


Background
The idea of this article originated from a contest (Petrozavodsk Summer-2016. Petr Mitrichev Contest 14), which I believe is attributed to Petr. In this contest, an interesting problem is proposed:
"Cosider this process: pick a random number ni uniformly at random between 10 and 100. Generate ni random points with integer coordinates, picking each coordinate independently and uniformly at random from all integers between 0 and 109, inclusive. Find the convex hull of those points.
Now you are given 10000 polygons generated by this program. For each polygon, you need to guess the value ni that was used for generating it.
Your answer will be accepted if the average (over all 10000 hulls) absolute difference between the natural logarithm of your guess and the natural logarithm of the true ni is below 0.2."
Unfortunately, I didn't really manage to work this one out during our 5-hour training session. After the training is over, however, I have tried to read the solution program written by Petr, which looks like the following:
//...
public class h {
static int[] splitBy = new int[] {/* 1000 seemingly-random elements */};
static double[] splitVal = new double[] {/* another 1000 seemingly-arbitrarily-chosen elements */};
static double[] adjYes = new double[] {/* Another 1000 seemingly-stochastically-generated elements */};
static double[] adjNo = new double[] {/* ANOTHER 1000 seemingly-... elements, I'm really at my wit's end */};
public static void main(String[] args) {
/* Process the convex hull, so that
key.data[0] is the average length of the convex hull to four sides of the square border
(i.e. (0, 0) - (1E9, 1E9));
key.data[1] is the area of the hull;
key.data[2] is the number of points on the hull.
*/
double res = 0;
for (int ti = 0; ti < splitBy.length; ++ti) {
if (key.data[splitBy[ti]] >= splitVal[ti]) {
res += adjYes[ti];
} else {
res += adjNo[ti];
}
}
int guess = (int) Math.round (res);
if (guess < 10) guess = 10;
if (guess > 100) guess = 100;
pw.println (guess);
}
}
While I was struggling to understand where all the "magic numbers" come from, I do realize that the whole program is somewhat akin to a "features to output" black box, which is extensively studied in machine learning. So, I have made my own attempt at building a learner that can solve the above problem.
A lightweight learner
Apparently, most online judge simply do not support scikit-learn or tensorflow, which are common machine learning libraries in Python. (Or an 100MB model file, the imagination of 500 users with an 100MB file each makes my head ache. And yes, there are even multiple submissions.) Therefore, some handcraft code is necessary to implement a learner that is easy to use.
As a university student, I, unfortunately, do not know much about machine learning, especially in regression, where even fewer methods are adaptable. However, I somehow got particularly attracted by the idea of the neural network after some googling, both because its wide application and its simplicity, especially due to the fact that its core code can be written with about 50 lines. I will introduce some of its basic machanism below.
Understand neural network in one section
A neural network, naturally, is made up of neurons. A neuron in a neural network, by definition, is something that maps an input vector x to an output y. Specifically, a certain neuron consists of a weight vector w with the same length as x, a bias constant b, and some mapping function f, and we compute its output with the following simple formula:
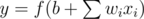
In general, we tend to use the sigmoid function as f for reasons we will see below. Other values are "tweakable" parts of a neuron that will be adjusted according to the data, as is the process of learning.
Turning back to the topic of a neural networks, it will contain several layers of neurons, where each layer reads the input from the previous layer (the first layer, of course, from the input) and outputs the result as the inputs of the next layer (or the final answer, if it is the last layer). As such, it will not be very difficult to implement a neuron network if all parameters are given, since copying the formula above will suffice.
However, how do we know what these parameters are, anyway? Well, one common way is called "gradient descent". With this method, you imagine a hyperspace with each parameter of a neuron network as an axis. Then, each point in this hyperspace actually represents a neuron network. If we can give every point (neuron network) an error value that indicates how far it is away from the ideal model, then we can simply pick a random point and begin walking (descending) towards a direction where the error value is decreasing. In the end we will reach a point where the error value is very small, which represents a good neural network that we want.


