


Hello.
Codeforces Round #219 will take place on December 13th at 18:00 MSK for both Div.1 and Div.2 participant. Make sure that it will be held unusual time.
Problem setters are kagamiz and DEGwer, and we thank Gerald for helping us to hold this contest, and Delinur for the translation, and MikeMirzayanov for systems.
The score distribution will be uploaded soon, but probably we use the standard scoring system.
UPD1: The score distribution is standard, 500-1000-1500-2000-2500 for both division.
UPD2: Problem B from Div.2 and problem C from Div.1 have some problems, so all submissions to these problems are rejudged. I'm very sorry.
UPD3: Anyone who gets AC two or more times, because of resubmit before clarification, please, write to Gerald, your submissions that should be skipped. Sorry for inconvenience.
UPD4: Now system test has finished, congratulation for winners!!!
Division 1:
2.tourist
4.dasko1
5.al13n
Division 2:
2.pcnc_zLq
3.wuyiqi
4.prok
And also congrats for rng_58 and permin, who got AC on Div.1 E problem!!
UPD5: Now editorial is uploaded here.






So interesting!
Can you add some information about writers ? I think it will be very interesting to know some about you.
Finally , a Div1 Contest ! Thank you DEGwer :)
downvote me if you can
:D
And me, please.
Now I know what I will do the next time one of my friends forget to logout from their CF account 3:)
It's my account :)
No Friday 13 special contest?
No. The previous one was a Programmer's Day special, Friday the 13th was a coincidental bonus theme. I'm playing with some ideas for the next Surprise Language Round, but this will take more time to prepare. Unless someone else volunteers...
Thanks for making these rounds.
It was Friday 13 special test #13 in problem B (Div. 2) — many contestants failed on this test =(
Problems are Made in Japan!! And anyone knows Products from Japan are of good quality. :)
may be
What is the specific reason of being held unusual time ?
In Japan, usual time is between 0:30 AM and 2:30AM, so we want to hold the contest in earlier time.
as I guess. asked it because of probability of another reason, thanks.
New authors = new personalities! Hope good problems and short statements! GL & HF!
It's a good time for Chinese participants;thx...But some College students will take a test called "CET4/6" tomorrow,so I think the Chinese participants will reduce...For best wishes...
Dynamics of participating CF is continuous for no reason, though tomorrow's CET6.
Glad to see Japanese writers! Recently, I've read a post about Japan (in Russian). Can you approve (or comment) some facts about Japan:
1st, 3rd, 8th, and 10th are just truth. 9th one depends on individuals, but Japanese tend to become drunk very quick. 7th one is not so much, but Japan is very safe country, so some Japanese think almost all of the world is dangerous. For 2nd, 4th, 5th, and 6th, I'm not sure. But I think 4th and 6th is not truth.
Thanks !!! Many interesting things are known about Japan ... :)
On Valentine's Day girls do presents, and usually the present is chocolate.
And we have White Day one month later than Valentine's Day. On this day, boys do presents for girls, and it is also chocolate.
As far as 9. goes, I heard that it's a genetic thing — a large number of Asian population is missing some pathway that helps us cope with alcohol. What a pity! (as I'm writing this, there's a bottle of beer next to me :D)
3.: A snowman from 3 balls is too unstable, not to mention harder to make. I can totally understand that one :D
Good luck to everybody!
It's a good opportunity to back Div.1
Oh today is 13th Friday and the problem writer m.kagamiz( kagamiz )'s name is Jayson.
Good oppurtunity to enter Div1
I am getting extra penalty on problem B Div2 because of that mistake ! I submitted two accepted codes. Is there any hope that penalty can be deleted ?
Write a message to jury, via ask a question functionality. That's what I did, and my extra submissions was deleted.
slow judge:((((((((
Counting Submissions on Queue is Not Fun
My crucial submission on C is hung in the queue for more than 8 minutes. What should be my strategy :( Actually what should be the strategy in such situation???
