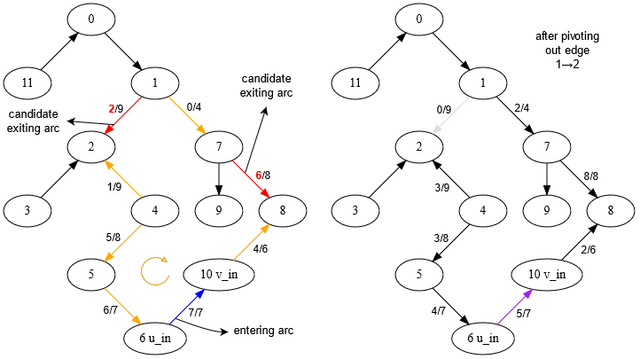
What we have just done here is find a way to pivot from one spanning tree solution to another: just send flow along a cycle! The chosen edge $$$e$$$ is entering the basis, while the edge $$$e_{out}$$$ which became saturated is exiting the basis. Naturally, to solve our problem, we want such a pivot to make progress and reduce the cost of the circulation, so the cycle should have negative cost. Notice that such a pivot can optimistically be performed in $$$O(V)$$$ time, as that is the number of nodes and edges affected. A straightforward application of the (standard) simplex algorithm to the linear program would take $$$O(VE)$$$ for each pivot, and do essentially the same thing.
By the analysis above, this is completely equivalent to a generic simplex algorithm. All we have to do now is map these concepts back into graph concepts, and solve the problem with some simple handcrafted graph algorithms in $$$O(V)$$$ time per pivot (or better).
Noted, it is possible to arrive at this conclusion by a more direct inspection of the actions of a simplex pivot. I think approaching the problem this way grants more motivation for the decisions made in the next section.
The Network simplex algorithm
To sum up, this is what we want to do, given our graph $$$G(V,E)$$$ setup.
- We want to find an initial feasible circulation, employing some sort of construction involving $$$V$$$ artificial variables with infinite cost, since that is what we did in the linear program.
- We want to find negative cycles quickly, cycles with a "base edge" outside of the current spanning tree $$$T$$$. These base edges are candidates for entering the basis, and are either empty or fully saturated.
- We want to maintain a spanning tree $$$T$$$ of edges efficiently: given an entering edge $$$e$$$, we must identify its cycle $$$C$$$ along $$$T$$$, find the maximum saturating flow $$$f$$$ that can be pushed along $$$C$$$, identify the exiting edge $$$t$$$, update $$$T$$$'s structure, and recompute potentials quickly.
Finally, just like in the simplex algorithm, we will generally have multiple candidate edges to pivot on, so we want a decent pivoting strategy, i.e. some clever way to select good edges quickly. We will also need to take care not to cycle between spanning tree solutions.
You could call the above the "generic network simplex" algorithm. To some extent, the following sections describe my own implementation.
We target a complexity of $$$O(V)$$$ per pivot in the worst-case, and for pivot selection we will perform a block search as described in the LEMON paper, with desired runtime of $$$O(\sqrt E)$$$ (can be tuned), but worst-case runtime of $$$O(E)$$$.
Initial feasible solution
Remember the artificial tableau we built? We created $$$V$$$ artificial variables for each of the supply constraints, and gave each of them a cost of $$$\infty$$$. What do the LP variables correspond to in our graph?
- The normal variables are the (flow of) $$$G$$$'s edges.
- The slack variables are the backward edges in the residual graph of $$$G$$$. We will not represent them explicitly.
- The artificial variables... huh? Well, we need to find an initial feasible solution, and these are nowhere to be found just yet, so we must add new edges for them!
Let's create a special root node $$$R$$$, and add an artificial edge between $$$R$$$ and every other vertex $$$u$$$. These are the incarnations of $$$a_u$$$.
- If $$$u$$$ is a supply node ($$$\text{supply}[u]>0$$$), then the edge is oriented from $$$u$$$ to $$$R$$$, has capacity $$$\text{supply}[u]$$$, and $$$\infty$$$ cost.
- If $$$u$$$ is a demand node ($$$\text{supply}[u]<0$$$), then the edge is oriented from $$$R$$$ to $$$u$$$, has capacity $$$-\text{supply}[u]$$$, and also $$$\infty$$$ cost.
- If $$$u$$$ is a transshipment node ($$$\text{supply}[u]=0$$$) then it doesn't matter which way the edge goes, but we want one for convenience; let's treat these as supply nodes.
All these edges are initially saturated, i.e. $$$\text{flow}[a]=\text{cap}[a]$$$ for every artificial edge $$$a$$$. Take a moment to verify this is indeed a feasible circulation on the new graph (with $$$\infty$$$ cost).
Reduced costs and finding negative cycles
Suppose we have a non-spanning tree edge $$$e\not\in T$$$. If we add it to $$$T$$$ it creates a cycle. We need a way to determine, efficiently, whether this cycle has negative cost and would improve our circulation.
The usual trick is computing a potential function $$$pi[u]$$$ for every node $$$u$$$ s.t. for every edge $$$t=(u,v)\in T$$$, the reduced cost $$$\text{reduced}[t]=\text{cost}[t]+\text{pi}[u]-\text{pi}[v]$$$ is $$$0$$$ (and the same is true of the backward edge, since it has symmetric cost).
Suppose we have this potential function and $$$e=(u_{in},v_{in})$$$. We can trace out the path $$$v_{in}=u_0,u_1,\dots,u_k=u_{in}$$$ along the spanning tree (some of these are forward and some are backward edges). The cost of the cycle $$$C$$$ in the direction of $$$e$$$ is then computed as (by a telescoping sum):
This means we want forward candidate edges $$$e\in L$$$ with negative reduced cost, and backward candidate edges $$$e\in U$$$ with positive reduced cost.
How do we compute $$$\text{pi}$$$? Well, we rooted the spanning tree on the node $$$R$$$. If we set $$$\text{pi}[R]=0$$$, then $$$\text{pi}[u]$$$ is simply the distance from $$$R$$$ to $$$u$$$ along $$$T$$$, and is well defined as there is exactly one such path. Remember that the cost of traversing an edge $$$e$$$ backwards is $$$-\text{cost}[e]$$$.
Technically this path includes an artificial edge with $$$\infty$$$ cost. How do we address this?
We can pick for our "$$$\infty$$$" the sum of absolute costs of all the normal edges, plus 1; this will guarantee that the artificial edges have higher cost than any cycle not including an artificial edge.
The lca node and the cut side
Suppose we're inserting edge $$$e=(u_{in},v_{in})$$$ into the spanning tree $$$T$$$, and we're going to remove some (yet unknown) edge $$$e_{out}$$$ which became saturated along the direction of the push.
The spanning tree is rooted at $$$R$$$, so we can talk about the lca of nodes $$$u_{in}$$$ and $$$v_{in}$$$, we'll call it simply $$$lca$$$. Now we can talk about the side of $$$e_{out}$$$ in the spanning tree: either $$$e_{out}$$$ is found walking up from $$$u_{in}$$$ to $$$lca$$$, or it is found walking up from $$$v_{in}$$$ to $$$lca$$$ (and not both). The cycle $$$C$$$ is made up of the path from $$$v_{in}$$$ to $$$lca$$$ and from $$$lca$$$ to $$$u_{in}$$$. These cases are symmetric for the most part; assume $$$e_{out}$$$ is found walking from $$$u_{in}$$$.
To build the new spanning tree, the path from $$$u_{in}$$$ to $$$e_{out}$$$'s deeper node will be everted, i.e. "flipped on its head"; the tree must be transformed in such a way that all the nodes below $$$e_{out}$$$ and $$$u$$$ will become part of a subtree rooted at $$$u_{in}$$$, and $$$u_{in}$$$'s parent will become $$$v_{in}$$$.
After this transformation, the distance of $$$R$$$ to the nodes in the subtree of $$$u_{in}$$$ changed. Some back of the envelope calculations will show it changed by the same value $$$\pm\ \text{reduced}[e]$$$ for every node, with the sign depending on the orientation of the push along $$$C$$$ and whether we picked $$$u_{in}$$$ or $$$v_{in}$$$.
How do we actually find $$$lca$$$? There are many ways: we can use the wraparound two pointers technique; we can maintain depths for every node (and update them along with the potentials); and we can even use dynamic binary lifting! For simplicity I suggest the first option, as it requires no extra data structures.
Maintaining the spanning tree $$$T$$$
How do we actually evert the tree and visit all the nodes in the subtree of $$$u_{in}$$$ quickly afterwards (that is, in true $$$O(V)$$$ time)? In the following I will explain an implementation based on linked lists, rather than threads which is what is suggested in most references.
We will maintain the parent vertex $$$\text{parent}[u]$$$ of every node $$$u$$$, and also the parent edge $$$\text{pred}[u]$$$ for every node $$$u$$$ (the edge that goes from $$$u$$$ to $$$\text{parent}[u]$$$ or vice-versa and is in $$$T$$$). The latter makes the former somewhat redundant, but whatever!
