


Codeforces Round 940 (Div. 2) and CodeCraft-23
45:53:42
Register now »
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3648 |
| 2 | Benq | 3580 |
| 3 | orzdevinwang | 3570 |
| 4 | cnnfls_csy | 3569 |
| 5 | Geothermal | 3568 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3530 |
| 8 | Radewoosh | 3520 |
| 9 | Um_nik | 3481 |
| 10 | jiangly | 3467 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | adamant | 164 |
| 2 | awoo | 164 |
| 4 | TheScrasse | 160 |
| 5 | nor | 159 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 150 |
| 7 | SecondThread | 150 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |






436A - Feed with Candy
Tutorial author: Fefer_Ivan
In this problem types of eaten candies must alternate. It means that the type of first eaten candy dictated the types of all the following candies. There are only two possible types so we should consider each type as a type of first eaten candy separatelly and then pick the most optimal. So, what if Om Nom wants to eat a candy of type t and can jump up to h? It is obvious that best option is to eat a candy with maximal mass among all the candies he can eat at this time.
436B - Om Nom and Spiders
Tutorial author: Fefer_Ivan
Let us number columns with integers from 0 from left to right and rows from 0 from top to bottom. In the cell (x, y) at the time t only four spiders can be at this cell:
- Spider, which is moving left and started at (x, y + t).
- Spider, which is moving right and started at (x, y - t).
- Spider, which is moving up and started at (x + t, y).
- Spider, which is moving down and started at (x - t, y).
Let iterate through all possible starting positions of Om Nom. Consider that he starts at column y. At time 0 all spiders are on their initial positions and Om Nom is at (0, y). There is no spiders at row 0, so at time 0 Om Nom can not meet any spiders. When Om Nom is at cell (x, y), it means that x units of time passed after the start. So to calculate the number of spiders, that Om Nom meets it is enought to check only 4 cells stated above.
436C - Dungeons and Candies
Tutorial author: Fefer_Ivan
Let's consider a weighted undirected graph with k + 1 vertex. Label the vertices with numbers from 0 to k. Vertices from 1 to k correspond to levels. For each pair of levels i and j add an edge between vertices i and j with weight equal to the cost of transferring one level as a difference from the other level. For each level i add an edge from vertex 0 to vertex i with weight equal to n·m, i.e. cost of transmitting the whole level. Each way to transmit levels defined an spanning tree of this graph. So to solve the problem, we must find a minimal spanning tree of this graph.
436D - Pudding Monsters
Tutorial author: Fefer_Ivan
This problem can be solved using dynamic programming. Let's introduce some designations: sum(l, r) — number of special cells on the segment [l, r], zi — maximal number of covered special cells using only first i monsters, di — maximal number of covered special cells using only first i monsters and with i-th monster not moving.
How to calculate di. Let's denote i-th monster position as r. Let's iterate through all special cells to the left of i-th monster. Let's denote current special cell position as l. Let's consider the situation when this cell is the leftmost special cell in the block of monsters with i-th monster in it. So we need r - l additional monsters to get to this cell from monster i. So the value of di can be updated with zi - (r - l) + sum(l, r).
Now, after we computed new value of di, we need to update some values of zj. Let's denote i-th monster position as l. Let's iterate through all special cells to the right of i-th monster. Let's denote current special cell position as r. Let's consider the situation when this cell is the rightmost special cell in the block of monsters with i-th monster in it. So we need r - l additional monsters to get to this cell from monster i. So we can update the value zi + (r - l) with di + sum(l + 1, r). Also, zi should be updated with zi - 1.
So the solution works in O(n·m) because for each of n monsters we iterate through all m special cells and for a fixed monster-cell pair all computing is done in O(1).
There are some details about monsters, that are merged at the initial state, but they are pretty easy to figure out.
436E - Cardboard Box
Tutorial author: Gerald, Nerevar
In this task you have to come with the proper greedy algorithms. Several algorithms will fit, let's describe one of them:
- From that point we will consider that the levels are sorted by increasing value of b.
- Let's look at some optimal solution (a set of completed levels). From levels that we completed for two stars, select the level k with the largest b[k]. It turns out that all levels that stand before k (remember, the levels are sorted) should be completed for at least one star. Otherwise, we could complete some of the previous levels instead of the level k. This won't increase the cost.
