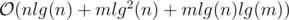Here are the solutions to all problems.
Div.2 A
Just alternatively print "I hate that" and "I love that", and in the last level change "that" to "it".

Time Complexity: 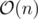
Div.2 B
First of all, instead of cycles, imagine we have bamboos (paths). A valid move in the game is now taking a path and deleting an edge from it (to form two new paths). So, every player in his move can delete an edge in the graph (with components equal to paths). So, no matter how they play, winner is always determined by the parity of number of edges (because it decreases by 1 each time). Second player wins if and only if the number of edges is even. At first it's even (0). In a query that adds a cycle (bamboo) with an odd number of vertices, parity and so winner won't change. When a bamboo with even number of vertices (and so odd number of edges) is added, parity and so the winner will change.

Time Complexity:
A
Consider a queue e for every application and also a queue Q for the notification bar. When an event of the first type happens, increase the number of unread notifications by 1 and push pair (i, x) to Q where i is the index of this event among events of the first type, and also push number i to queue e[x].
When a second type event happens, mark all numbers in queue e[x] and clear this queue (also decreese the number of unread notifications by the number of elements in this queue before clearing).

When a third type query happens, do the following:
while Q is not empty and Q.front().first <= t:
i = Q.front().first
x = Q.front().second
Q.pop()
if mark[i] is false:
mark[i] = true
e[v].pop()
ans = ans - 1 // it always contains the number of unread notifications
But in C++ set works much faster than queue!
Time Complexity: 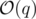
B
Reduction to TSP is easy. We need the shortest Hamiltonian path from s to e. Consider the optimal answer. Its graph is a directed path. Consider the induced graph on first i chairs. In this subgraph, there are some components. Each components forms a directed path. Among these paths, there are 3 types of paths:
- In the future (in chairs in right side of i), we can add vertex to both its beginning and its end.
- In the future (in chairs in right side of i), we can add vertex to its beginning but not its end (because its end is vertex e).
- In the future (in chairs in right side of i), we cannot add vertex to its beginning (because its beginning is vertex s) but we can add to its end.

There are at most 1 paths of types 2 and 3 (note that a path with beginning s and ending e can only exist when all chairs are in the subgraph. i.e. induced subgraph on all vertices).
This gives us a dp approach: dp[i][j][k][l] is the answer for when in induced subgraph on the first i vertices there are j components of type 1, k of type 2 and l of type 3. Please note that it contains some informations more than just the answer. For example we count d[i] or - x[i] when we add i to the dp, not j (in the problem statement, when i < j). Updating it requires considering all four ways of incoming and outgoing edges to the last vertex i (4 ways, because each edge has 2 ways, left or right). You may think its code will be hard, but definitely easier than code of B.
Time Complexity: 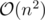
C
Build a graph. Assume a vertex for each clause. For every variable that appears twice in the clauses, add an edge between clauses it appears in (variables that appear once are corner cases). Every vertex in this graph has degree at most two. So, every component is either a cycle or a path. We want to solve the problem for a path component. Every edge either appear the same in its endpoints or appears differently. Denote a dp to count the answer. dp[i][j] is the number of ways to value the edges till i - th vertex in the path so that the last clause(i's) value is j so far (j is either 0 or 1). Using the last edge to update dp[i][j] from dp[i - 1] is really easy in theory.