Try hacking or thinking about other problems... or trying to check your submission on C (generate your own testcases and test it yourself, look at the code and think about it again, etc). Or, you can do it like me: just relax :D
Last one seems good :p
No hacks round :( (almost)
i submitted problem B of div-1 at
01:59:48after a long time of being stuck at it! my hands are still shivering a bit after that last-minute panic! i just hope that it gets accepted! :)EDIT: it (5431756) got Accepted , yay! :)
The time limit on C is really close! At least if the intended solution is an O(NM) one... I hope the pretests are as strong as the lack of hacks indicated :D
Theoretically, 4 seconds shouldn't be even close for O(45 millions)...
Hush, I'm trying to get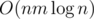 accepted here :)
accepted here :)
There is accepted solution with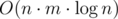 time. 5429539
time. 5429539
And there is my failed solution with O(NM) time. Wat?
Codeforces administrators' position is it's better to allow good written non-optimal solution to pass, than allow bad written(or on Java) optimal solution to fail. There is some logic, but i think it causes more disbalance.
I have O(M2) solution. It just took 15 ms. 5431649
Could you describe it briefly?
We know that Bi terms are really nothing.
Let F(x, t): the minimum sum of |Ai - previous_positions| at time t with position x
If you plot this function in fixed t, you'll see that this function consists of some line segments. You get the idea here.
If there's a new firework event, one must combine |x - Ai| graph into the function.
One have to see what happens if the time passes. The shape of the graph will be expanded d × passed_time unit in both sides with lowest point as its center.
The maximum number of the line segment is O(M) and the operations described above takes O(numberofthelinesegment) each time. The overall time complexity is O(M2)
Can you elaborate a bit more, I am not able to understand this.
Actually, it can even be done in $$$O(M \log M)$$$.
Let's maintain $$$F(x) =$$$ maximum happiness we can attain if we end at location $$$x$$$. After $$$f$$$ fireworks have been launched, $$$F$$$ is a polyline with sections having slopes $$$-f, -f+1, -f+2, \dots, f$$$. We only need to know its constant value and the $$$x$$$-coordinates at which its slope changes in order to uniquely represent it.
We can keep a max-heap storing the slope changes left of the constant section and a min-heap storing the slope changes right of the constant section.
When $$$t$$$ units of time pass, we need $$$F'(x) = min_{x \in [x - tD, x + tD]} F(x)$$$. We need to decrease the coordinates of the slope changes to the left of the constant section by $$$tD$$$ and increase the coordinates of the ones to the right by $$$tD$$$. It can be done lazily by keeping a sum of changes to-be-applied associated with each heap.
When a firework is launched at $$$a$$$, $$$F'(x) = F(x) + abs(x - a)$$$. It can be done by introducing two new slope changes. At most one existing slope change will need to shift from the leaf-heap to the right-heap (or vice-versa). The constant term should also be recalculated.
Implementation: 60323635.
What is that you put in the priority_queue left and right?
I have a feeling that today's system test will take a while...
Problem D div2/ B div1 core idea ?
it can be solved by DP(precalculations) in O(n^5) time .
I was thinking about some preprocessing idea, but I didn't get it? What is it ?
first of all you need to calculate rectangles sums which first coordinate is 1,1; after this you can calculate sum of any rectangles (in O(n^4)):
rectangle_sum(i,j,x,y)=sum[x][y]-sum[i-1][y]-sum[x][j-1]+sum[i-1][j-1];
if rectangle_sum(i,j,x,y)==0 then we can say that this rectangle consist only zero;
using this you can calculate for any (i,j,x,y) number of rectangles which second coordinate(bottom,right) is x,y and consist only zero (in O(n^4)).
and finally using this you can calculate ans for any (i,j,x,y); (in O(n^5),or O(n^4)).
now you can answer queries in O(1) time.
actually, it can be solved in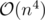 time. i think
time. i think 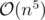 would TLE.
would TLE.
EDIT: by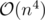 i meant
i meant 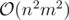 . sorry about any confusion my post caused.
. sorry about any confusion my post caused.
