


We will hold AtCoder Beginner Contest 221.
- Contest URL: https://atcoder.jp/contests/abc221
- Start Time: http://www.timeanddate.com/worldclock/fixedtime.html?iso=20211002T2100&p1=248
- Duration: 100 minutes
- Number of Tasks: 8
- Writer: chokudai, E869120, Kodaman, leaf1415, math957963, Nyaan, penguinman
- Rated range: ~ 1999
The point values will be 100-200-300-400-500-500-600-600.
We are looking forward to your participation!






Honestly, I have been giving ABC for about 18 months now and I still dont understand what is the target audience for these contest. As usual we have 800 level problems on A-E and then F-H are literally 3500 rated problems.
There is no place for people like me who are on 1800-1900 level, cuz a certain problemset prefix is way too ez and then the problems are directly 3500 level
P.S. I think F is very interesting problem (but very hard ;-;) . How do to do F ?
We can consider two cases: one where the diameter is odd, and the other where it is even.
The first case is simpler, as every subset can have only two nodes — one at an odd distance from the center, the other at even. So you just have to find the number of pairs at distance $$$D$$$, which is standard.
To solve the second case, notice that when the diameter is even — there is only one center. So root the tree at this center, and corresponding to each of its children, find the number of nodes in their subtrees at distance $$$D/2$$$, let it be $$$f[child]$$$. Then the product of ($$$f[child] + 1$$$) over all children gives you the number of valid subsets. Now just subtract the number of subsets with at most $$$1$$$ nodes, and you're done.
Can you please explain why we are multiplying f[child] + 1 in even case
For every child $$$c$$$, you have $$$f[c]$$$ choices to select a node from the subtree corresponding to that child, and one more choice to not select any node at all. Hence, a total of $$$f[c] + 1$$$ choices.
Ok,I got it but why are we multiplaying? When we multiply which situations are we counting
Because each subtree is independent, and for each, you have a number of choices. It's similar to how you would count the number of subsets of a set, where for each element you have $$$2$$$ choices (one to choose it, one to leave it), and you multiply these over all elements. Here you just have $$$(f[c] + 1)$$$ choices instead of $$$2$$$ for each child $$$c$$$. In general, we multiply when we're counting the number of ways to do a task which can be partitioned into smaller subtasks independent of each other — we can instead count the number of ways to do those subtasks, and take their product.
Can you show how to find number of pairs at a distance D? I'm assuming using 2D DP.
There are a number of ways to do that in general (one involves centroid decomposition, which is what I did — and don't really recommend if you don't have it pre-written). You can do it using a $$$2D$$$ — $$$DP$$$ but it would be $$$O(N * D)$$$, so won't pass here. If you're not lazy, you could work up a simpler solution — notice that when $$$D$$$ is odd, there are exactly $$$2$$$ centers (say $$$u$$$ and $$$v$$$) and they are adjacent! Every diameter will have this edge $$$(u, v)$$$ in common. So, just count the number of nodes at a particular distance, say $$$k$$$ at either side of the edge (say $$$dl[k]$$$ for the nodes on the left, and $$$dr[k]$$$ for the nodes on the right). And then for each valid $$$k$$$, add $$$dl[k] \times dr[D - k]$$$ to the answer.
Run a dfs(rooting at center). Find the maximum depth of the nodes in the subtree of each child of the root. Maintain a multiset of these depths.
Suppose the multiset is {.......,d1,d2}.
If d1=d2, you can take nodes(atmost one from subtree of each child of root) at depth d1.
If d1!=d2, you can take only two nodes at a time, one at depth d1 and the other at depth d2.
All diameters of a tree have a common element.
If length is odd then the middle edge is common in all diameters. If length is even then the middle vertex is common in all diameters.
Based on which case it is there are different methods to count while ensuring that all pairs of paths have that common element.
Also to simplify the odd case you can make all edges of length 2 by placing a node in between all edges.
General question: is it correct to say the common element across all odd diameters is the centroid?
Center
I'm asking if this node will also be the centroid — a specific term for something special -- of the tree, or not. Let me know if that is correct, or not please!
That common vertex is called the center of the tree, not the centroid. For more information, you can watch this video Click by Algorithms live, which also has some other interesting properties related to it.
Nope. A common vertex in odd length diameter is by definition centre of the tree. It's not necessary that the centre of the tree is the same as the centorid of the tree.
Model soln of Div1 C/Div2 E was wrong because it used the centre of the tree instead of the centroid of the tree.
I don't have a small counter-example but people in comments here claim to generate a graph in which centre and centroid are different.
