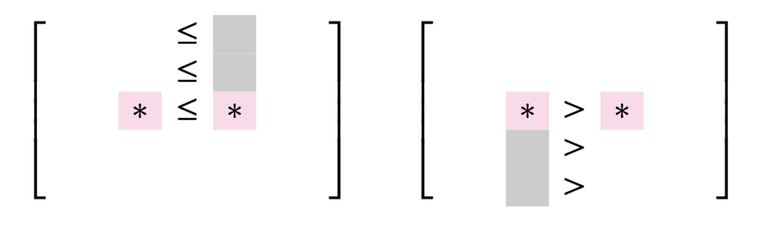The World Finals are right ahead, and if everything works as I expect, you will probably have to wait a lot of time before the contest, dress rehearsals, or anything else. I prepared this blog post so that you have something to keep yourself occupied.
Goal
Our goal is to maintain connectivity in fully-dynamic query streams. In other words, we want to solve this problem:
- Insert an edge $$$e = (u, v)$$$ into a graph
- Delete an edge $$$e = (u, v)$$$ into a graph
- Find if two vertices $$$u, v$$$ are connected
- Find the size of connected components where the vertex $$$u$$$ belongs.
The offline version, where you can cheat (aka, read all queries before answering, and answer everything at the very end of the program) has a very cool solution commonly known as Offline Dynamic Connectivity. This is enough in most CP problems, where this offline solution is rarely considered cheating.
Unfortunately, people in the academia are not chilling and consider this a kind of cheating (not exactly but w/e), so we need to respond to each query right after they are given. This is known as Online Dynamic Connectivity or HDLT Algorithm. I think it is as well-known as the offline algorithm in the sense that people know it exists, but many people just think it's way too hard.
Top trees
The dynamic connectivity problem can be solved if the underlying graph is guaranteed to be a forest. Indeed, in this case, you can do a little bit more than just maintaining the connectivity, you can (and you have to) do the following:
link(u, v): Insert an edge $$$e = (u, v)$$$ into a forest, given that the graph remains a forest.cut(u, v): Delete an edge $$$e = (u, v)$$$ from a forest.find_root(u): Returns a root node of a component of $$$u$$$ — it is basically some random node that is consistently returned among the component (just like thefindoperation in DSU)sum(u): Returns a sum of labels in a component of $$$u$$$ (yes, each vertex is associated with some labels)find_first(u): Returns the first node in a component of $$$u$$$ that satisfies some predicate (per labels).update(v, x): Update the label of $$$v$$$ to $$$x$$$
This is pretty easy if you have a good top tree implementation by ecnerwala and know how to use it. But if you don't, then you have to use a sad BBST that maintains this weird cyclic Euler tree order and oh so confusing. But I'm not writing a top tree tutorial here, so let's not delve into these technicalities.
Insertion is as easy as DSU
We do want to leverage the fact that a spanning forest can be maintained — so let's try to maintain a spanning forest and the set of back edges that currently do not belong to that spanning forest (but can be later if some edges are deleted)
Insertion is as easy as DSU — check if find_root(u) != find_root(v). If it is, add into a spanning forest with link operation. Otherwise throw it into the list of back edges. Easy!
Deletion is hard
Or is it? Suppose the deleted edge are one of the back edges. Then you can just remove them from the set and call it a day.
Suppose not. Then use the cut operation to remove the edge from the forest. After the removal of the edge, the component will be split into two parts. Some back edge may connect these two parts, and in that case, you have to insert them into the spanning forest again.
So you have to find a back edge that connects these two parts. This looks easy, can't you just use some segment trees in Euler tours? Well, the fact that trees are dynamic makes it very hard to solve this problem, especially given that nobody has any idea on how to tackle the problem this way.
And now we found the devil. We have to find the back edges between these two parts quickly.
Won't get fooled again (or, at least, not too much)
Given that it seems hard to directly find the edge between two component, another approach to solve this is by scanning each edge at most once — then, although in each query you may spend a lot of time, the total time spent will be at most the number of (inserted) edges, which looks good.
Let's try this. For each vertex, label them with the number of back edges incident with it. After removing the edge $$$(u, v)$$$, let $$$T_u, T_v$$$ be the component connecting each vertices. We scan each $$$T_u$$$'s back edges (using find_first) . If they connect $$$T_u$$$ and $$$T_v$$$, we are done!
Otherwise, we need to not scan them again, what should we do? Well, just throw them away! And get wrong answer. But we want to throw them away so badly, how should we do?
The kicker here is that we can assume $$$|T_u| \le |T_v|$$$ here. Anyway, the choice of $$$T_u$$$ was pretty random, and we can know the size of the subtree by storing as one of labels in top tree. And that means $$$|T_u| \le \frac{1}{2} (|T_u| + |T_v|)$$$, so we want to kick out those edges into this small area and somehow hope that we won't be kicking out each edges too much. Like, if this area is "really small" like $$$|T_u| = 1$$$, the back edge won't even exist. So we hope to scan each edge at most $$$\log n$$$ time, hopefully.
Here's our strategy. We want to push down each back edges if they ended up not connecting the tree again. Let's do it for only two layers. Suppose that we have some back edges that we don't want to scan. What should we do? If we only push down back edges, it's just a heap of random edges. So we also need to push down the tree as well. Let's push all tree edges of $$$T_u$$$ as well.
Then we have an algorithm. Let's say the upper layer is the main layer we are working, and the lower layer is the smaller layer where we throw stuff away. Here are the two invariants we are maintaining:
- In the lower layer we want the component size to stay below $$$n/2$$$, because that's the point of bounding this scan count.
