


| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3650 |
| 2 | Benq | 3582 |
| 3 | Geothermal | 3570 |
| 3 | orzdevinwang | 3570 |
| 5 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3532 |
| 8 | Radewoosh | 3522 |
| 9 | Um_nik | 3483 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 163 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |






Here's the tutorial. Code can be found in this link (more will be added there soon): https://www.dropbox.com/sh/xwxn3zrl1icp3i2/AACtYSdYH0KlTEdVgCFFgPrYa?dl=0
Hello again Codeforces!
The Forethought Future Cup Final round will start on May 4th, 10:05am PDT. This round will be rated for everyone. There will be three separate rounds, one for onsite contestants, one for div1, and one for div2. Onsite and div1 will have the same problems. Each round will have 6 problems and be 2 hours long.
Here is a table of the onsite contestants.
The onsite round has cash prizes:
- 1st: $500
- 2nd: $250
- 3rd: $100
- 4th — 10th: $50
Thanks to ismagilov.code, mohammedehab2002, Jeel_Vaishnav, Learner99, 300iq, dojiboy9, vlyubin, y0105w49, KAN, arsijo for testing and coordination. Also, thanks to cyand1317 for one of the problems. Of course, thanks to MikeMirzayanov for Codeforces and Polygon, and for allowing us to host the round.
There might be some interactive problems again, so please read the interactive problem guide if you haven't before.
If you're still interested in applying, please fill out the form.
Updates
UPD 1 The scoring distribution will be:
- Div2: 500-1000-1500-2000-2500-3000
- Div1: 500-1000-1500-2000-2500-3250
UPD 2 Pictures from the onsite round: https://codeforces.com/blog/entry/66876
UPD 3: I'm sorry, but to prevent the leak of onsite results, we will postpone the start of system testing a bit. As soon as the closing ceremony finish at Forethought office, we will immediately start the system testing of the rounds. Until this time, the rounds will be hidden. But don't panic, this will only be temporary and we will return everything soon.
UPD 4: The results will be in around 90 minutes after the end of the competition.
UPD 5: Tutorial: https://codeforces.com/blog/entry/66878
UPD 6: Congratulations to the winners:
Onsite contest:
| 1 | scott_wu |
| 2 | ACRush |
| 3 | neal |
| 4 | xiaowuc1 |
| 5 | Svlad_Cjelli |
| 6 | Ra16bit |
| 7 | ll931110 |
| 8 | stevenkplus |
| 9 | yzyz |
| 10 | pmnox |
Div 1 contest:
| 1 | Benq |
| 2 | Petr |
| 3 | Errichto |
| 4 | aid |
| 5 | Endagorion |
Div 2 contest:
| 1 | Ezys |
| 2 | nitishk24 |
| 3 | gonP |
| 4 | trabbbart |
| 5 | EvgeniyZh |
I wrote a post about coming up with problem ideas here with some examples: https://www.topcoder.com/blog/how-to-come-up-with-problem-ideas/
Here's the tutorial. Code can be found in this link: https://www.dropbox.com/sh/wfr12qqhcrdwwlv/AAAgg-7NcqRHIysVjHvmcR_Ta?dl=0
Hi Codeforces!
I'm excited to announce the Forethought Future Cup! It will consist of two rounds, an online round on April 20th, 11:05am PDT, and an onsite round on May 4th, 10:05am PDT. Both of these rounds will be rated and open for all participants. The top 25 local contestants near San Francisco will be invited to the Forethought office to take part onsite.
Each round will be a combined round. In the first round, there will be 8 problems in 2.5 hours. There will be at least one interactive problem in this round. Please read the interactive problem guide if you haven’t already.
The problems in this round were all written by me. Thanks to ismagilov.code, mohammedehab2002, Jeel_Vaishnav, Learner99, dojiboy9, vlyubin, y0105w49, KAN, arsijo for testing and coordination. Of course, thanks to MikeMirzayanov for Codeforces and Polygon, and for allowing us to host the round.
Prizes
T-shirts will be awarded to all onsite participants. 25 shirts will also be randomly awarded to contestants in the elimination round with ranks 1 to 250. The onsite round will also have some monetary prizes:
- First: $500
- Second: $250
- Third: $100
- 4th — 10th: $50
About Forethought:

At Forethought, our mission is to use AI technology to augment human abilities and make everyone “a genius at their job”. Our main product is Agatha, an assistant that helps customer support agents answer cases more quickly and confidently by suggesting answers and triaging cases. We've raised over $10M in VC funding and were the winners of 2018 SF TechCrunch Disrupt Battlefield.
I joined Forethought back in December 2018. We are a small 12 person startup, and have a lot of competitive programmers on our team, including me, y0105w49, vlyubin, and dojiboy9 (our CEO, who is also an ICPC World Finals Judge). I’m happy to answer any questions about working here in the comments below or through PM.
We’re hiring! Please fill out this form if you are interested.
