


Suppose we have downloaded S seconds of the song and press the 'play' button. Let's find how many seconds will be downloaded when we will be forced to play the song once more. 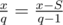 . Hence x = qS.
. Hence x = qS.
Solution: let's multiply S by q while S < T. The answer is the amount of operations.
Complexity — 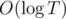
Let's look at the problem from another side: how many numbers can we leave unchanged to get permutation? It is obvious: these numbers must be from 1 to n and they are must be pairwise distinct. This condition is necessary and sufficient.
This problem can be solved with greedy algorithm. If me meet the number we have never met before and this number is between 1 and n, we will leave this number unchanged. To implement this we can use array where we will mark used numbers.
After that we will look over the array again and allocate numbers that weren't used.
Complexity — O(n).
It is known that amount of prime numbers non greater than n is about 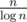 .
.
We can also found the amount of palindrome numbers with fixed length k — it is about 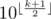 which is
which is  .
.
Therefore the number of primes asymptotically bigger than the number of palindromic numbers and for every constant A there is an answer. Moreover, for this answer n the next condition hold: 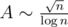 . In our case n < 107.
. In our case n < 107.
For all numbers smaller than 107 we can check if they are primes (via sieve of Eratosthenes) and/or palindromes (via trivial algorithm or compute reverse number via dynamic approach). Then we can calculate prefix sums (π(n) and rub(n)) and find the answer using linear search.
For A ≤ 42 answer is smaller than 2·106.
Complexity — 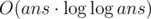 .
.
568B - Symmetric and Transitive
Let's find Johnny's mistake. It is all right in his proof except ``If 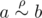 '' part. What if there is no such b for an given a? Then obviously
'' part. What if there is no such b for an given a? Then obviously 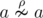 otherwise we'll take b = a.
otherwise we'll take b = a.
We can see that our binary relation is some equivalence relation which was expanded by some "empty" elements. For "empty" element a there is no such b that .
Thus we can divide our solution into two parts:
Count the number of equivalence relations on sets of size 0, 1, ..., n - 1
For every size count the number of ways to expand it with some "empty" elements.
We can define equivalence relation using its equivalence classes.
So first part can be solved using dynamic programming: dp[elems][classes] — the numbers of ways to divide first elems elements to classes equivalence classes. When we handle next element we can send it to one of the existing equivalence classes or we can create new class.
Let's solve second part. Consider set of size m. We have found that there are eq[m] ways to build equivalence relation on this set. We have to add n - m "empty" elements to this set. The number of ways to choose their positions is Cnk. We can calculate all the binomial coefficients using Pascal's triangle.
So the answer to the problem is  .
.
Complexity — O(n2)
Suppose we have fixed letters on some positions, how can we check is there a way to select letters on other positions to build a word from the language? The answer is 2-SAT. Let's see: for every position there is two mutually exclusive options (vowel or consonant) and the rules are consequences. Therefore we can do this check in O(n + m) time.
Let's decrease the length of the prefix which will be the same as in s. Then the next letter must be strictly greater but all the next letters can be any. We can iterate over all greater letters and then check if we can made this word the word from the language (via 2-SAT). Once we have found such possibilty we have found the right prefix of the answer. After that we can increase the length of the fixed prefix in a similar way. This solution works in O(nmΣ ) time. We can divide this by Σ simply try not all the letter but only the smallest possible vowel and the smallest possible consonant.
And you should remember about the case when all the letters are vowel (or all the letters are consonant).
Complexity — O(nm)
Suppose, that solution exist. In case n ≤ k we can put one signpost on each road. In other case let's choose any k + 1 roads. By the Dirichlet's principle there are at least two roads among selected, which have common signpost. Let's simple iterate over all variants with different two roads. After choosing roads a and b, we will remove all roads, intersecting with a and b in common points and reduce k in our problem. This recursive process solves the problem (if solution exist).
Complexity of this solution — 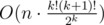 . If implement this solution carefully — you will get AC =)
. If implement this solution carefully — you will get AC =)
But in case of TL we can add one improvement to our solution. Note, that if we find point, which belongs to k + 1 or more roads, then we must include this point to out answer. For sufficiently large n (for example, if n > 30k2) this point always exist and we can find it using randomize algorithm. If solution exist, probability that two arbitrary roads are intersects in such a point not less than 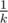 . Because of it, if we 100 times pick two random roads, then with probability
. Because of it, if we 100 times pick two random roads, then with probability 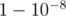 such a point will be found and we can decrease k.
such a point will be found and we can decrease k.
All operations better to do in integers.
Complexity — 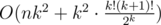 .
.
568E - Longest Increasing Subsequence
Let's calculate array c: c[len] — minimal number that can complete increasing subsequence of length len. (This is one of the common solution for LIS problem).
Elements of this array are increasing and we can add new element v to processed part of sequence as follows:
find such index i that c[i] ≤ v and c[i + 1] ≥ v
let c[i + 1] = v
We can process this action in  time.
time.
When we handle a gap, we must try to insert all numbers from set b. If we sort elements of b in advance, then we can move with two iterators along arrays b and c and relax all needed values as explained above. This case requires O(n + m) time.
Authors implied solution with O(n) space complexity for answer restoring. We can do this in the following way:
Together with array c we will store array cindex[len] — index of element, which complete optimal increasing subsequence of length len. If this subsequence ends in a gap — we will store - 1.
Also, we will store for every not gap — length of LIS(lenLIS[pos]), which ends in this position (this is simply calculating while processing array c) and position(prevIndex[pos]) of previous element in this subsequence (if this elements is gap, we store - 1)
Now we will start recovery the answer with this information.
While we are working with not gaps — it's all right. We can simply restore LIS with prevIndex[pos] array. The main difficulty lies in processing gaps. If value of prevIndex[pos] in current position equal to - 1 — we know, that before this elements must be one or more gaps. And we can determine which gaps and what values from b we must put in them as follows:
Let suppose that we stand at position r (and prevIndex[r] = - 1). Now we want to find such position l (which is not gap), that we can fill exactly lenLIS[r] - lenLIS[l] gaps between l with increasing numbers from interval (a[l]..a[r]). Position l we can simply iterates from r - 1 to 0 and with it calculating gaps between l and r. Check the condition described above we can produce via two binary search query to array b.
Few details:
How do we know, that between positions l and r we can fill gaps in such a way, that out answer still the best?
Let countSkip(l, r) — count gaps on interval (l..r), countBetween(x, y) — count different numbers from set b, lying in the range (x..y).
Then, positions l and r are good only if lenLIS[r] - lenLIS[l] = min(countSkip(l, r), countBetween(a[l], a[r])). countSkip we can calculate while iterates position l, countBetween(x, y) = max(0, lower_bound(b, y) - upper_bound(b, x)).What to do, is LIS ends or begins in gaps?
This case we can solve by simply adding - ∞ and + ∞ in begin and end of out array.
Complexity — 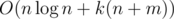 . Memory — O(n + m).
. Memory — O(n + m).


