Hi everyone, today I'm back with another blog that sadly, nor won't have to spend 45 minutes GPT-ing my anime and kaomoji propaganda to read it. ૮₍ ˃ ⤙ ˂ ₎ა 👅
Not sure whether there is another blog explaining this technique in a "so many visualizations" manner.
There are so many paper about these problems in particular. So please put your opinions and any other similar techniques you know in the comment section 📃📃📜. I think this is a "very known technique" for GMs, so you guys might want to skip reading this blog.
I also do expect this is a "very common geometry problem" in China or something but, here is my attempt on explaining it.
Here is a cute quote by me oωo
When it comes to polygon problems, sometimes you have to see 🐦 🎀 𝓈𝑒𝑔𝓂𝑒𝓃𝓉 🎀 🐦 instead of points ✨.
This blog is about polygon counting and Dynamic Programming techniques. Truly, if you think about it there is only 1 method to do this, that is DP. But on how to count it, you got to use some polar sweeping and polar inclusion exclusion. 🔴🔴
Now, I'll talk about 4 problems which more or less uses the same idea.
Triangles
Basically we have to count how many triangles that doesnt have any set of points inside of that triangle. 📐
If you take the consideration of the time limit, you can actually connect some sense that we can brute force and fix for each pair of $$$2$$$ points, and check whether a certain triangle doesn't have any other point inside. ✌️
Okay, now let's do an attempt on that.
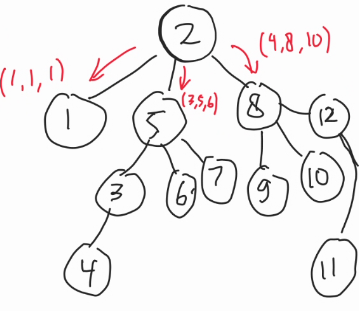
Consider the pair of point $$$A$$$ and $$$B$$$: Your basic intuition must tell you that every point below the vector $$$\vec{AB}$$$ can be ignored.
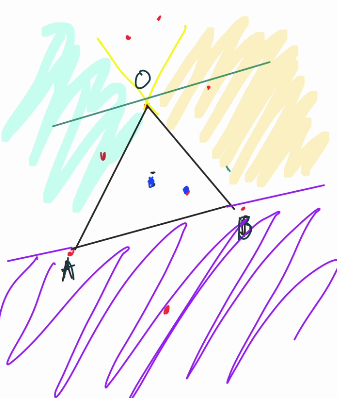
You obtain these kinds of diagram, but you have no idea on how to count the blue points inside the triangle $$$ABO$$$, you can only get the amount of points on the left of $$$AO$$$, and $$$BO$$$ but you cannot separate the blue points 💙 and red ❤️ points above and below $$$O$$$.
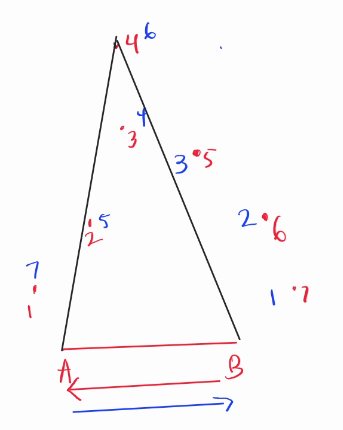
Yes, you can sort the points by order of orientation from $$$\vec{AB}$$$ and $$$\vec{BA}$$$, and you can count how many points $$$(x', y')$$$ is strictly less than $$$(x, y)$$$ for an observed point. But let's assume this method doesn't exist 😠
Okay now, this is where we approach the problem in a quite irregular way.
Without loss of generality, let's assume $$$O$$$ we're looking for are always in between $$$A$$$ and $$$B$$$ in terms of cartesian space. It's true that $$$A.x \leq O.x \leq B.x$$$.
Now here's the nasty part, instead of looking for the points that is on the right for $$$OB$$$ entirely, we limit the points to only the ones that have $$$O.x \leq C.x \leq B.x$$$, and the right of $$$\vec{OB}$$$.