Updates
UPD 1 The scoring distribution will be 500-1000-1500-2250-2500-3250-3250-3750
UPD 2 Tutorial can be found here: https://codeforces.com/blog/entry/66639
UPD 3 Congratulations to the top 5!
NAIPC is happening again on March 2nd (start time). Information about the contest can be found on this page. Information about registering can be found on here. You can register in teams of up to 3. The deadline for registration is February 28th. This contest will be hosted on Kattis again.
A few hours later, it will be available as an open cup round as the Grand Prix of America (start time). Please participate in only one of them, and don't discuss problems here until after the open cup round has ended.
You can see some past years' problems here: 2018, 2017
UPD 1: Registration is ending soon.
UPD 2: Please don't discuss until after open cup is over.
UPD 3: You can find test data and solutions here: http://serjudging.vanb.org/?p=1349
Recently, I wrote about my experiences with problem writing. This was something I haven't really talked about, and I felt it was time to share.
Read here: https://www.topcoder.com/blog/a-problem-writing-journey/
Feel free to leave comments or questions!
I'm not sure I've seen a post about this yet. Topcoder has posted their schedule for online rounds for TCO here: http://tco18.topcoder.com/algorithm/schedule/
It seems the round structure also seems to have changed. The rounds are 1A,1B, 2A,2B, 3A,3B, and a single round 4. Round 4 feeds directly into the onsite, with 14 finalists (and also 2 from a wildcard round, for a total of 16, 4 more from last year).
NAIPC is coming up on March 24th (start time here). More information about the contest can be found on this page. More information on how to register can be found on this page. You can register in teams of up to 3. This contest will be on Kattis.
Several hours later, it will be available as an open cup round as the Grand Prix of America (start time here). Please only participate in one of them, and don't discuss problems here until after the open cup round has ended.
The deadline to register for the contest on Kattis is March 21st. You will need an ICPC account to register (you can see instructions in the link above on how to create one if needed).
You can see some past years' problems here: 2017, 2016
UPD 1: The deadline to register your team is soon.
UPD 2: Contests are over
- NAIPC standings: https://naipc18.kattis.com/standings
- open cup standings: http://opentrains.snarknews.info/~ejudge/res/res10416
- solutions and test data: http://serjudging.vanb.org/?p=1165
 . Initially
. Initially Hello everybody!
On Mar 3, 10:00 Moscow time, Round 1 of Yandex.Algorithm 2018 competition will take place. I wrote the majority of the problems in this contest, with some additional help from GlebsHP.
I would like to thank GlebsHP for all his help with coordinating this round, MikeMirzayanov for polygon, and of course, everyone who took the time to test this round.
See you in the competition soon!
Editorial here: http://codeforces.com/blog/entry/58135
Hi! Topcoder SRM 730 will happen soon.
Time: 7:00am EDT Tuesday, February 20, 2018
Calendar: https://www.topcoder.com/community/events/
I'm the writer of this round. Hope to see you all participate!
Here's the editorial. Hope you have a happy new year!
Code can be found here: https://www.dropbox.com/sh/i9cxj44tvv5pqvn/AACQs7LLNyTZT-Gt_AMf7UQFa?dl=0
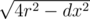 , where
, where 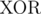 by
by 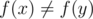 such that
such that 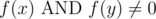 . To show this, let
. To show this, let 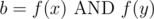 , and without loss of generality, let's assume
, and without loss of generality, let's assume 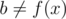 (it can't be simultaneously equal to
(it can't be simultaneously equal to 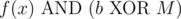 is a smaller element of
is a smaller element of 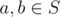 ,
, 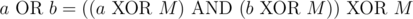 . Since the latter is some composition of XORs and ANDs, it it also in
. Since the latter is some composition of XORs and ANDs, it it also in Hello everyone!
Another year has gone by. The last Codeforces contest of this year will be tomorrow, 29 Dec, 15:35 UTC.
The round details:
- combined div1+div2
- 8 problems
- 2.5 hours
- rated!!!
I'd like to thank the following people for helping with the round: KAN, winger, AlexFetisov, zemen, xiaowuc1, MikeMirzayanov. Without them, this round would not have been possible.
Scoring distribution will be posted later. Make sure to read ahead on the problems, since there may be some later problems that are easier for you. I hope to see you all at the contest, and good luck on the last chance to increase your rating this year!
EDIT1: The scoring distribution is 500-750-1000-1750-1750-2000-2750-3500
EDIT2: There will be a five minute delay for starting.
EDIT3: Editorial is here: http://codeforces.com/blog/entry/56713
EDIT4: Congratulations to the winners!
On Sunday, August 6th, 22:00 IST, we will hold the 2nd elimination for IndiaHacks (some more details here). The top 900 individuals who qualified through previous rounds will have the opportunity to participate in this round. The top 25 global participants and top 25 Indian participants will advance to the final round. The link to the contest is here.
After the official round is over, the next morning, on Monday, August 7th, 11:35 IST, we'll hold an unofficial unrated mirror here on Codeforces. This mirror will have ICPC rules. For participants of the official round, please hold off on discussing the problems publicly until after this mirror is over.