Upd: The Center of diameter is 6 and the centroid is 4.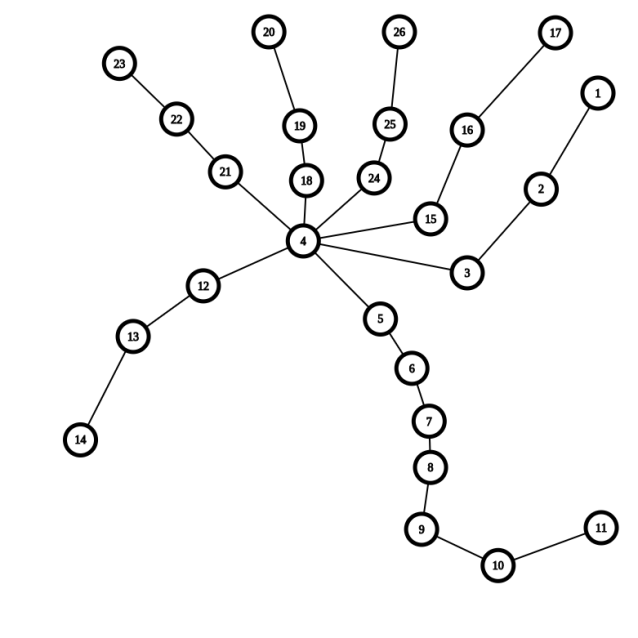
I disagree. In my opinion, E was not very easy; it is just that there are many very similar problems across the internet, so most people would not be solving it for the first time. For an actual "beginner" who has never seen a similar problem before, I would argue it could be quite challenging. Furthermore, F was not substantially harder than E in my opinion it is just that everyone has seen a similar problem to E before, but not necessarily F. I think the difficulty curve was appropriate for a beginner contest.
I think that E-F were roughly similar difficulty as well (I couldn't solve F because of time, but the problem didn't look too out-of-reach).
F-G/H (or even D-E) was a much bigger jump than E-F.
I think the hardest part of problem E was the divide by 2^k trick. EDIT: wrong link
Hi,
Can someone explain why the answer to E's 4th sample test case is 830 and not 574?
I am using a Segment Tree for finding the number of indices that can be included for each index, and am using a combination of Hash-Map and Priority-Queue for ordering the elements.
My Submission
Thanks.
It is because all a1<=ak, for not all k, but only the last k in the subsequence, i.e first should be less than last , you are assuming first is less than all elements in the subsequence. you are considering all k. You misread the question.
:face-palm:
Thanks.
I misread E (completely my fault) as the number of subsequences with the property that $$$A'_1 \leq A'_i$$$, $$$2 \leq i \leq k$$$ which was a similarly interesting problem but had a completely different solution. But the first three test cases had the same answer for this formulation as well, so it took a while for me to notice.
Edit: If you got $$$574$$$ as the answer for the last sample test case, then you did the same thing as me. rip :(
What is the standard problem I should know to solve E? Any links or what can I write on Google? Thanks
It is quite similar to one of the solutions to the LIS problem.
Edit: problem solution
In the solution, what exactly are we storing in the segment/fenwick tree? Is it the number or elements less than equal to Aj?
Maximun LIS such that last element is X.
In problem E .my idea is similar to the editorial but my code got WA. please help anyone. submission link. https://atcoder.jp/contests/abc221/submissions/26319823
Its not even correct on the samples
if you find any wrong here.please tell.i don't found anything
I just want to know can problem D be solved by coordinate compression.
Yes, you can just map the values using a map or store them in a vector and then sort the vector as stated in the official editorial as well.
For the first way stated above you can check my code
shubham84 Can you explain problem D. I didn't understand it that well.
Yeah sure, imagine you are given N segments of the form (l,r) where the l is the start of the segment and r is the length of this segment.
So let us denote this as [l,l+r-1],both inclusive. Now in the question you are asked to calculate the no of days where exactly x segments intersect (here x goes from 1...n).
shubham84 Oh I meant the solution or the approach.
So the solution is pretty simple if you know a prefix sum technique.
Take an array arr of size 1e6 and initialize it with 0. Let's say the segment is [l,r], so in this technique, we update our array-like arr[l]-- and arr[r+1]--, do this step for all the segments and then take prefix sum of this array. Now what you will have in the array arr is the number of intersections at day i.
But as the constraints are pretty high(1e9), we cannot make an array of that size, this is where coordinate compression comes into the picture. So our basic approach remains the same we just add coordinate compression and take the prefix sum through a map.
Hope I could make it clear.
Ps:(Coordinate compression is definitely a pre-requisite here)
You can solve it without coordinate compression as well. Just keep track of the days where a user logs in or logs out. Take a look at the editorial here https://atcoder.jp/contests/abc221/editorial/2733 Mohit.
I came up with an O(n^2) solution for E by iterating over all the pairs, and couldn't come up with an optimized approach for the same.