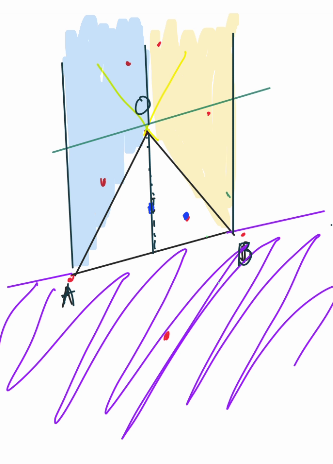
BOOM, now no double counting, the amount of points inside the triangle $$$AOB$$$ is now just $$$\text{count}(A, B) - \text{count}(A, O) - \text{count}(O, B)$$$. This count function, we can precompute! 💥💥🤯🤯🤯
Nice, because we're bruteforcing all 3 points, we know which all 3 points that are involved, so finding the largest one shouldn't be a problem for us. ૮ • ﻌ — ა
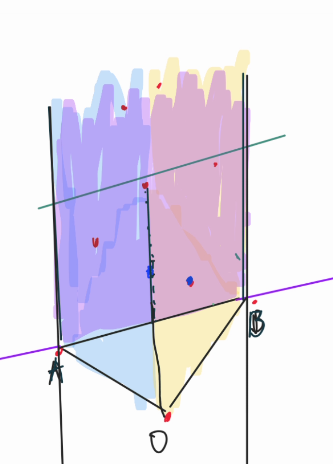
One thing to pay attention to is when $$$O$$$ is in the right of $$$\vec{AB}$$$, than the point count can be negative, if you use the same formula. so if it's a counting problem you might want to take the absolute value instead.
Solution for D. Triangles — 13D
codeLL solve(vector <P> &red, vector <P> &blue) {
sort(all(red)); sort(all(blue));
int n = sz(red), m = sz(blue);
vvi dp(n, vi(n));
rep(i, 0, n) rep(j, i + 1, n) rep(k, 0, m) {
if (!(red[i] < blue[k] && blue[k] < red[j])) continue;
if (red[i].ccw(red[j], blue[k]) > 0) dp[i][j]++;
}
LL ans = 0;
rep(i, 0, n) rep(j, i + 1, n) rep(k, i + 1, j)
ans += (dp[i][k] + dp[k][j] == dp[i][j]);
return ans;
}
Extending it to Convex K Gon
Lol, you're right, we're basically doing inclusion exclusion!
Consider the two points $$$A$$$ $$$B$$$ again, now let's separate those available points on top of $$$A$$$ and on the bottom of $$$B$$$, we're now looking for a sequence of point on top of $$$AB$$$ and bottom of $$$AB$$$, now let's think of building the convex hull in monotone chain manner.
The dumb idea is we do sum kind of subset sum, we want to match the upper hull first. If we know the $$$\text{count}(A, B)$$$ = finalSum, we can iterate the existing state, the state that we store is: dp[x][y][sum], inside we store how many combinations that leads to this, where $$$x$$$ is the second last point of our hull, and $$$y$$$ is the last point of our hull, and sum is the current total sum of points. (*ᴗ͈ˬᴗ͈)ꕤ*.゚
so when we're checking the new point $$$z$$$, make sure that point $$$x, y, z$$$ is a valid hull, $$$p[x].\text{cross}(p[y], p[z]) > 0$$$. Our answer is in dp[x][B][finalSum] for arbitrary x.
Now, to combine, just combine with the bottom hull as well. The time complexity is $$$O(N^6)$$$ lol. Too hard im not even sure whether this is correct, but let's just talk about a better approach later, first, let's look at some other problems, maybe we can find a better approach! (Spoiler: we do) (๑・㉨・๑)
Gadget Construction
Read it first:
G. Gadget Construction — 104619G
😱😱😱😱 Oh, shoot it's a convex hull problem and we need to count!, more over not all edges can be merged, and more over we have to count how many points inside them convex hull, this is basically the previous problem but harder. We're dead. ૮ ˙Ⱉ˙ ა rawr!