I was the author of the problems in this set, and I hope you will enjoy the problems. I would like to thank zemen for testing the set, Arpa for writing editorials, r3gz3n for his help on the HackerEarth side, KAN for helping us set up the mirror contest, and of course MikeMirzayanov for the great Polygon/Codeforces platform.
The round will consist of 6 problems and you will have 3 hours to complete them. Please note that the problems will be randomly arranged in both rounds, since I couldn't figure out how to sort them by difficulty. Be sure to read all the problems.
UPD1: Updated time of official round and posted link to contest.
UPD2: We should have updated the leaderboard to accept solutions that followed the first version of the first problem. We have also increased the number of finalists to 60 total (30 global + 30 indian) based on this new leaderboard.
UPD3: Here is the list of qualifiers. Congratulations to everyone.
Didn't notice a post from cgy4ever.
Topcoder SRM 718 will happen in ~4 hours.
Hello everyone!
I would like to invite you to participate in Hackerearth June Circuits 2017. It's a long contest that will start on June 16, 2017, 21:00 IST (check your timezone). The contest will run for 9 days.
The problemset consists of 7 traditional algorithmic tasks and 1 approximate problem. For traditional algorithmic tasks, you will receive points for every test case your solution passes — so you can get some points with partial solutions as well. For the approximation task, your score depends on the best solution in the contest so far. Check contest page for more details about in-contest schedule and rules.
I'm the tester of the problemset you'll have to work on — thanks to jtnydv25, saatwik27, harshil, zscoder, Arunnsit for preparing these tasks.
As usual, there will be some prizes for the top five competitors:
- $100 Amazon gift card + HE t-shirt.
- $75 Amazon gift card + HE t-shirt.
- $50 Amazon gift card + HE t-shirt.
- HE t-shirt.
- HE t-shirt.
Good luck to everyone, and I hope to see you at the contest :)
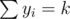 . Thus, this can be computed with a knapsack like formula. After assigning these, we can rearrange groups freely, for a total of k! ways.
. Thus, this can be computed with a knapsack like formula. After assigning these, we can rearrange groups freely, for a total of k! ways.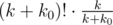 .
.Hello everybody!
On May 27, 23:00 Moscow time, Round 2 of Yandex.Algorithm competition will take place. I wrote the majority of the problems in this contest, with some additional help from Zlobober.
I would like to thank Zlobober for all his help with coordinating this round, MikeMirzayanov for polygon, and of course, everyone who took the time to test this round.
Please note, the problems will be randomly arranged, so make sure you read everything during the round :)
If you are using Java, please submit using Java 7 x32.
See you in the competition soon!
UPD 1: Editorial here: http://codeforces.com/blog/entry/52223
Hello everyone!
I would like to invite you to participate in Hackerearth April Circuits 2017. It's a long contest that will start on April 21, 21:00 IST (check your timezone). Contest will run for 9 days.
The problemset consists of 7 traditional algorithmic tasks and 1 approximate problem. For traditional algorithmic tasks, you will receive points for every test case your solution passes — so you can get some points with partial solutions as well. For the approximation task, your score depends on the best solution in the contest so far. Check contest page for more details about in-contest schedule and rules.
I'm the tester of the problemset you'll have to work on — thanks to jtnydv25, saatwik27, pkacprzak, r3gz3n, trytolearn for preparing these tasks.
As usual, there will be some nice prizes for the top five competitors:
- $100 Amazon gift card + HE t-shirt.
- $75 Amazon gift card + HE t-shirt.
- $50 Amazon gift card + HE t-shirt.
- HE t-shirt.
- HE t-shirt.
Good luck to everyone, and I hope to see you at the contest :)
Hello!
The round 2 of VK Cup 2017 will take place on April 16 at 18:35 MSK (check your timezone here), along with separate div1 and div2 Codeforces Round #409. The contest "VK Cup 2017 — Round 2" is for teams qualified from round 1. The top 100 teams will advance to the Round 3, while other ones will have one more chance in the Wild Card Round 2 later this month. Those who don't participate in the VK Cup can take part in the Codeforces Round #409 individually (problems will be available in English too). All three rounds last 2 hours, and all are rated.
The round would not be possible without the following people (in no particular order): KAN, Errichto, winger, AlexFetisov, LiChenKoh, xiaowuc1, MikeMirzayanov. Additionally, I thank VK company for sponsoring this contest.
As usual, the scoring distribution will be announced later.
UPD 1: The scoring distribution is as follows:
div2: 500 — 1000 — 1500 — 2000 — 2750
div1 and official round: 500 — 1000 — 1750 — 2250 — 2250
UPD 2: The tutorial is available here: http://codeforces.com/blog/entry/51598
Congratulations for the winners
Official round:
- LHiC, V--o_o--V
- I_love_Tanya_Romanova, enot110
- netman, andrew.volchek
- aid, ershov.stanislav
- MrDindows, Rubanenko
div 1:
div 2:
