


Два года назад я вкидывал в сообщество идею о библиотеке, которая умеет генерировать разные клёвые тесты. Я долго крутил идею в голове и наконец попытался что-то написать. Реализовано пока далеко не всё из того, что хочется, но то, что уже есть, я активно использую в своих задачах.
Итак, встречайте: https://github.com/ifsmirnov/jngen. Саму библиотеку (точнее, единственный хедер jngen.h) можно скачать тут.
Jngen умеет работать с массивами, деревьями и графами, а также генерировать немного строк и геометрии. Есть парсер опций командной строки и клёвая SVG-рисовалка. Можно делать, например, так.
cout << Array::id(10).shuffled().add1() << endl; // permutation of elements from 1 to 10
cout << Tree::random(100000, 20) << endl; // "long" tree with elongation 20
pair<string, string> test = rnds.antiHash({{mod1, base1}, {mod2, base2}}, "a-z", 10000); // should be self-describing :)
cout << rndg.convexPolygon(1000, 1e9) << endl;
cout << Graph::random(100000, 200000).connected() << endl;
cout << rndm.randomPrime(1e18, 1e18 - 10000000) << endl;
Практически по всему коду есть документация, есть парочка примеров.
Начать работать очень просто: если от testlib.h вы используете в генераторах только registerGen и rnd.next, то можете заменить #include "testlib.h" на #include "jngen.h" и не заметить разницы. Компилируется чуть дольше, но это обходится, и в итоге получается даже быстрее, чем с testlib.
Буду рад, если потыкаетесь, поделитесь ощущениями и фидбеком. Как говорится, каждый считает свой код и интерфейс идеальным, пока не покажет его публике.
Пока что в библиотеке гораздо больше "базовых" вещей и примитивов, чем "контента" – собственно стандартных тестов к задачам. Мы работаем над этим: в ближайших планах – добавление "наборов тестов", чтобы к своей задаче на, допустим, LCA-like запросы, вы могли сделать разумный тестсет буквально за несколько строк.
Кстати, большое спасибо zemen, Endagorion и Errichto за советы и обсуждения, Endagorion, GlebsHP и CherryTree за возможность потырить код посмотреть на существующие библиотеки и MikeMirzayanov за testlib, из исходников которого на первых порах зачерпнулось немало вдохновения.






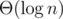 independently of rand() calls.
independently of rand() calls.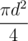 . Далее следует сравнить эту величину с
. Далее следует сравнить эту величину с 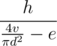 секунд. Иначе вы не сможете её опустошить.
секунд. Иначе вы не сможете её опустошить.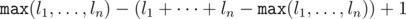 .
.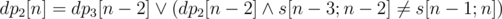 . Аналогично
. Аналогично 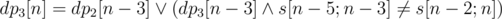 . Если
. Если 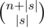 способами. Далее в любом из
способами. Далее в любом из 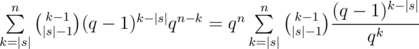 . Таким образом, если у нас фиксировано
. Таким образом, если у нас фиксировано 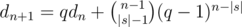 . Действительно, либо последний символ не совпадёт с последней позицией в лекс. мин. вхождении и мы пойдём по первому слагаемому, либо совпадёт, тогда мы сможем явно посчитать число таких надпоследовательностей, которое равно числу во втором слагаемом.
. Действительно, либо последний символ не совпадёт с последней позицией в лекс. мин. вхождении и мы пойдём по первому слагаемому, либо совпадёт, тогда мы сможем явно посчитать число таких надпоследовательностей, которое равно числу во втором слагаемом.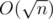 , значит, решая в лоб по этой формуле, мы получим решение за
, значит, решая в лоб по этой формуле, мы получим решение за 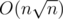 .
.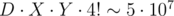 ; однако невозможно построить тест, на котором реализуются всевозможные конфигурации с движением по параллельным прямым, поэтому на самом деле перебирать придётся гораздо меньше.
; однако невозможно построить тест, на котором реализуются всевозможные конфигурации с движением по параллельным прямым, поэтому на самом деле перебирать придётся гораздо меньше.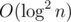 per query time complexity.
per query time complexity.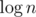 per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in
per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in  , others are
, others are 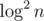 ! Time is averaged over several consecutive runs. Test data is generated randomly with
! Time is averaged over several consecutive runs. Test data is generated randomly with 