Lyrical got accepted in QNM. Wonder how, my QNM takes 17 seconds :/
Your solution looks elegant and most importantly small. Could you please explain what does
dp[i][j][i+di][j+dj]denote and also provide some intuition behind this "super" recurrence relationfirstly, although the rest of the code looks elegant and small, i want to remind you that i was in a hurry as i submitted this code at
01:59:48, and i apologize that my recurrence relation looks very messy and requires this post for u to understand.now onto my approach. as you can see i answer queries in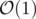 , which means
, which means 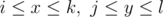 . so from here i will refer to
. so from here i will refer to
dp[i][j][k][l]stores the number of rectangles which contain only0s in the subrectangle(i,j)as the start-point, and(k,l)as the end-point.dianddjdenote the end-point assuming that the start-point is the origin. so if the start-point is(i,j)the end-point would be(i+di,j+dj). the only place to start is a1x1square, i.e.dp[i][j][i][j](wheredianddjare both0), which would be1or0depending ons[i][j]. clearly we should progressively increasedianddjso that we can use the previous information to compute the currently required info. this is why i fixeddianddjand moved the start-point, rather than fixing the start-point and moving the end-point.below i have elaborated on all the terms in the recurrence relation. i hope u are able to understand now. if not, send me a message and i will get back to u.
EDIT: really sorry for this long post, but i hope it served its purpose i.e. everything is clear now! :)
This is one super case of inclusion and exclusion. Had my eyes tight shut for nearly 10 mins to get a feel of all the inclusion and exclusion taking place. Hats off sir! The fact that you imagined this and coded this up during the closing minutes of the contest really demands respect.
Since the editorialist also seems to have used the same logic and unfortunately, has not cared to explain the intuition behind the recurrence relation, a link to your above explanation should be included in the editorial for others to understand :)
EDIT: No corrections. I overlooked the parenthesis. My bad.
haha thanks. i actually had this logic much earlier than the end of contest, but i was always missing few of the terms, so it was giving me WA on first test on my system. when i finally had the above solution, i submitted it as soon as i saw that it was passing first test (due to time shortage). i tested on second test during the
In queuetime. i was literally out of breath just after submitting it!about the correction u posted, what i have written above is correct. there is a
-sign outside the bracket which will negate all terms inside.yes, ur right. i will post a link to the above explanation as a comment on the editorial.
Sorry, I overlooked the parenthesis. My bad. Edited my comment appropriately.
Firstly, you compute prefix sums, so you can check whether a rectangle is good in constant time.
You can do memoization for all possible queries.
When you get a query, you chcek the biggest rectangle (rectangle described by query itself) and recursively compute number of smaller good rectangles from answers for smaller queries (using inclusion and exclusion).
Or just calculate the answers for all possible queries, and answer them in O(1) time :D
Damn 6 and 12!
Thanks a lot. Very liked problems D and E. Wrong answer 5 in E is thinking same circles good, or I have more errors?
Alert at the very end of the contest was not a great idea — 10 seconds left on the clock, I want to send a solution ... when some stupid alert pops up! I panicked a little bit and failed to send it :( Luckily, my solution was buggy anyway, but I think you shouldn't do alerts in the last 5 minutes of the contest (unless it's about extension). It's better to apologize after the contest (if you want to).
Nice round though!
can you estimate the waiting time before judge ? :D
I wonder why the size of array is not big enough will got a "Wrong Answer", instead of "Runtime Error!" ?
Because going out of bounds is an undefined behavior in c++. This means anything can happen. http://stackoverflow.com/questions/1239938/c-accesses-an-array-out-of-bounds-gives-no-error-why
Oh man, Div2 A remind me sooooo badly of jubeat. I live in Kazakhstan though so I can play it only on BEEP. BTW Japanese version have way more songs. sigh If I could just simply play Evans through with tests in the Sample XD
Any ideas for non-quadratic Div 1 D, please?
O(NlogN). Lets move two pointers and calculate minimal number of vertex in tree, which contains all of this.
For doing last part, let's have a set of vertexes sorted in order of in-time in dfs. Then sum of distanses between consecutive vertexes (including last and first) is twiced number of edges in minimal tree.
O(N log^2 N) gets accepted too (binary search on answer, then two pointers with set). TL is really kind.
Awesome!
Thanks! Cool idea to remember.
Counting rectangles was REALLY fun! thanks!
yes it was fun, and the best possible end to it as far as i am concerned, because i made a submission on it at
01:59:48and got it Accepted! :)Sorry, but if my solution got WA before the clarification, and i submit the right one at last, can i skip the solutions before and return the lost points of WA? Looks like a silly question :p
Good round! Thanks!
And also i think 10e16 10e15+1 10e9 is a really interesting test for Problem B in Div2
Yeah, what a pity for my solution. Just one neglect of "long long" type's overflow! It's ok after using "unsigned long long".......
Very Sorry for my hack:( Thought about that... w=w%(k*len)+(w/(k*len)-add)*k*len perhaps this formula is correct:)
Task B,C,D in Div1 are very OI-like. :)
E looks nice: After Inversive transform, it becomes: find sets of pair that share a common middle point (and not parallel). Am I right? Well, I spend 40 minutes to figure out a typo in my code. :(
After Inversive transform, there could be three points exactly on a line, we should minus it from the answer. TAT
Edit : Oops! I haven't read your post clearly. Sorry. But I think it's a quite tricky case.
Yes, I get AC now. Without that trick, I think it is only worth 1500p.
Huge congrats on the win!
friday13 :) ..that why i did not participate
div1 C is (fairly standard dp + find max quickly) so I had the idea of it very quickly.
however,A and B required a little bit cleverness so I think a lot but couldn't find the solution.
I think my skills are declining, thanks to baccalaureate for that :(
For A it is easy to spot that the best answer is n/2 when after sort, all element from first half is placed in the second half. So the solution is just binary search for each element in the first half, for the smallest elements to be fited in the second half.
Hadn't participated in months. It was a good contest to get back in :)
ah my correct solution for problem B got skipped by the judge :(
div2 problem B is tricky, calculation would be exceed long long,I noticed this point in contest,but I don't know how to deal with it.And cause me fail system test,also many participant.Then I use double get AC, sad :(
I used __int64, equals to signed long long. Accepted: 5427927. Sorry for my bad english.
Yeah,I see.You are use division and it wouldn't exceed long long.I also think this means but I havn't use it. Then I use multiplication and cause WA.Your means is a good ways too, I think I should consider more, thank you very much! :)
You really SHOULD NEVER USE stack with visual studio 2010. If you want a proof of it, just have a look at this and this . VS 2010 — TLE9, GNU c++ 0x — AC 1123ms
http://codeforces.com/contest/373/submission/5429866
could somebody explain me why this code at local returns "YES" but online is "NO"? (mac, x-code)
atoi(&str[j])this one considers memory from addres of str[j] to closest zero as C-string and converts it to number. Probably next zero will be the end of string str. So you index dig with something big. Next nobody knows what happen.the test case for which my div2 A http://codeforces.com/contest/373/submission/5421738 gives wa gives the correct output on my machine plz look into in
could someone plz clarify
DELETED. sorry i was wrong.
thanx i dint know this!! does int t[12] = {} ensure that all elements are initialised to 0
i don't think so, but
makes all 12 elements
0. as u may have guessed, it does not depend on the array size.however, before you use
memset, make a note that it only works when u want all values to be set to0or-1, not other integers like1or2.i am not sure what exactly happen if you write "int t[12] = {}" but i submit this code and got accepted.
5433663
never use fflush(stdin). I commented out your fflush(stdin) lines and it gets accepted.
Round statistics, with images.
This is super cool!
I found out what caused me to TLE on C(div1).
Check out 5432941 and 5432965. They only differ in the position of one line: the deque<> is declared once the AC submission, and inside an O(M) cycle in the TLE submission. How come? Shouldn't that just be O(M) additional operations (albeit slow ones)?
When the size of a vector (or deque) exceeds its capacity (the size of the buffer which is currently allocated for it), its size is increased and the data moved. This incurs a time overhead. When the size decreases, its capacity is not decreased (even if you clear() it). Thus, when the size increases again but no more than what it had already been before, there is no overhead. However, if you make a new deque (and, implicitly, delete[] the old memory block), then you will pay again. This means that if you reuse the same deque, you will save on memory management. Sometimes it is faster to have a globally declared vector and clear it every time, rather than a locally defined one.
I've considered that, but it's test 29. The times (T[i]) are really close and D = 3, so the deque will only contain at most around 10 elements at once, and so it won't be resized often. It looks like the deque is being allocated much more space than it needs...
Besides, it passes test cases 8 and 9, where the allocations are much more massive.
