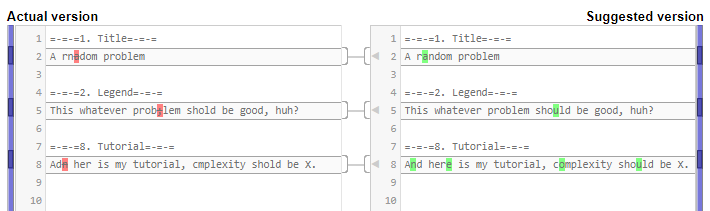
Polygon automaticly updates test meta files and produces strange difference, as JSON these files are the same but inputSha1 is moved to suffix.
MODIFIED testsets/tests/1.meta
MODIFIED testsets/tests/11.meta
MODIFIED testsets/tests/2.meta
MODIFIED testsets/tests/3.meta
MODIFIED testsets/tests/5.meta
MODIFIED testsets/tests/6.meta
MODIFIED testsets/tests/7.meta
MODIFIED testsets/tests/8.meta
MODIFIED testsets/tests/9.meta

This difference appears after any action and it prevents from commiting any changes and from building any packages. Building packages asks to commit uncommited changes before building. Commiting changes says Your changes have not been committed. Try to find and resolve conflicts
Is there any workaround?