Any help would be appreciated!!!
maybe this is the easiest abc round after having 8 problems (I think :)qwq
I read the editorial of problem E but I couldn't understand it, can someone explain it in detail?
the answer of a pair ((i,j)|(i<j && ai<=aj)) is (2^{j-i-1})
so you can write this as (2^j/2^{i-1})
so for a j from 1 to n,you can use Binary Indexeds Tree to do this.first you can query the answer,and next you can add the inverse of (2^{j-1}) into the Binary Indexeds Tree.
my english is so bad,hope you can understand it:)
So why the answer of a pair ((i,j)|(i<j && ai<=aj)) is (2^{j-i-1})
that's what I didn't understand
Well just fix two points then i and j (such that a[i]<=a[j]) then what will be the length of the segment between them — it's clearly j-i-1.
Now since we can take subsequences so the choice for each of the numbers between i and j is either they contribute to this segment or they do not, which makes it 2 choices per element between i and j.
So we can conclude it like,
For 1 element no of ways = 2;
For j-i-1 element no of ways = 2^(j-i-1).
Hope this makes it clear!!!
I don't think this is correct. The number of all subsequences between (i, j) -> (i < j) such that A1 = Ai and A(size) = Aj is equal to (2 ^ (j-i-1)).
can you explain how we got this formula?
Because you only care about two elements here being the first and last, you can choose any combination of elements in between.
So for any i, j such that ($$$i < j$$$ && $$$a[i] <= a[j]$$$) there's $$$m = i - j - 1$$$ elements between them, and to complete the subsequence you can choose $$$k = 0,1,...,m$$$ elements, so there's $$$\binom{m}{0}$$$ for subsequences of size 2, $$$\binom{m}{1}$$$ for subsequences of size 3, etc.
So the total count of subsequences for this $$$i$$$ and $$$j$$$ is $$$\sum\limits_{k = 0}^m\binom{m}{k}$$$ and this is always equal to $$$2^{m}$$$.
And here is the proof if you want https://www.askiitians.com/iit-jee-algebra/binomial-theorem-for-a-positive-integral-index/sum-of-binomial-coefficients.aspx
I can never tell whether the explanations are better in Japanese or whether whoever writes the atcoder beginner editorials is trying to dissuade people from doing competitive programming. Even the simplest problems can become confusing if you read the editorials after.
Cool contest with various concept and difficult problems.
The solutions provided in the editorial can be understood if you are experienced with the concepts mentioned there.
I recorded a video during the contest, solving A~D.
I haven't looked at the editorials of the problems that weren't solved/tried yet because I think that you should at least try a problem yourself before solving it.
Also, the announcement was made a little later than usual, so if you don't know, you could go to the contests page to check for upcoming contests.
The method to do with the Problem D is quite simliar with the problem ABC-188-D.
There's a cf problem too which is very similar to it.
Problem
Thanks for the problems -- I couldn't compete live in the contest today, but I worked them afterwards. Problem G forced me to write a bitset class in Golang (which I now have for future problems), so thanks for that. I found most of the problems enjoyable.
My $0.02 is that I do like the extra 2 problems, but the time crunch is certainly more painful than in many other contests. It does feel like 8 problems in 100 minutes is overrewarding faster coders over people who can do the harder problems with a bit more time. I'd personally prefer 2 hours for 8 problems -- I don't know if I'm in the minority or not.
Can anyone explain the solution for task C to me, I didn't get the editorial :(. What I did was separated the numbers with odd/even number of digits. Observed something with odd and similarly with even and then tried to generate the two numbers but got WA on ~50% cases!
Let there be $$$D$$$ digits in the decimal representation of $$$N$$$. Initialize a variable $$$ans$$$ with $$$0$$$. Iterate over all possible $$$D!$$$ permutations, and for each of the permutation, there are at most $$$D - 1$$$ valid methods to split the numbers. Let those numbers be $$$A$$$ and $$$B$$$. Check if they have leading zeroes, if none of them have leading zeroes, update $$$ans = max(ans, A * B)$$$. The time complexity of this approach is $$$O(D * D!)$$$.
Thanks for this method, but what I wanted to ask is that, isn't there a generalized solution to this task, for example picking up alternate monotonically increasing digits or something like that.
Yes, there is a similar solution to that.
On the third solution to C's editorial, it chose all combinations of two integers with monotonically non-increasing digits.
Hi, Here is my screen-cast of the first 6 problems (A — F). I have also discussed my approach towards the end of the video. Click — Click
Well,my friend submitted the code of B problem in the race, which had been accepted eventually. But it is NOT correct.
That's the submission
And the hack:
Input:
abb abc
Output: Yes Expect: No
First of all, thank you for the problems. I found them very interesting and educational.
I have a few comments regarding the editorial for problem H. I'm not sure what is the best way to report them, so I'll leave them here.
I think, because of the 1-based indexing, it should actually be $$$\sum_{i=1}^k B_i\times (k - i + 1) = N$$$.
I think, here it should be $$$\sum_{i=1}^x B_i\times i = y$$$.