Yes, we are.
Constructing the Convex Polygon
First and foremost, let's just ignore the points inside the convex hull, and assume we just want to count how many existing convex hulls are there first.
Okay I'll just give you on how to compute it, let's make a two dynamic programming, one to compute an upper hull and one to compute the lower hull. (◍´ಲ`◍) 🐢
We will create a memoization here, lets define $$$memo[0][a][b]$$$ as the upper hull that starts at $$$a$$$ and ends at $$$b$$$.
Let's define another one here $$$memo[1][a][b]$$$ is the lower hull that starts at $$$a$$$ and ends at $$$b$$$. Here the upper hull has the property where $$$a \leq b$$$ and the lower hull has the property where $$$a \geq b$$$, so in the end our answer is stored at $$$memo[0][a][b] \times memo[1][b][a]$$$ for all pair $$$(1 \leq a \leq b\leq n)$$$.
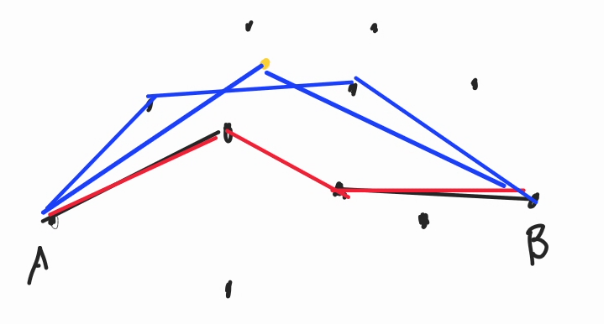
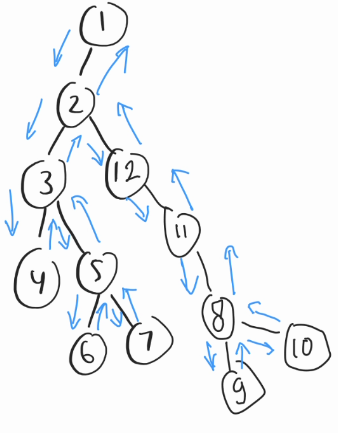
If you see here, a valid upper hull all of them have a valid property in common, that is, for each line, $$$XYZ$$$ in a convex hull, $$$X.\text{cross}(Y, Z) < 0$$$, meaning the line is on the right side of the other. We would like to construct the convex hull from the back, that is $$$B = C[0] \rightarrow C[1] \rightarrow \dots \rightarrow C[K] = A$$$. for $$$K \ge 0$$$. ଘ(੭ˊᵕˋ)੭
Now the transition is the tricky part. Let's say we have two points $$$AB$$$ that is a valid convex hull, how to find all points $$$C$$$ that $$$BC$$$ is a valid convex hull, and $$$ABC$$$ too? 🤔🤔🤔
Let's make the problem simpler, consider $$$memo[0][B][C]$$$ now contains the number of valid convex hull from $$$B$$$ to $$$C$$$, now, if we were to add a single point $$$A$$$. (灬╹ω╹灬)
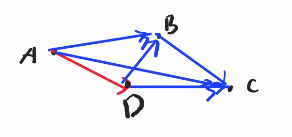
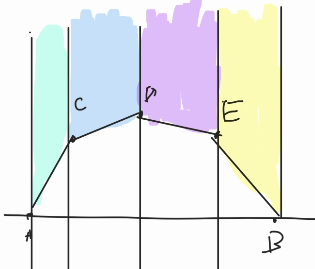
Okay now consider this, what we want is, we count:
- $$$memo[0][B][C] = {[B, C]}$$$
- $$$memo[0][A][B] = {[A, B]}$$$
- $$$memo[0][A][D] = {[A, D]}$$$
- $$$memo[0][D][C] = {[D, C], [D, B, C]}$$$
- $$$memo[0][A][C] = {[A, C], [A, B, C]}$$$
- We don't want to count the $$$[A, D, C]$$$ because it's not a valid convex hull, yet, we still don't want to miss the convex hull $$$[A, D]$$$. ૮ ˙Ⱉ˙ ა rawr!
So, let's sum it up, we will now create lines for every pair of points $$$X, Y$$$, where $$$X.x < Y.x$$$ or ($$$X.x = Y.x$$$ and $$$X.y < Y.y$$$), and lets consider the vertical line we consider are the ones that is going up, so we can just sort the points as usual and only pair up the ones with $$$X < Y$$$.
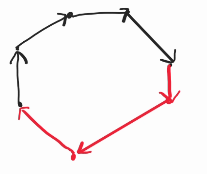
In short, our upper hull (black lines) will only contains the line which have the angle $$$(-\frac{\pi}{2}, \frac{\pi}{2}]$$$. Observe that WLOG, a convex hull containing two vertical lines (assuming no collinear points) will have each part contained in different part of the hull, which we can obtain if we can solve the subproblem of creating the upper hull.
When talking about angle, let's use atan2's terms and quadrants (,,◕ ⋏ ◕,,)

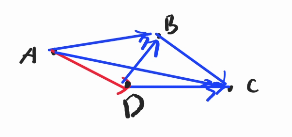
Back to this one, now after we have all the appropriate lines, we would know that when extending a line $$$AB$$$, basically, we would like to know how many valid $$$memo[0][B][C]$$$, and when extending a line $$$AD$$$, we would like to skip $$$memo[0][D][C]$$$. Let's make another case to better sort this out.
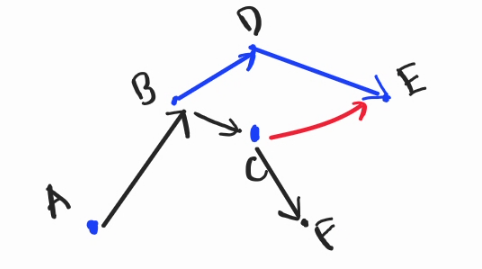
Here, when relaxing $$$AB$$$, I want to count $$$ABC$$$, $$$ABF$$$, $$$ABD$$$, $$$ABDE$$$, $$$\dots$$$ but not $$$ABCE$$$. What differentiate this $$$ABCE$$$ from the other? 🐢
Think about $$$BC$$$ which connects $$$BCE$$$. 🤔🤔🤔
The answer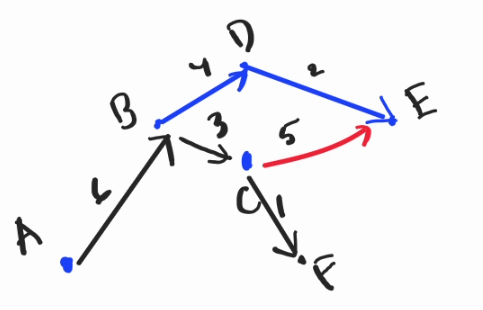
The gradient order.
Here's a cat image before you scroll further and think about how to handle the counting case above.

Now, let's sort out the gradients. Based on the above observation, a convex hull relaxation is valid only if the gradient which comes from the upper hull comes later. So when relaxing the line $$$BC$$$, it can only saw the degenerate convex hull $$$C$$$ and not $$$CE$$$ (which comes later when relaxing the line $$$CE$$$). (・◡ु‹ )
So our relaxation become more or less like:
sort(all(slopes), [&](const Slope & a, const Slope & b) {
return a.fi.cross(b.fi) > 0;
});
// Give the degen convex hull containing only 1 vertex a value
rep(i,0,n) memo[0][i][i] = 1;
trav(slope, slopes) {
int i = slope.se.fi, j = slope.se.se;
for (int k = 0; k < n; k++) {
memo[0][i][k] += (memo[0][i][k] + memo[0][j][k]);
}
}
Boom, now you finished counting all upper hull starting at a point $$$A$$$ and ends at $$$B$$$, which will be stored in $$$memo[0][A][B]$$$. 💥💥🤯🤯🤯
The code basically relaxes the line $$$i$$$, $$$j$$$, and for each of the endpoints $$$k$$$, we will try to append this $$$i,j$$$ line to the existing convex hull $$$j, k$$$, which we store at convex hull $$$i, k$$$.