- Let's fix a prefix of the first L levels and solve the problem with the assumption that each of the selected levels should be completed. Additionally, we will assume that all levels that are completed for two stars are within this prefix (as was shown before, such prefix of L levels always exists for some optimal solution).
- As we will surely complete this L levels, we can imagine that we have initially completed all of the for just one star. So, we have w - L more stars to get. We can get these stars either by completing some of the levels that are outside our prefix for one star, or by completing some of the first L levels for two stars instead of one star.
- It's clear that we just have to choose w - L cheapest options, which correspond to w - L smallest numbers among the following: b[i] - a[i] for i ≤ L and a[i] for i > L. Computing the sum of these smallest values can be done with a data structure like Cartesian tree or BIT.
The described solution has time completixy of O(n log n).
436F - Banners
Tutorial author: Gerald, Nerevar
Task F was the hardest one in the problemset. To better understand the solution, let's look at the task from the geometrical point of view. Imagine that people are point in the Opc plane (value of p and q are points' coordinates). Then for each line horizontal c = i we have to find such vertical line p = j that maximizes some target function. The function is computed as follows: (number of points not below c = i, multiplied by w·i) plus (number of points below c = i and not to the left of p = j, multiplied by j).
Let's move scanning line upwards (consider values c = 0, then c = 1, etc). For each value of p we will store the value d[p] — the value of the target function with the current value of c and this value of p. The problem is: if we have such array d[] for the value c, how to recompute it for the value c + 1?
Let's look at all people that will be affected by the increase of c: these are the people with b[i] = c. With the current c they are still using free version, after the increase they won't. Each of these people makes the following effect to the array: d[1] + = 1, d[2] + = 2, ..., d[b[i]] + = b[i]
Now the task can be reduced to the problem related with data structures. There are two types of queries: add the increasing arithmetical progression to the prefix of the array and retrieve the maximum value of the array. One of the way to solve it is to use sqrt-decomposition.
Let's divide all queries into groups of size sqrt(q). Let's denote the queries from the group as a sequence: p1, p2, ..., pk (k = sqrt(q)). For query pi we should perform assignments d[1] + = 1, d[2] + = 2, ..., d[pi] + = pi. Imagine we already preformed all the queries. Each value of new array d[] can be represented as d[i] = oldD[i] + i·coef[i], where coef[i] is the number of pj (pj > i).
One can notice that array coef contains at most sqrt(q) distinct values, additionally this array can be splitted into O(sqrt(q)) parts such that all elements from the same part will be the same. This is the key observation. We will divide array coef into parts. And for each part will maintain lower envelope of the lines y = d[i] + i·x. So, we will have O(sqrt(q)) lower envelopes. Each envelope will help us to get maximum value among the segment of array d[i](oldD[i] + i·coef[i]). As for each i from some segment factor coef[i] is containt we can just pick y-coordinate with x = coef[i] of corresponding lower envelope.
Described solution has time complexity of O(MAXX·sqrt(MAXX)), where MAXX is the maximum value among a[i] and b[i]. With best regards, Ivan.
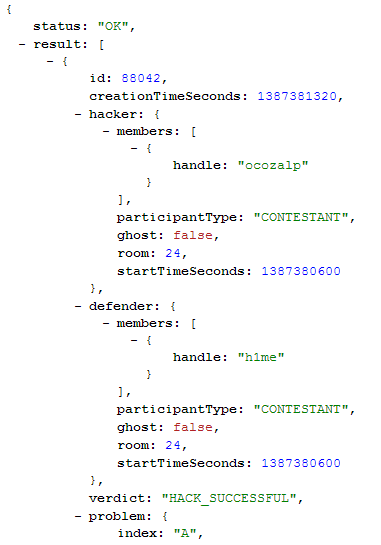
Hello, Codeforces!
Today we want to introduce Codeforces API. With it you now can access some of Codeforces data in machine-readable JSON format.
API has a detailed manual, which is supported to contain only actual information. Every method has an example URL. You can use it to see the example response and to experiment with different parameters.
By default, any API request will be anonymous and will have access only to public data. To make a request on behalf of some user, a user must create an API-key at /settings/api and read the bottom part of the manual at /apiHelp.
For now, all methods are read-only. Write-methods like "submit a solution" are coming soon.
We are open to suggestions and requests for new API-methods. Especially from respected members of contest programming community.
With best regards, Ivan.
Hello, Codeforces.
UPD: Round is finished. Thank you for your participation. Final results.
Today (16:00 UTC) we want you to take part in testing and unrated round with unussual scoring system. With your help we want to test new scoring, new type of problems and Codeforces system inside <iframe> tag.
Start time is 16:00 UTC
There are two types of problems: logic puzzles and programming tasks.
A logic puzzle is a task that is designed to be solved by hand (but it is not forbidden to write some helper code to do this). Each logic puzzle consists of one or more tests. Each question can be answered separately from the others. There is a "Submit" button below each test. To answer the question, press "Submit" button. Your answer will be acknowledged and checked after the end of the contest. You can change your answer any number of times – only the last attempt is checked. For the correct answer to the question you will get the number of points which is indicated in the question description.
A programming task is want you can ussually see in Codeforces rounds. Solutions can be submitted at any time during the contest. A solution is evaluated on a fixed set of tests right after it is submitted. For each passed test, a contestant will get a fixed amount of points. The sum of points for all passed tests is the total points received by the solution. The contestant can submit a solution several times. The contestant will receive points for only one solution per problem. The solution with the maximum amount of points will be chosen.
The contest period is divided into two sections: Normal Time (NT) and Extra Time (ET). Each contestant is in only one of these at a time, but which one you're in can vary per contestant. In other words, when one contestant is in Normal Time, another one could be in Extra Time.
Normal Time lasts for at most 30 minutes starting from when you click the button "Start Contest". (It could be less than 30 minutes if you start the contest less than 30 minutes before it ends). Points gained in Normal Time are the main way of deciding who wins. A participant with more points gained in Normal Time will always have a better ranking than a participant gaining fewer points in Normal Time.
After Normal Time ends you can still solve problems until the contest ends. This period is called Extra Time, and points gained in Extra Time are the second way to order contestants. Thus points gained in Extra Time are used to rank participants that have the same number of points gained in Normal Time.
If a pair of contestants have the same number of points gained in Normal Time and the same number of points gained in Extra Time, they will be ordered according to the time (in seconds) of the last submission which gave them an improved positive score. For each programming task, we will consider only the best submission (or if there are many submissions which are equally correct, the earliest). For logic puzzles, if you submit new answers in Extra Time, whatever score you would have got is over-written by your new submission, and those points are changed into Extra Time points.
In other words, it's always safe to submit a new answer for programming tasks (you can only improve your situation). It is not always safe to do that for logic puzzles – consider carefully whether or not you want to do that.
The problems will be relativly easy but, I hope, they will be interesting, as will be the contest format.
We will be greatful for all community members who help us in testing.
With best regards, Ivan.
Hello, Codeforces!
Today I want to tell you about great Codeforces update which is planned to be release on 7th of April.
The main new feature of Codeforces will be Codeforces Premium.
You don't have enought rating to create a gym contests?
You want to create an open group with a Div. 2 account?
O(n2) solution can not possibly pass because of stupid Time Limit?
Rounds are full of despair?

Hello, Codeforces.
UPD: Mashup feature is disabled until the end of the round. This is temporary and won't happen in the future.
Today we want to present you with our latest feature: mashup contests.


Hello, Codeforces.
Today group functionality was updated and extended:
Here is a list of changes:
Personal blog entries now can be attached to the group blog.
New blog entries can be written directly to the group blog. Such entries won’t be displayed in recent actions and votes for it or for it’s comments will not affect contribution.
Only managers can write or attach entries to the group blog. Entries can be read by and commented by all group members.
New group role was added. Now there are three group member types: spectator, participant and manager. Spectator is a group member, which can not register to the group contest and is not displayed in group standings. But spectator can see the standings, see the problems, read and comment group blog. For example, if you want someone to see the trainings of the group, but not to participate, you can invite the user as spectator.
Spectator registration policy can have same values as participant registration policy. Spectator registration policy can not be more strict that participant’s one. By default it is set to be the same as the participant registration policy.
Also, there is an additional registration policy for spectators – automatic registration. It means that anonymous and non-member users will be considered spectators. They will not be displayed in group members table. For example, if you want to organize the championship of your university, you can create a group, invite only official participants of the contest as group participants and set spectator registration policy to automatic. So only official participants will be able to register to the contest and take part in it, but standings and problems will be open to public.
There were changes in the security policy of the group web pages. To access a group web page, user must be a group member. To all anonymous or non-member users to see the web pages of your group, you must set spectator registration policy to automatic.
With best regards, Ivan.

Hello, Codeforces!
Today I would like to tell you about new Codeforces feature: about groups. Now you can create a group , invite people into it, add members to group and organize contests inside a group.
Create a Group
Only Div.1 coders can create a group. Good reason to increase rating, right? If you have rights to create a group on the Groups page, it will be a special link. Except name, you can specify:
- description (feel free to use simple HTML)
- logo: it will shine on each group’s page!
- related to group website URL
Good night/dawn/morning/day/dusk/evening/night, Codeforces!
Today I am glad to present you the latest features of the Polygon — the system for creation and preparation of programming problems and contests. All Codeforces Rounds are made using Polygon.
New features are concentrated around test script.
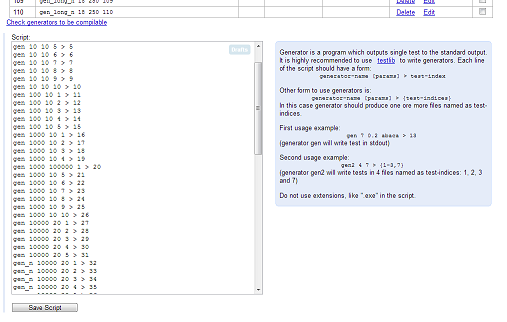
Part one. Test autonumeration
The first new feature allows you to automatically numerate tests.
Instead of this
gen_n 5 10 1 > 57
gen_n 5 10 2 > 58
gen_n 5 10 3 > 59
gen_n 5 10 4 > 60
gen_n 5 10 5 > 61
you can now write this
gen_n 5 10 1 > $
gen_n 5 10 2 > $
gen_n 5 10 3 > $
gen_n 5 10 4 > $
gen_n 5 10 5 > $
Dollar sign, used to mark autonumeration, stands for the first unused test index. So, for example:
gen 1 > $
gen 2 > $
gen 4 > $
gen 5 > $
gen 3 > 3
will be translated to
gen 1 > 1
gen 2 > 2
gen 3 > 3
gen 4 > 4
gen 5 > 5
But don't you think, that dollars will be replace with actual numbers upon saving the script. It would be too easy and boring. Of course, they stay. If you enter the script from example above and save it, you will see this:
gen 1 > $
gen 2 > $
gen 3 > 3
gen 4 > $
gen 5 > $
If you delete any test, all dollar tests will be renumerated instantly and they will still be dollars instead of exact nunbers.
Also, did you now, that you can drag and drop tests to renumerate them? For example to move 40th test to the 7th position? This feature is very old, but it is rarelly noticed, so I decided to remind you about it. Dollar tests are also drugable.
But there is always a fly in the ointment. We decied not to support dollars for generators, which generate multiple tests. They have syntax like this
gen > {5-10,12,15}
So generator must produce 7 tests and put the to files 05, 06, ..., 10, 12, 15. So if we made them dollars and delete test number 1, we will get {4-9,11,14} instead of {5-10,12,15}.But the generator is not changed and still produce files 05, 06, etc. To avoid such problems, generators with file output does not support dollars.
Part two. Scripts for generating scripts
Now you can write script using Freemarker Template Engine, that will be executed inside the Polygon and the result will be used as test scritp. So for example instead of this
gen 10 1 1 > $
gen 10 1 2 > $
gen 10 1 3 > $
gen 100 4 1 > $
gen 100 4 2 > $
gen 100 4 3 > $
gen 1000 9 1 > $
gen 1000 9 2 > $
gen 1000 9 3 > $
gen 10000 16 1 > $
gen 10000 16 2 > $
gen 10000 16 3 > $
we can just write this
<#assign n = 1>
<#list 1..4 as pow>
<#assign n = n * 10/>
<#list 1..3 as i>
gen ${n} ${pow * pow} ${i} > $
</#list>
</#list>
You can find a brief tutorial about Freemarker at https://polygon.codeforces.com/docs/freemarker-manual. To find more details about the language you can read the official documentation.
But, script must be always consistent with the test table. It adds some limitation to the use of Freemarker.
It is impossible to delete, edit or move script test using web-interface. To do it, you must edit the script directly.
It is necessary to use dollars instead of indices. This limitation allow us to move manual test to any possition without changing the script.
Dollars are not supported by multiple test generators, so it is impossible to use them inside Freemarker script. But, in my opinion, if you already wrote program, that generates all tests, why would you need Freemarker : )
As you will see, there are two new buttons near Save Script: Preview Script and Run Script.
Preview Script shows you the final result — which test will get which generator line.
Run Script replaces your Freemarker script with old-style script, in other words, with the sequence of generator lines. You can use this button, if you do not need Freemarker any more? but could use some of the locked features. Please note, that this button only replaces the script in the text field. You need to save it by pressing Save Script button.
That is all for now. I hope new features will make it easier for you to prepare problems for Codeforces Rounds and other contests.
With best regards, Ivan.
Tutorial by Fefer_Ivan
To solve this problem we can count the number of digits 1, 2 and 3 in the input. If there are c1 digits 1, c2 digits 2 and c3 digits 3. Then we must print the sequence of c1 digits 1, c2 digits 2 and c3 digits 3. Digits must be separated by + sign.
Tutorial by Fefer_Ivan
To solve this problem we must learn how to calculate fast enought the time, needed to travel between houses a and b. Let's consider the case when a ≤ b. Than Xenia needs b - a seconds to get from a to b. Otherwise a > b, Xenia will have to go thought house number 1. So she will need n - a + b seconds.
Tutorial by Fefer_Ivan
Let's consider the definition of balance. Balance is the difference between sum of all weights on the left pan and sum of all weights on the right pan. At the beginning balance is equal to 0. Att each step Xenia puts one weight on the pan. It means she adds to or substracts from balance integer from 1 to 10. In each odd step, the integer is added and in each even step the integer is subtracted. From the statement we know, that after each step, balance must change it sign and must not be equal to 0. So if after some step the absolute value of balance is greater than 10, Xenia can not continue. Also, it is said in the statement that we can not use two equal weigths in a row. To solve the problem, let's consider a graph, where vertices are tuples of three numbers (i, j, k), where i is a current balance, j is a weight, used in the previous step, and k is the number of the current step. Arcs of the graph must correspond to Xenias actions, described in the statement. The solution of the problme is a path from vertex (0, 0, 1) to some vertex (x, y, m), where x, y are any numbers, and m is the requared number of steps.
339D - Xenia and Bit Operations
Tutorial by Gerald
The problem could be solved by using a typical data structure (segment tree).
The leafs of the segment tree will store the values of ai. At the vertices, the distance from which to the leafs is 1, we will store OR of the numbers from the leafs, which are the sons of this node in the segment tree. Similarly, vertices, the distance from which to the leafs is 2, we will store Xor of the numbers stored in their immediate sons. And so on. Then, the root of the tree will contain the required value v.
There is no need to rebuild all the tree to perform an update operation. To do update, we should find a path from the root to the corresponding leaf and recalculate the values only at the tree vertices that are lying on that path. If everything is done correctly, then each update query will be executed in O(n) time. Also we need O(2n) memory.
Tutorial by Gerald
We will call the command l, r a reverse, also we will call the row of horses an array. Suddenly, right?
The problem can be solved with clever bruteforcing all possible ways to reverse an array. To begin with, assume that the reverse with l = r is ok. Our solution can find an answer with such kind of reverses. It is clear that this thing doesn't affect the solution. Because such reverses can simply be erased from the answer.
The key idea: reverses split an array into no more than seven segments of the original array. In other words, imagine that the array elements was originally glued together, and each reverse cuts a segment from the array. Then the array would be cut into not more than 7 pieces.
Now you can come up with the wrong solution to the problem, and then come up with optimization that turns it into right. So, bruteforce all ways to cut array into 7 or less pieces. Then bruteforce reverse operations, but each reverse operation should contain only whole pieces. It is clear that this solution is correct, One thing it does not fit the TL.
How to improve it? Note that the previous solution requires the exact partition of the array only at the very end of the bruteforce. It needed to check whether it is possible to get the given array a. So, let's assume that the array was originally somehow divided into 7 parts (we don't know the exact partition), the parts can be empty. Now try to bruteforce reverses as in naive solution. One thing, in the very end of bruteforce try to find such a partition of the array to get (with fixed reverses) the given array a.
The search for such a partition can be done greedily (the reader has an opportunity to come up with it himself). Author's solution does this in time proportional to the number of parts, that is, 7 operations. However, this can be done for O(n) — this should fit in TL, if you write bruteforce carefully.
Hello, Codeforces.
Today at 19:30 moscow time, Codeforces Round #197 will take place.
Authors of this round are me and Gerald. I'd like to thank the following people for their contribution: Delinur for translation of the statements and MikeMirzayanov for creation and supportion of Codeforces.