I don't know how deque is implemented in cpp, but if there are array resizings, I can see how if you declare the dequeue exactly once, it will never shrink back, and have to reexpand. But if you declared the dequeue multiple times, you would restart with the default initial size and have to reexpand.
See my comment above.
At problem A , this code got Wrong Answer !
but when I changed it to
it got Accepted ! But I can't understand why this is possible ! If anybody knows that , please help me ! :)
Because if you don't increment r then you may take an element more than once!
Output : 250335
Answer : 250336
if I take an element more than once my Output must be more than Answer !!
This is not my wrong , I am sure :)
The output decreases as the number of pair increases, you are taking an element more than once.
Take this example: 3 4 5 10. Your code matches both the 3 and the 4 with the 10.
Ok , I know my solution is wrong !
But my output must be more than Answer ! Ok ?
No.
Youre Output is less than Answer because after you put an kangaroo in another. YOU DO NOT SKIP BOTH OF THEM and it can cause another PAIR , so the Increment of Variable l Because The final result is
n-l-1.The Error Pair cause Decrement in output.
I can hack your first solution with
Answer = 3
Output = 2
I got it ! you are right ! Thank guys :X
As far as I see, if you take an element more than once, as the example given by zylber "3 4 5 10", you say that you can input both 3 & 4 within the 10 .. which means the number of hidden is 2
(l = 3)& the number of visible is 2(n - l + 1).. while in fact the number of visible should be 3. So your output will be less than Answer, not the other way around.It's problem 'A'. If you increment 'l', well, you use a[l] and a[r], else you don't use a[l] and a[r].
Sorry for my bad english.
Problem A (div2).
I got WA on this submission because of test #13. The error is because of line 9:
char row[4];, which should have beenchar row[5];. I know why I need 5 and not 4 (that's because of '\0').On my computer, the test #13 gives the correct answer and I do not receive any errors. Can anyone explain me this weird behaviour and how can I avoid it in the future? Does it have anything to do with the compile and run command?
In C++ accessing out-of-bounds elements of array is undefined behavior because arrays are only positions in memory. Sometimes memory after the array is not used and your code passes, sometimes it is occupied, so you do not get a correct value. You cannot check it during runtime someway.
The general advise is always to create a bit bigger arrays than you need (e.g. 100010, when n <= 100000).
My general advise is to use vector instead of static array :) In that case you will find out of range even in small cases.
Nope, you won't. It also depends on compiler settings. For example, you'll get exception if you use
at()or specify a special debug mode define, butoperator []does not check anything by default.So, if you access items around
size() + 2, you probably won't get an error without debug.I don't like that "general advise". If you create an array the size of which you choose arbitrarily, it means you don't rally understand your solution which is the worst thing you never want to face.
I think that kind of thinking is ineffective. If you set the size of an array +5 of what you are expecting, you don't get a worse situation. In contrast, creating an array of a smaller size that is needed based on an incorrect judgement, you may get punished by WA, while the solution basically is still correct.
It was a very wise comment, it's a shame it got negative feedback.
Indeed, arrays of size 10010 is an ugly code. "Competitive programming" could do better than encouraging bad style.
Vanya, I hope you don't teach this to school kids in LKSh, do you?!
Why not?
This is the only possible approach to guarantee that there's no +/-1 errors in C++ while keeping speed of the program (not using vectors + .at() or dynamic arrays).
As far as I know, you write in Java and there you can create arrays like that:
but in C++ it's not the case.
Nope. The only possible approach to guarantee that there's no +/-1 errors in C++ is to write code that doesn't have +/-1 errors :)
Despite the smile it is not a joke at all.
If you believe that your code needs a +10 in arrays size "just in case", would you trust this code to solve some dangerous real life problems?
The goals in competitive programming and production somewhat differ. In ACM-style contests, the goal is to get Accepted for a problem minimizing the wrong submittion count and the time spent on it. In production, the time and "trial-and-error" constraints are not so strict, the main goal is the correctness and soudness of the code. That's why some hacky tricks are very useful in CP, while not welcome in production. So I think this case is perfectly fine and should be encouraged in CP and discouraged in production.