Basically that's it, now to count the lower hull, just do the same thing, except we swap the slope.
trav(slope, slopes) {
int i = slope.se.fi, j = slope.se.se;
swap(i, j);
for (int k = 0; k < n; k++) {
memo[1][i][k] += (memo[1][i][k] + memo[1][j][k]);
}
}
Now, multiplying all parts $$$memo[0][i][j] \times memo[1][j][i]$$$ will do it. Lastly, don't forget that we have to make sure that we don't double count those convex hull with vertex $$$\le 2$$$. ( つ•̀ω•́)つ
Back to the top one. Now back to gadget construction, we have 2 more subproblems to solve 😭😭
Alternating Cogs
Amazingly, you can simply sort out which lines we can relax!, when pushing the slopes, you can ignore the lines which connects two same color of cogs, if you pay attention, only valid hull are considered in this case.
We can add other requirements depending on what the problem wants.
Even if we see here, the line $$$AE$$$ is not even connected by a line and will be never relaxed, so all convex hull accumulated in our dynamic programming wont take this into account.
But $$$memo[0][A][E]$$$ will still have a value, which consists of $$$[ABE, ADE, ABCDE]$$$ and the lower hull counter part is $$$memo[1][E][A] = [EFA]$$$, if this is empty, no full hull will be counted, just like how $$$BE$$$. Amazing. 😱😱😱😱
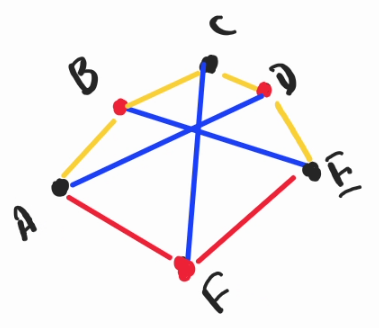
Cogs Triangle Counting
Here comes the last part. We were said that we have to count how many cogs are on each hull, and do a $$$2^c$$$ of when a hull contains $$$c$$$ cogs. Fortunately, this function can easily be attached to our $$$dp$$$. Take the above case and let's count.
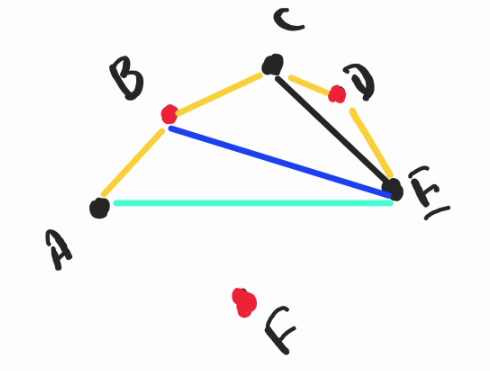
Thanks to our convex polygon triangulation property, each pair of non adjacent point is a diagonal, which means we can separate the total number of cogs inside a polygon by counting each of the triangle appended to it ૮₍˶ •. • ⑅₎ა ♡. so:
- when relaxing $$$CD$$$ to $$$DE$$$'s convex hull, we can multiply $$$2^c$$$ where $$$c$$$ is the number of cogs inside the triangle $$$C[\dots]E$$$.
- when we're relaxing $$$BC$$$, we multiply $$$2^{BCD}$$$ to get the $$$B[\dots]D$$$ one, and $$$2^{BCE}$$$ to get the $$$BC[\dots]E$$$ one.