The score for problems: 500 — 1000 — 1500 — 2000 — 3000.
Good luck!
UPD: To make the announcement more interestiong and thrilling we decided to add a horse joke and a photo, taken during the preparation of the round.
Q: What did the teacher say when the horse walked into the class?
A: Why the long face?

Good afternoon, Codeforces!
Today I'll tell you about a new feature of Polygon system, which is used to prepare all Codeforces rounds. Of course the system is open to any user – many contests for other competitions and training camps are prepared there.
Two key elements of a problem, besides the author's solution, tests and statements, are two programs: the validator and the checker.
The validator is the program that reads the test and reports whether it corresponds to the condition of a problem or not. Validators must be absolutely formal – a validator validates a test if and only if it meets the conditions of the problem and can be safely added to the test set. You can easily write validators using the testlib.h library. Sometimes authors neglect validators (which never happens during the Codeforces contests) and it threatens the validity of tests. Since the Codeforces contests contain hacks, the importance of correct validator greatly increases. Naturally, all the hacks are validated before reaching a contestant’s solution. Most tasks have relatively simple validators, but when a problem contains additional conditions (for example, that there is a solution for the test), then the complexity of the validator is greatly increased.
The checker is the program that receives the test, the output of the participant’s code, the output of the jury’s code and determines the correctness of the participant’s output. Unfortunately, errors in the checker often lead to serious consequences. Not all problems let you simply compare the solutions. For example, in problem 234H - Merging Two Decks the checker uses a Cartesian tree. If the problem statement requires a certificate, then it’s a good idea to write the checker in the concept of readAnswer(ans)/readAnswer(ouf). You can easily write checkers using the testlib.h library.
Testing of these programs usually takes place either manually from the command line or indirectly — by adding wrong solutions and temporarily adding of non-valid tests. In fact, the authors often neglect to test checkers and validators. This method of testing is inconvenient, and the tests are not saved. When there are two authors cooperating, a co-author cannot view the tests, on which the validator/checker were tested, or restart them after the correction of the validator or checker.
The updated version of Polygon has improved immensely! We’ve made a convenient means for testing the validator and the checker.
Good afternoon, Codeforces.
Today I want to tell you about latest update of the Codeforces.
- We all saw a lot of comments from participants, who forgot that some problems have file based input/output and got wrong answer on test 1. Now if the problem has file based input/output, needed file names are highlighted in the statement (for example: 254A - Cards with Numbers), at the contest dashboard (for example: Codeforces Round 155 (Div. 2)) and at the submission page (for example: screenshot).
- Now it is possible to view a test, used for hack (for example: http://codeforces.com/contest/292/hacks). Of course duriong the contest this option is only available to the participant, who performed a hack. Usualy, if someone gets "Invalid input" verdict for the hack, it is difficult to find what is wrong with the test. The only thing you got is validator message like this
[FAIL Integer parameter equals to 500, violates the range [1, 400) .... Also it is impossible to find out if there was a typo in the test. This new "View test" feature is created to help in such cases. When you click "View test" link, you will get a test in plain text if the test for hack was entered manually, or report about test generation and generator source if the hack used generator. Plain text format was chosen to make possible coping of the test simply by pressing Ctrl + A, Ctrl + C. - It was impossible to use file based input/output with C# language. Now it is fixed and working. A lot of minor bugs were fixed too.
- Submission with verdict "Wrong answer on hack 1" was not counted as failed submission. It was a bug and it is fixed now too.
{kind=link}
That is all for now, but the work to improve Codeforces is going on and I hope we will be able to write a post about another series of improvements soon.
With best regards, Ivan.
Good evening, Codeforces.
Today I've added the first five contest of the famous Andrew Stankevich Contest series. They are available for virtual participation and practice.
I competed in several Andrew Stankevich Contests and I can say that these contests are always well prepared and consist of extremely interesting problems. You can really enjoy taking part in them.
Good luck and have fun.
P.S. All contests are available in Andrew Stankevich Contests group.
Direct links
Please note that all problems uses different input and output files. You can find correct input/output file names at the contest dashboard and in the statements.