This way we can go up the tree easily, find $$$lca$$$ and visit all the edges in the cycle. In particular, we can find $$$e_{out}$$$.
How about going down? We will maintain $$$V+1$$$ doubly linked lists with elements in the universe $$$[0,...,V)+{R}$$$ (the vertices). Each vertex $$$u$$$ has a matching list containing all of its children. This can be implemented with two vectors next and prev of size $$$2(V+1)$$$.
To go down the tree and fix the potential function, we simply iterate over the vertices in the doubly linked list of $$$u_{in}$$$, and iterate those again recursively. We can do it with bfs or dfs, it does not matter.
To evert the path $$$u_{in}\dots t$$$ we must fix the $$$\text{parent}$$$, $$$\text{pred}$$$, and children lists of all the nodes on the path. This can be performed in linear time by recording the path from $$$u_{in}$$$ to $$$u_{out}$$$ and fixing the pointers downwards.
How to prevent cycling — choosing exiting arc
When we try to pivot on an edge $$$e$$$ and end up pushing no flow through $$$C$$$ because another edge $$$t\in C$$$ on it was already saturated (remember this is allowed), we do not change the circulation cost or flow. If in the next iterations we once again do not improve our solution, and end up picking $$$e$$$ again, then we start cycling, and we have an infinite loop. There may also be several such $$$t$$$ that get saturated, how do we pick one?
We prevent cycling the same way we prevent it in the simplex algorithm: these situations are basically "ties", and we break the ties in some lexicographic way. Notice that in the situation above, we can exchange $$$e$$$ for $$$t$$$ in $$$T$$$ — looks like doing a bunch of work for a lot of nothing, but we make progress in some well-defined way.
One simple method that I believe should work fine would be to prefer picking $$$e_{out_1}$$$ over $$$e_{out_2}$$$ if $$$e_{out_1}<e_{out_2}$$$ (in our edges' numering system). This is equivalent to Bland's tie breaking rule for tableau rows.
LEMON had a another idea: suppose the entering edge $$$e$$$ goes from $$$u$$$ to $$$v$$$. Imagine the cycle $$$C$$$ starting at $$$lca$$$, going down to $$$u$$$ through $$$e$$$ and up from $$$v$$$ back to $$$lca$$$. Then, from all candidate exiting edges, we pick the one that appears last in this order (we could also pick the first). I suppose they have proven this will not cycle. In practice this amounts to exchanging an $$$>$$$ for a $$$\geq$$$, which is quite more elegant.
Pivoting strategy — choosing entering arc
The simplex algorithm would run through all the columns and pick the one with the lowest negative reduced cost, and terminate if none is found. This corresponds to a pivoting strategy that just checks the reduced cost of every edge. This takes $$$O(V+E)$$$ time, which is just fine for the simplex algorithm, but a bit sub-optimal if we plan to pivot in $$$O(V)$$$ time. This is the best-candidate strategy: we check every edge and pick the best one.
Another option would be to simply pivot on the first edge found, called the first-candidate strategy. This strategy is obviously the fastest, but might pick entering edges that don't reduce the circulation cost by a lot, requiring more pivots overall.
I followed the LEMON implementation here: use a middle ground between the two. Pick some block size $$$B$$$, and run the best-candidate strategy among $$$B$$$ consecutive edges in a wraparound fashion. If after $$$B$$$ edges it finds no candidate it just tries again, and again, until it has actually exhausted all edges. They suggest $$$B=\sqrt E$$$, but $$$B=V$$$ should work fine as well.
I have not personally benchmarked any of these search strategies against each other.
And that's it! We are done once there are no candidate entering edges.
Implementation
Some final points about the implementation:
- We can easily add support for
lowerandupperbounds for the flow along an edge $$$e$$$, by adjusting the supplies of the nodes by the value oflower, usingupper-loweras the capacity of $$$e$$$ throughout the algorithm, and at the ending undoing the adjustment. - If at the end of the algorithm some artificial edges still have flow on them, the problem is infeasible. More specifically, if the edges leading out of $$$R$$$ initially had $$$S$$$ total flow and at the end of the algorithm they have $$$0\leq F\leq S$$$ total flow, then $$$S-F$$$ is essentially the "maximum flow" through the circulation network.
Problems and applications
As discussed in the first section, this is an alternative to the MCF algorithm in same scenarios. So the problems are mostly minimum cost flow problems. As long as the problem does not involve the explicit consideration of augmenting paths or a bound on the total flow/circulation cost, it should be solvable with NS.
- Transportation/Transshipment problems
- Minimum cost bipartite matching
- SPOJ Greedy Island
- SPOJ K-Path Cover
~ I'll add more problems here as I find them.







Thanks man, I wanted to read about it from long time.
Thank you for the very nice explaination! I have two questions, mostly out of curiosity. It might be that I didn’t understand the procedure too well, so bear with me.
If you’re seeking $$$O(V + E)$$$ complexity per pivot change, why bother using linked lists and computing LCAs instead of just re-computing everything from scratch each time? Is the depth of the tree ‘expected’ to be small in general
Isn’t the spanning tree suitable to be kept as a link-cut tree, for theoretically better pivoting complexity? Why isn’t that used instead? Does the $$$O(E)$$$ check for each edge become the bottleneck in that case?
You are correct that we can pivot in $$$O(\log V)$$$ time using a link cut tree that can support rerooting and lazy propagation, for both updating the potential function and finding the bottleneck in the cycle. Most flow algos like preflow-push and MCF can use LCT as well, but there's always the horrible constant factor problem.
NS has even more issues: in the pivot selection function we need to compute the reduced cost of some edge $$$e=(u,v)$$$, and if $$$\text{pi}[u]$$$ has been (lazily) updated then we need to perform an LCT query in $$$O(\log V)$$$. This does not make it necessarily worse theoretically. I know we can do the following three things:
This should be able to guarantee $$$O(\log V)$$$ average time per pivot, but our candidates will be a bit worse so we'll pivot more times.
Finally, the LCT sounds very difficult to implement: we need to maintain both node aggregates with subtree lazy propagation (potentials) and edge aggregates with path lazy propagation (minimum flow and residual capacity).
"If by recomputing everything from scratch you mean forgetting $$$T$$$ then walking down the root to rebuild $$$T$$$, this sounds like it would take $$$O(E)$$$ time, which is worse than our target $$$O(V)$$$?" — I'm not sure why that's true, it seems to be $$$O(V)$$$ quite naturally; do you mind checking my implementation in the comment below and giving some feedback?
Following up my last comment, it seems that it's okay (and also not that slow) to rebuild the tree each iteration. I've managed to write an alternative implementation. It was surprisingly pretty straightforward to implement and not that long (one can definitely implement it from scratch). Will definitely add it to our notebook :).
Here it is: link
Some mentions:
I checked it on a regular MCF problem on some Romanian online judge and it passed all tests. I don't trusts the tests very well, so I'll check it on other problems, too.
Let me know if you find any bugs or immediate improvements.
So you maintain the tree edges in both directions, meaning an evert procedure becomes unnecessary (basically insert 2 edges and remove 2 edges). That is a nice simplification. The pivots become $$$\Theta(V)$$$, which is just fine when $$$B=3V$$$.
There is an issue in the selection strategy: it does not wraparound nor pick a random first edge, it always starts from $$$i=0$$$ and has $$$B=3V$$$. This will cause the number of pivots to degenerate to exponential time in some random graphs. Visualize this as follows: the selection strategy will become very concerned/devoted with finding an optimal "local" circulation for the set of edges $$$[0...B)$$$ while ignoring the remaining ones. Then the strategy proceeds to visit edges in $$$[B...2B)$$$, performs a pivot, breaks the previous optimal "local" circulation for $$$[0...B)$$$, and goes right back to optimizing it, presumably taking a small constant number $$$O(K)$$$ of pivots. Then for $$$[2B...3B)$$$ it has to fix 2 previous "local" circulations, taking $$$O(K^2)$$$ pivots, and so on. We can induct this step and argue the number of pivots will be something like $$$O(M + K^{M/B})$$$ for some constant $$$K$$$, problematic for dense graphs.
Benchmarking my implementation with this selection strategy caused a slowdown from $$$40ms$$$/$$$15000$$$ pivots to $$$1.2s$$$/$$$350000$$$ pivots on random Erdos graphs with $$$V=300,E=6000\sim 8000$$$ (and naturally no difference for $$$E\sim 900\sim 3V$$$).
Everything else looks fine :)
Thanks for the useful insight about the selection strategy! I would have probably missed that. I will change the implementation of the selection strategy to a round-robin style.
Do you happen to have the code for your benchmarks? I would love to experiment with it as well and try to gather more intuition.
EDIT: Updated the implementation to change the strategy.
Here is a simple stub for testing.
You can also submit on yosupo or atcoder practice library: they have mincost flow practice problems, albeit with small graphs.
go sleep bro