When will rating updated ? No one ask about this. Am I lack of information such a there's some trouble or cheat issue or unrated ? Thanks
I guess they are busy answering requests for skipping some submissions in Div2-B.
problem B why did it gave TLE for test case to me ? test case 10000000000000000 1 1 code:
long long nod(long long a) { long long b = 0; if(a == 0) return 1; while(a!= 0) { a = a/10; b++; } return b; } int main() { int t; //cin>>t; t = 1; while(t--) { long long w,m,k; cin>>w>>m>>k; long long op = 1; long long length = 0; while(1) { long long temp = (long long)nod(m); long long temp1 = temp * k; long long temp2 = pow(10,temp); long long temp3 = temp2 — m; //cout<<"temp: "<<temp<<" temp1: "<<temp1<<" temp2: "<<temp2<<" temp3: "<<temp3<<endl; //cout<<"w: "<<w<<endl; //cout<<"length: "<<length<<endl; if(temp3 <= (w/temp1)) { length += temp3; w = (w % temp1) + (temp1 * ((w/temp1) — temp3)); m = temp2 ; } else { length += (w/temp1); break; } } cout<<length<<endl; } return 0; }
it is working very fine on my machine ?? any one to help ??
it would be better if u posted a link to ur submission.
5431626 here is the link for submission
It is because of the pow function.
U can precompute the powers of 10 till 10^18 and strore them and access them in O(1)
(I don't know the reason for that much time consumed for the pow function)
i got the error pow(10,2) is being casted as 99 (when i run it in custom testing ) again and again.. but i dont know why it is casted to 99 ?
pow p function uses floating point numbers. Due to rounding errors the result of pow(10,2) is like 99.999999999999 and it is rounded down to 99 during the cast to int.
Best Rating Change!!! (http://codeforces.com/bestRatingChanges/330812)
Can Anyone tell me why 5424683 for 373B - Making Sequences is Fun got WA ?
overflow
w -= (tmp - m) * k * length ;Go to Python.
everywhere replace long long to unsigned long long
I did unsigned long long instead of long long and got accepted.
Tutorial??
In contest I tried an intuitive greedy approach for task A div1 — for a size x of a kangaroo, the kangaroo which will hold it will be that with smallest size y such as y >= 2 * x. If y does not exist, I add 1 to solution. However, it turns out this approach is wrong, but I can't find a counter-example (neither I can prove it, as it's wrong :) ). Can someone tell me what's wrong in my thinking, please?
L.E. Sorry, I've misunderstood the statement of task :| I thought it's possible to be a "chain" of holds, for example 1 -> 2 -> 4. Thanks all for examples! I'll read statements twice by now on, understanding problem wrong is not fun :)
Try;
1 1 2 4
Or
1 2 4 4
Check this case [2,4,5,8], when you try to find the holder for value 2, your solution will find 4 but it's better to assign 5, so you can assign 8 to hold 4. Your solution will answer 3 for this test case, and the answer is 2.
4 1 2 3 4
Your algorithm will put 1 in 2 but you can do better — 1 in 3 and 2 in 4.
It works if you search for y in the second half of the array.
It depends on from where do u start ur search for "y"
Case: 1 2 3 4
u should start searching for "y" from the beginning of the second half of items ... which is "3" in this case because the items in the first half have the chance to go into another bigger item into the second half .. while items in the second half do not.
Any proof about DIV1-A problem??
Let a set of pairs A = {(x, y): x ≥ 2 * y)} be the solution. Let its size be m Then we can transform this set so that x[0] ≥ x[1] ≥ x[2] ≥ ... ≥ x[m] and y[0] ≥ y[1] ≥ y[2] ≥ ... ≥ y[m].
Proof:
Let's sort the pairs in the set by x. Then we pick y[0] and the greatest y of all the pairs. Let the greatest y's index be j. We can change y[0] and y[j]. Then we pick y[1] and change it with the greatest y from the set of pairs with indexes 1..m and etc.
End of the proof.
Let's sort s array from the task so that s[0] ≤ s[1] ≤ .. ≤ s[n]
We can change all x so that x[0] = s[n - 1]..x[m] = s[n - m] and all y so that y[0] = s[m - 1]..y[m] = s[0].
Proof:
It's easy to see that x[i] can't be greater than s[n - i - 1] because s[n - i - 1] is the i-th greatest number in s. So x[i] ≤ s[n - i - 1].