Why is this true? ୧ ‧₊˚ 🍓 ⋅ ☆
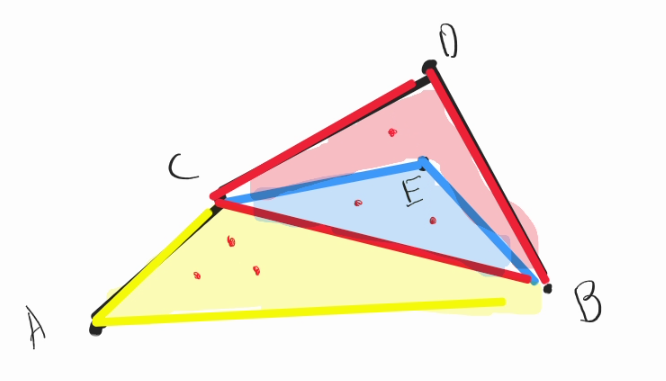
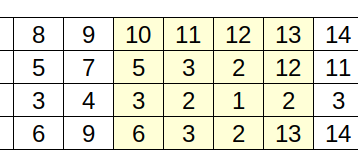
- Let's say has $$$CEB$$$ has $$$2$$$ cogs inside, $$$CDB$$$ has $$$4$$$ cogs inside, the $$$memo[0][C][B]$$$ should be $$$CEB + CDB + CB = 2^2 + 2^4 + 2^0 = 21$$$.
- Now, when relaxing $$$AC$$$, which have $$$3$$$ cogs inside, those values will all multiply by $$$2^3$$$. Thus, $$$memo[0][A][B] = ACDB + ACEB + ACB = 2^3(2^2 + 2^4 + 2^0)$$$.
- Clear.
Now this one subproblem on counting how many points inside the triangle is just the first problem.
create the same exact DP with the first problem, but the blue set is the red set.
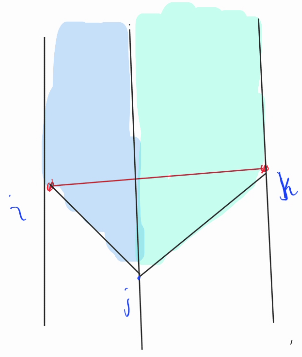
again, to get the number of points in $$$i, j, k$$$, is $$$count(i, j) + count(j, k) - count(i, k)$$$. No three points are collinear mean there is no point between $$$i$$$ and $$$k$$$, so safely be ignored.
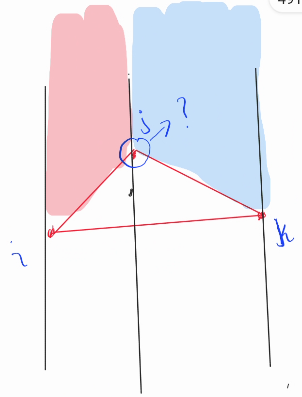
Now this one another case is $$$count(i, k) - count(i, j) - count(j, k) - 1$$$, cause the point $$$j$$$ is counted by $$$count(i, k)$$$. 🐢
Спойлерtypedef Point<LL> P;
typedef pair<P, bool> Gadget;
typedef pair<P, PII> Slope;
typedef array<int, 3> Container;
const int LIM = 500;
LL cntTop[LIM + 5][LIM + 5];
LL memo[2][LIM + 5][LIM + 5];
int cntIn(int i, int j, int k) {
if (j > k) swap(j, k);
if (i > j) swap(i, j);
assert(i <= j && j <= k);
int cnt = cntTop[i][j] + cntTop[j][k] - cntTop[i][k];
return cnt >= 0 ? cnt : -cnt - 1;
}
int main() {
cin.tie(0)->sync_with_stdio(0);
cout.tie(0);
int n; cin >> n;
vector<Gadget> isi(n);
trav(cur, isi) {
cin >> cur.fi.x >> cur.fi.y;
char ch; cin >> ch;
cur.se = ch == 'b';
}
sort(all(isi));
vector<Slope> slopes;
rep(i, 0, n) rep(j, i + 1, n) {
if (isi[i].se != isi[j].se) {
slopes.pb({isi[j].fi - isi[i].fi, {i, j}});
}
}
// Sort ccw
sort(all(slopes), [&](const Slope & a, const Slope & b) {
return a.fi.cross(b.fi) > 0;
});
vector <LL> pow2(LIM + 5, 1);
rep(i, 1, LIM + 1) {
pow2[i] = pow2[i - 1] << 1;
if (pow2[i] >= MOD) pow2[i] -= MOD;
}
rep(i, 0, n) rep(j, i + 1, n) rep(k, i + 1, j) {
if (isi[i].fi.ccw(isi[j].fi, isi[k].fi) > 0)
cntTop[i][j]++;
}
rep(i, 0, n) memo[0][i][i] = memo[1][i][i] = 1;
trav(slope, slopes) {
int i = slope.se.fi, j = slope.se.se;
rep(k, 0, n) {
memo[0][i][k] = (memo[0][i][k] + memo[0][j][k] * pow2[cntIn(i, j, k)]) % MOD;
memo[1][j][k] = (memo[1][j][k] + memo[1][i][k] * pow2[cntIn(i, j, k)]) % MOD;
}
}
LL ans = 0;
rep(i, 0, n) rep(j, 0, n) {
ans += memo[0][i][j] * memo[1][j][i] % MOD;
}
cout << (ans - n - sz(slopes) + MOD) % MOD << endl;
}
Back to Extending it to Convex K Gon
The $$$memo[i][j]$$$ apparently is not enough, we can add another state $$$memo[i][j][k]$$$ where $$$k$$$ is the number of points being used. Now the counting the number of convex $$$K$$$ gon is reduced to $$$O(kN^3)$$$ hooray. To check the maximum area we can check the triangle count and only relax when the triangle count is 0. Even, this dp can be extended to count the convex polygon having exactly $$$M$$$ points inside.
I think there is a known faster solution to this problem. Explained in this recent paper https://www.sciencedirect.com/science/article/pii/S0020019021001368#fg0020. Just read it. I haven't.
Security at Museums
K. Security at Museums — 104160K
We're not done yet, unfortunately. ₊˚ʚ ᗢ₊˚✧ ゚.
We're back at the last one. Security at museums. Please read it.
Okay, let's define $$$isBad(i, j)$$$ is true if those edge cannot see each other. I'll make another blog on how to compute this and its variation, but for now, assume there exist a function that can compute that within $$$O(N^3)$$$. But that's not the main suffering of this problem, which is the polygon counting.
Okay, can we apply the same technique like gadget construction? OK. AC.
EOF.
No.
It has collinear points. We're doomed. It's really hard to handle those cases. Just try for yourself if you don't believe me. 😭😭
Our previous DP can't survive. It has so many weaknesses when it comes to double counting the upper and lower hull. 🦈
We have to add some more observation. 🐢
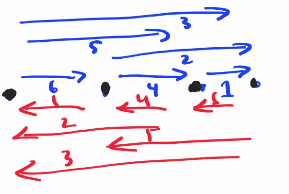
So if the go (represented in blue line) will count those 4 points, the back DP shall be computed in a reversed order. So now, we have to insert our line in a better order, that is to insert it back first, if those points are labeled $$$A$$$, $$$B$$$, $$$C$$$, and $$$D$$$ consecutively, then we will do: CD, BD, AD, BC, AC, AB
or any order that forms a DAG will do. This also ok. I'll use this one.
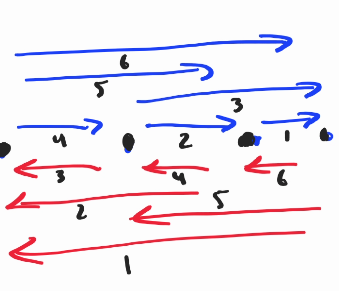
AD, BD, CD, BC, AC, AB
The reversed one is the same but reversed.
for (int i = n - 1; i >= 0; i--) rep(j, i + 1, n) {
if (!isBad[i][j]) {
slopes.pb({isi[j] - isi[i], {i, j}});
}
}
Double Counting Case
Now the above case will be counted so many times, for example when we fix point $$$AD$$$, there is $$$2^2$$$ ways to go, (using $$$B$$$ or $$$C$$$) and $$$2^2$$$ ways to go home too. In total there is a $$$2^4$$$ hull counted, while there only should be $$$2^2$$$ ways.