Counting the answer for a cycle is practically the same, just that we also need another dimension in our dp for the value of the first clause (then we convert it into a path). Handling variables that appear once (edges with one endpoint, this endpoint is always an endpoint of a path component) is also hard coding. And finally we need to merge the answers.
Time Complexity: 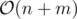
D
Assume r < b (if not, just swap the colors). Build a bipartite graph where every vertical line is a vertex in part X and every horizontal line is a vertex in part Y. Now every point(shield) is an edge (between the corresponding vertical and horizontal lines it lies on). We write 1 on an edge if we want to color it in red and 0 if in blue (there may be more than one edge between two vertices). Each constraint says the difference between 0 and 1 edges connected to a certain vertex should be less than or equal to some value. For every vertex, only the constraint with smallest value matters (if there's no constraint on this vertex, we'll add one with di = number of edges connected to i).
Consider vertex i. Assume there are qi edges connected to it and the constraint with smallest d on this vertex has dj = ei. Assume ri will be the number of red (with number 1 written on) edges connected to it at the end. With some algebra, you get that the constraint is fulfilled if and only if 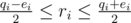 . Denote
. Denote 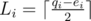 and
and 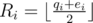 . So Li ≤ ri ≤ Ri. This gives us a L-R max-flow approach: aside these vertices, add a source S and a sink T. For every vertex v in part X, add an edge with minimum and maximum capacity Lv and Rv from S to v. For every vertex u in part Y, add an edge with minimum and maximum capacity Lu and Ru from u to T. And finally for every edge v - u from X to Y add an edge from v to u with capacity 1 (minimum capacity is 0).
. So Li ≤ ri ≤ Ri. This gives us a L-R max-flow approach: aside these vertices, add a source S and a sink T. For every vertex v in part X, add an edge with minimum and maximum capacity Lv and Rv from S to v. For every vertex u in part Y, add an edge with minimum and maximum capacity Lu and Ru from u to T. And finally for every edge v - u from X to Y add an edge from v to u with capacity 1 (minimum capacity is 0).

If there's no feasible flow in this network, answer is -1. Otherwise since r ≤ b, we want to maximize the number of red points, that is, maximizing total flow from S to T.
Since the edges in one layer (from X to Y) have unit capacities, Dinic's algorithm works in 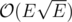 (Karzanov's theorem) and because
(Karzanov's theorem) and because 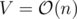 and
and 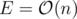 Dinic's algorithm works in
Dinic's algorithm works in 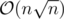 .
.
Time Complexity: 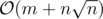
E
First, we're gonna solve the problem for when the given tree is a bamboo (path). For simplifying, assume vertices are numbered from left to right with 1, 2, .., n (it's an array). There are some events (appearing and vanishing). Sort these events in chronological order. At first (time - ∞) no suit is there. Consider a moment of time t. In time t, consider all available suits sorted in order of their positions. This gives us a vector f(t).

Lemma 1: If i and j are gonna be at the same location (and explode), there's a t such that i and j are both present in f(t) and in f(t) they're neighbours.
This is obvious since if at the moment before they explode there's another suit between them, i or j and that suit will explode (and i and j won't get to the same location).
Lemma 2: If i and j are present in f(t) and in time t, i has position less than j, then there's no time e > t such that in it i has position greater than j.
This hold because they move continuously and the moment they wanna pass by each other they explode.
So this gives us an approach: After sorting the events, process them one by one. consider ans is the best answer we've got so far (earliest explosion, initially ∞). Consider there's a set se that contains the current available suits at any time, compared by they positions (so comparing function for this set would be a little complicated, because we always want to compare the suits in the current time, i.e. the time when the current event happens). If at any moment of time, time of event to be processed is greater than or equal to ans, we break the loop. When processing events:
First of all, because current event's time is less than current ans, elements in se are still in increasing order of their position due to lemma 2 (because if two elements were gonna switch places, they would explode before this event and ans would be equal to their explosion time). There are two types of events:
Suit i appears. After updating the current moment of time (so se's comparing function can use it), we insert i into se. Then we check i with its two neighbours in se to update ans (check when i and its neighbours are gonna share the same position).
Suit i vanishes. After updating the current moment of time, we erase i from se and check its two previous neighbours (which are now neighbours to each other) and update ans by their explosion time.
This algorithm will always find the first explosion due to lemma 1 (because the suits that're gonna explode first are gonna be neighbours at some point).
This algorithm only works for bamboos. For the original problem, we'll use heavy-light decompositions. At first, we decompose the path of a suit into heavy-light sub-chains (like l sub-chains) and we replace this suit by l suits, each moving only within a subchain. Now, we solve the problem for each chain (which is a bamboo, and we know how to solve the problem for a bamboo). After replacing each suit, we'll get 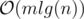 suits because
suits because 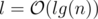 and we need an extra log for sorting events and using set, so the total time complexity is
and we need an extra log for sorting events and using set, so the total time complexity is 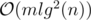 .
.
In implementation to avoid double and floating point bugs, we can use a pair of integers (real numbers).
Time Complexity (more precisely):