And y[i] can't be less than s[i] because s[i] is the i-th smallest number in s. So s[i] ≤ y[i].
End of the proof.
So all that you need is run a binary search by m and compare s[n - 1] > = 2 * s[m - 1]...s[n - m] > = 2 * s[0].
Have a look http://codeforces.com/contest/373/submission/5433713
I cannot understand why my this code http://codeforces.com/contest/373/submission/5429910 got TLE and this code http://codeforces.com/contest/373/submission/5437285 got accepted. Can anyone please explain me the reason?
The parameter of function
floor,log10andpoware allinttype, you should usefloorl,log10landpowlinstead to avoid overflow problem.'
Thank you very much.I didn't know about floorl,log10l and powl functions.
Problem E is much easier than problem D in div2.
Any idea why my solution for E times out? http://codeforces.com/contest/372/submission/5438314
Thanks!
for (int i = 0; i < M; i++) {... for (int j = 0; j < N; j++) { ... for (int k = left; k <= right; k++) {...} ...}
... }
It seems something about O(M*N2)
Yeah, was that too slow? Do you know what the optimal complexity was?
It is possible to solve this problem with O(NM) complexity by changing your last for() on queue with operation getMax on it.
Ahh! I completely forgot that the cost is the same for all on the inner-most for loop and thus you can just choose the max from the range of possible steps.
Thanks so much!
Can some one give some hint on problem B. Counting Rectangles is Fun (Div 1 — B). I tried Dynamic Programming approach , but could not able to find the recursive relation
Thanks in advance
it's dp along with Inclusion-Exclusion principle, for each rectangle defined by r1, r2, c1, c2, you can get all the rectangles within it by calling recursively for the rectangles at r1+1, r2, c1, c2 && r1, r2-1, c1, c2 and so on, some rectangles will be counted twice, so you need to exclude their answer and so on (This is inclusion-exclusion principle)
You can have a look at this submission 5438353
Problem D div2/ B div1 is similiar to UVa 10502 It may be helpful fpr searching some better solutions
I guess the one here was harder as there were queries, so you had to calculate the answer for every sub-rectangle, the one you posted only asks for the whole grid answer, anyways thanks for sharing this it would really help :) .
Div1.A permits N=5*10^5 at most but I could not attempt such a hack because maximum input for hacks is limited to 256KB in CF. It requires 1MB to describe 5*10^5 numbers and space between them.
Is it permitted that code generated test cases for hacks exceed 256KB?
When is the tutorial coming?
It seems never. Ask for a particular problem.
Just came in 8 minutes ago...
:)
Nice problem and I think the main algorithm of the problem D in Div 1 may appeared at CodeForces early.
Problems C div 1: in each unit time interval we can move x length units which x<=d or x=d? Can anyone help me?
in problem statement:
You can move up to d length units
this means x<=d (up to == at most).
but if the problem statement said "exactly d units" this means x=d
Thank you!
in div1 A whats wrong in logic of pairing largest kangaroo with the largest kangaroo possible
Take the following example:
According to your logic you pair 8 with 4 (8 = largest kangaroo, 4 = largest possible kangaroo that fits 8). Thus you will get 3 visible kangaroos at the end.
The correct answer is 2 (visible kangaroos). You pair 4 with 1 and 8 with 1.
I have posted this exact same comment on the Editorial Blog of this round. Since I did not get any reply, I thought if I post my thoughts here and can find some help :)
Can someone illustrate the idea of Watching Fireworks is Fun more clearly.
I have read DEGwer's editorial and tried to understand his code. But I can't figure out what is this part doing
if i is the order of firework ( i Can be Maximum m) and j is my position on main road ( At most 150000 positions)
As far I understand , if I am at State DP[i][j] I need to find out the maximum value between the interval from DP[ 1-i ][ j-x ] through DP[ 1-i ][ j ] to DP[ 1-i ][ j+x ]
Where x=available time(i.e t[ i ]- t[ i-1 ]) * D i.e DEGwer represents x as interval
But in the code segment I blocked above, DEGwer have started the for loop from 1 to interval.
But shouldn't it iterate through like
please explain what I am thinking wrong. Thanks in advance :)