- The edges in the forest of the lower layer is a subset of the edges in the forest of the upper layer, for consistency.
In the insertion case, just add the edge in the upper layer. Easy.
In the deletion case, let's analyze the cases:
- If it is a back edge delete it (there will be only one layer containing it)
- If it is a tree edge only in the upper layer:
- Now the component is split into two trees — let $$$T_u$$$ be the smaller one. We push all tree edges in $$$T_u$$$, while being careful not to push tree edges that already exists in the lower layer (that blows up the complexity!). Then we scan all the back edges. If we found one, connect it in the upper layer, and send down all failed ones to the lower layer.
- Note that there is no point in searching in the lower layer — By assumption, lower layer doesn't have this tree edge, and hence no back edge covering this at all.
- We are pushing lots of edges from the upper layer to lower layer, and we don't exactly know the underlying forest in the lower layer. Should we be worried about the component exceeding size $$$n/2$$$ ? Not really, you can conclude that there could be no tree edge that connects between $$$T_u$$$ and $$$V - T_u$$$, because of this subset property.
- If it is a tree edge in both layers:
- Let's start from the lower layer and try to find a back edge.
- If a back edge connects $$$T_u$$$ and $$$T_v$$$, connect it in both layers.
- What if it does not? Well, then we need to push it down into another layer, but at this point let's assume this never happens.
So far so good, If nothing in lower layer fails, we already has an algorithm.
The Algorithm
Let's generalize the above algorithm so that we can repeat the same argument even if the edge in the lower layer fails. We have
- Layer $$$0$$$ (prev. upper layer) where we have a spanning forest and some back edges
- Layer $$$1$$$ (prev. lower layer) where we have a forest with each component size at most $$$\frac{n}{2}$$$, and some back edges
- Layer $$$2$$$ where we have a forest with each component size at most $$$\frac{n}{4}$$$, and some back edges
- ...
- Layer $$$i$$$ where we have a forest with each component size at most $$$\frac{n}{2^i}$$$, and some back edges
- ...
- Layer $$$\lfloor \log n \rfloor$$$ where we have a forest with each component size at most $$$1$$$, hence no back edges
As an invariant, each edge set of forest in layer $$$i+1$$$ is a subset of that in layer $$$i$$$.
Insertion is still easy; add an edge in layer $$$0$$$.
In the deletion case, let's analyze the cases:
- If it is a back edge, delete it (there will be only one layer containing it)
- If it is a tree edge in layer $$$0, 1, \ldots, l$$$:
- We should remove them from all top trees in layer $$$\le l$$$.
- Let's start from layer $$$i = l, l-1, \ldots, 0$$$ and try to find a back edge.
- Now the component is split into two trees — let $$$T_u$$$ be the smaller one. We push all tree edges in $$$T_u$$$ to level $$$i+1$$$ while being careful not to push tree edges already in level $$$i+1$$$. Then, we scan all the back edges. If we find one, connect it in all layers $$$0, 1, \ldots, i$$$, and send down all failed ones to level $$$i+1$$$.
Now, every time we touch the edge, we increase their level. This level can't go over $$$\log n$$$, and top tree has $$$O(\log n)$$$ time, so we obtain a $$$O(\log^2 n)$$$ amortized time algorithm. Not easy, but very simple!







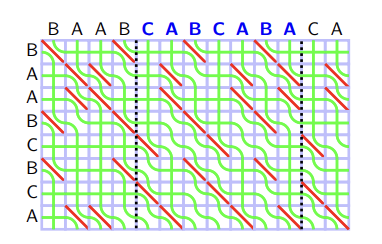
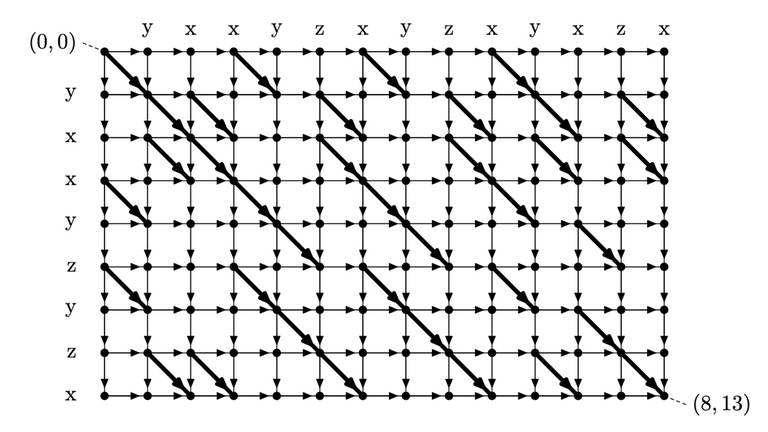
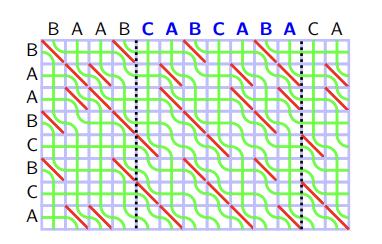
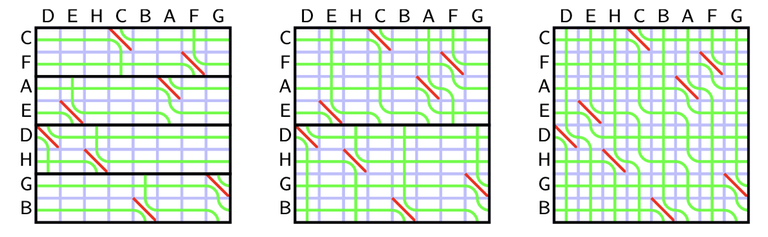 Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.
Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.