We can handle that separately. So when processing i, j, we gotta check if there is a point k in between which encompasses this case. (Assume the point array is sorted by x and y) 🦈
for (int i = n - 1; i >= 0; i--) rep(j, i + 1, n) {
if (!isBad[i][j]) {
// remove the double counting cases
int sameGradient = 0;
rep(k, i + 1, j) {
if (isi[k].cross(isi[i], isi[j]) == 0) {
sameGradient++;
}
}
ans = ans - pow2[sameGradient * 2] + pow2[sameGradient];
}
}
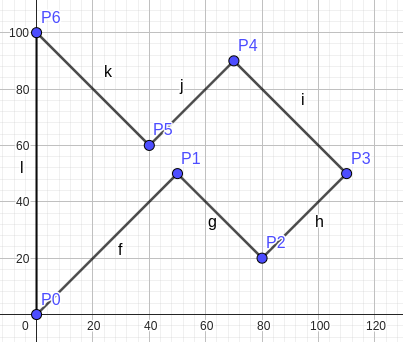
Btw, here's the case where our Gadget Construction's code fail. If we dont handle collinear points. When it tries to compute $$$P5, P3$$$, the $$$P2, P5$$$ ignores the $$$P1$$$. 🐔
There is another implementation variation to solve this problem,
At this point of writing the previous solution, I don't even understand it, but thanks to 244mhq I'm able to understand the logic through his code.
Now instead of sorting all lines, and counting the upper hull and lower hull separately, we will consider one point as a pivot, and count how many convex polygon if we use this point as our left bottom most pivot point.
Instead of separating the process of the hull, just sort the lines, first check if it's a blue go line (its in the first or 4th quadrant), or its a red come line, which is the exact same but reversed.
Then do the dp on DAG casually (pay attention that all blue lines will computed first, then the red come line will come back to the first point)
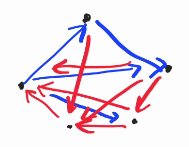
You can notice that basically all the lines is contained in one container slopes , the blue line will be run first, (sorted based on gradient, computing all the upper hull), then when it entered the red lines, it will return all the lower hull. The dp will be more or less like this, very short. 🐔
But the comparison of the slopes shall include some dot product calculation to make sure the DAG computed correctly. That is to check which slope is further in the same direction,
for (int i = 0; i < n; i++) {
// i is the pivot
memset(dp, 0, sizeof dp);
dp[i] = 1;
for (auto& it : slopes) {
// This ignore all slopes that is on the left of the pivot
if (it.first < i || it.second < i) continue;
// This is the red line that comes back to the pivot
if (it.second == i) {
ans = sum(ans, dp[it.first]);
}
else {
dp[it.second] = sum(dp[it.second], dp[it.first]);
}
}
}
Messages
( . .) (. . )
( づ🍫⊂ )
Dear Problem setters, I'm sorry if I spilled a near-contest problem with similar techniques.
And dear contestants, I apologize as this blog will just give problems setters more idea on problem and open up so many more crazy geometry problems in your future ICPCs :p.
I'm planning to blog good geometry techniques I discover in the future also. So brace yourselves.
I also stole the idea by reading some of the judge's sample solution code, turns out it is quite readable (at least for me), and 244mhq which provide a really cool and short implementation for this dp. If you may you can explain the comparator for the slopes for the reader ;), especially the dot product part. 🐟 🐔
Naming
Should we name this kinds of polygon counting technique?
- DP Go and Come
- DP Convex Hull
- Convex Polygon DP
- Don't name it, it's too classic