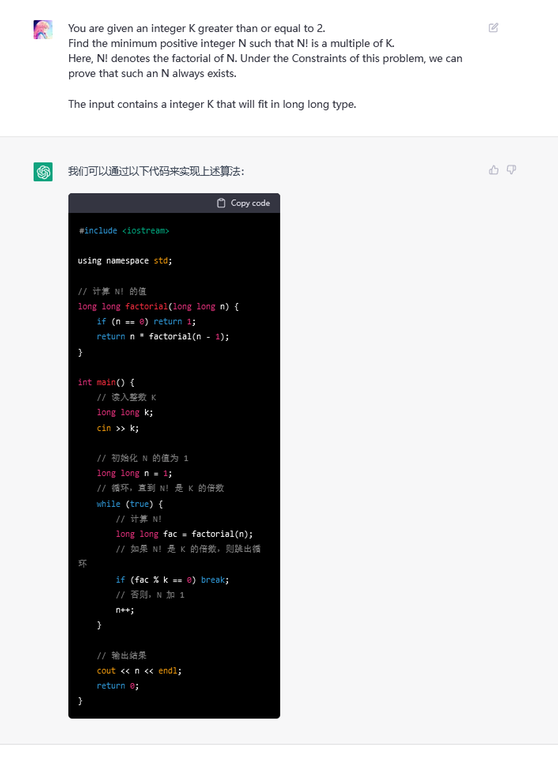
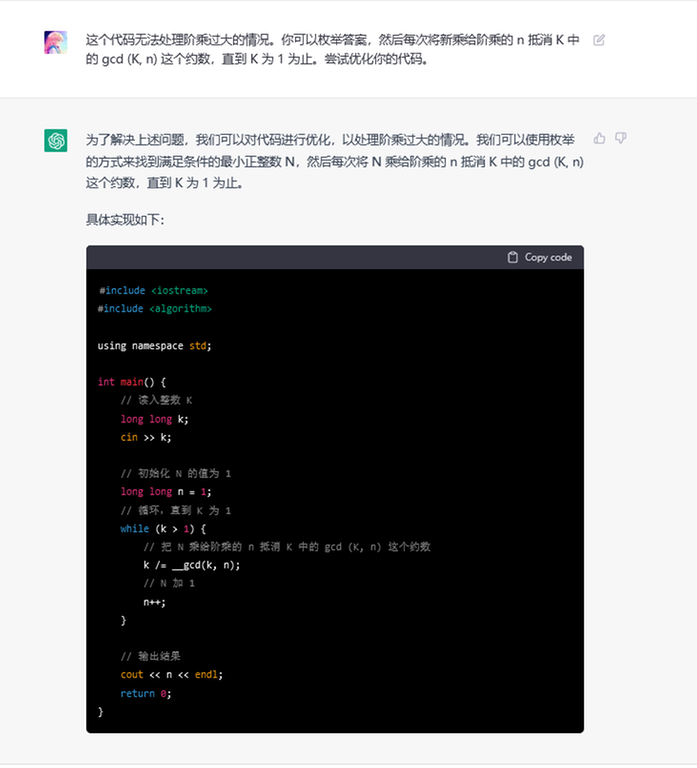
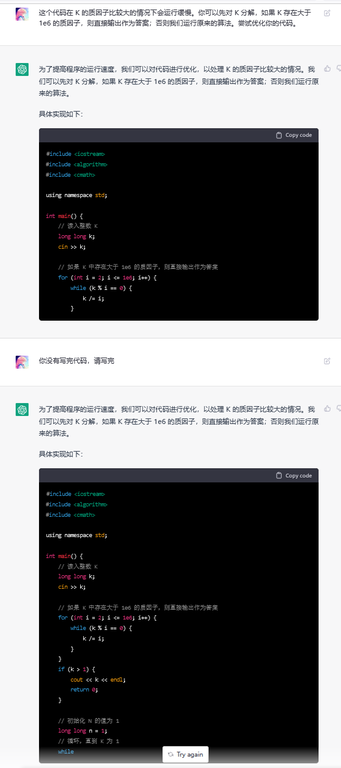
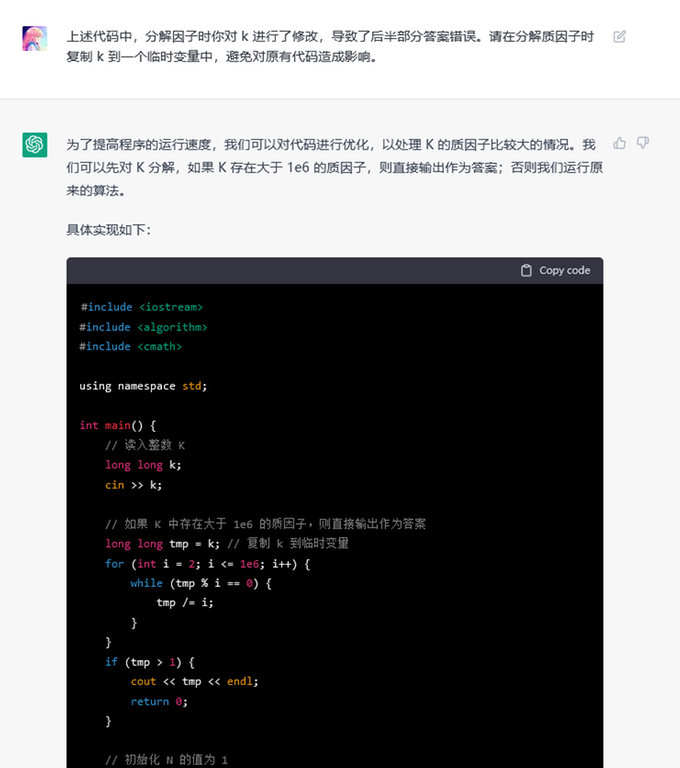
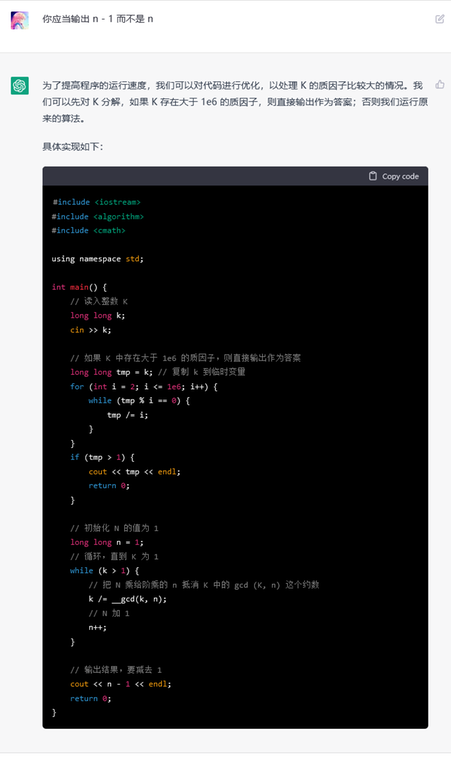
When I was doing the problem C. Pokémon Arena in the last Div. 1 round, I submitted my solution and got a TLE on pretest 20.
- GNU C++20 (64), TLE 3000ms 248951083.
I was not suspecting anything but my code, I thought there may be some degenerate issue, undefined behavior or constant issue, but nothing really found. After some unsuccessful attempts, I was able to pass the pretest using fast IO. It's then I found something weird: it only takes a few hundred milliseconds, which is contradictory to my intuition: cin with sync_with_stdio(false) is fairly fast and it should not take up so much more (at least 10x) time.
After the contest, I submitted exactly the same code with different language. You know what?
- GNU C++17, AC 280ms 248983571.
It's not only me, and some other participants also encountered such issue. For example:
- GNU C++20 (64), TLE 248946386 by fallleaves01.
Here's snippet for the key code:
int n, m;
cin >> n >> m;
vector a(n, vector (m, 0));
vector c(n, 0);
for (int i = 0; i < n; i++) cin >> c[i];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> a[i][j];
}
}
But there are also some successful cin submissions using GNU C++20 (64). After investigation by (including but not limited to) Sugar_fan, Boboge, -skyline-, the key components of TLE are:
- The language must be GNU C++20 (64).
vectormust be ofint. If the elements arelong long, it passed. 249050206- The definition of 2D
vectormust be before readingc. If swap these two lines, it passed. 249050425
So here's the thing. It could not even be simply interpreted as some branch mispredictions or cache misses, it seems something is completely broken, and we still don't understand what is actually wrong.