- 2002-2003 Winter Petrozavodsk Camp, Andrew Stankevich Contest 1 (ASC 1)
- 2003-2004 Summer Petrozavodsk Camp, Andrew Stankevich Contest 2 (ASC 2)
- 2003-2004 Summer Petrozavodsk Camp, Andrew Stankevich Contest 3 (ASC 3)
- 2003-2004 Winter Petrozavodsk Camp, Andrew Stankevich Contest 4 (ASC 4)
- 2003-2004 Winter Petrozavodsk Camp, Andrew Stankevich Contest 5 (ASC 5)
- 2003-2004 Winter Petrozavodsk Camp, Andrew Stankevich Contest 6 (ASC 6)
- 2004-2005 Summer Petrozavodsk Camp, Andrew Stankevich Contest 7 (ASC 7)
- 2004-2005 Summer Petrozavodsk Camp, Andrew Stankevich Contest 8 (ASC 8)
- 2004-2005 Summer Petrozavodsk Camp, Andrew Stankevich Contest 9 (ASC 9)
- 2004-2005 Winter Petrozavodsk Camp, Andrew Stankevich Contest 10 (ASC 10)
- 2004-2005 Winter Petrozavodsk Camp, Andrew Stankevich Contest 11 (ASC 11)
- 2004-2005 Winter Petrozavodsk Camp, Andrew Stankevich Contest 12 (ASC 12)
- 2005-2006 Summer Petrozavodsk Camp, Andrew Stankevich Contest 13 (ASC 13)
- 2005-2006 Summer Petrozavodsk Camp, Andrew Stankevich Contest 14 (ASC 14)
- 2005-2006 Summer Petrozavodsk Camp, Andrew Stankevich Contest 15 (ASC 15)
- 2005-2006 Winter Petrozavodsk Camp, Andrew Stankevich Contest 16 (ASC 16)
- 2005-2006 Winter Petrozavodsk Camp, Andrew Stankevich Contest 17 (ASC 17)
- 2005-2006 Winter Petrozavodsk Camp, Andrew Stankevich Contest 18 (ASC 18)
- 2006-2007 Summer Petrozavodsk Camp, Andrew Stankevich Contest 19 (ASC 19)
- 2006-2007 Summer Petrozavodsk Camp, Andrew Stankevich Contest 20 (ASC 20)
- 2006-2007 Summer Petrozavodsk Camp, Andrew Stankevich Contest 21 (ASC 21)
- 2006-2007 Winter Petrozavodsk Camp, Andrew Stankevich Contest 22 (ASC 22)
- 2006-2007 Winter Petrozavodsk Camp, Andrew Stankevich Contest 23 (ASC 23)
- 2006-2007 Winter Petrozavodsk Camp, Andrew Stankevich Contest 24 (ASC 24)
- 2007-2008 Summer Petrozavodsk Camp, Andrew Stankevich Contest 25 (ASC 25)
- 2007-2008 Summer Petrozavodsk Camp, Andrew Stankevich Contest 26 (ASC 26)
- 2007-2008 Summer Petrozavodsk Camp, Andrew Stankevich Contest 27 (ASC 27)
- 2007-2008 Winter Petrozavodsk Camp, Andrew Stankevich Contest 28 (ASC 28)
- 2007-2008 Winter Petrozavodsk Camp, Andrew Stankevich Contest 29 (ASC 29)
- 2007-2008 Winter Petrozavodsk Camp, Andrew Stankevich Contest 30 (ASC 30)
- 2008-2009 Summer Petrozavodsk Camp, Andrew Stankevich Contest 31 (ASC 31)
- 2008-2009 Summer Petrozavodsk Camp, Andrew Stankevich Contest 32 (ASC 32)
- 2008-2009 Winter Petrozavodsk Camp, Andrew Stankevich Contest 33 (ASC 33)
- 2008-2009 Winter Petrozavodsk Camp, Andrew Stankevich Contest 34 (ASC 34)
- 2009-2010 Summer Petrozavodsk Camp, Andrew Stankevich Contest 35 (ASC 35)
- 2009-2010 Summer Petrozavodsk Camp, Andrew Stankevich Contest 36 (ASC 36)
- 2009-2010 Winter Petrozavodsk Camp, Andrew Stankevich Contest 37 (ASC 37)
- 2010-2011 Summer Petrozavodsk Camp, Andrew Stankevich Contest 38 (ASC 38)
- 2010-2011 Winter Petrozavodsk Camp, Andrew Stankevich Contest 39 (ASC 39)
- 2011-2012 Summer Petrozavodsk Camp, Andrew Stankevich Contest 40 (ASC 40)
- 2011-2012 Winter Petrozavodsk Camp, Andrew Stankevich Contest 41 (ASC 41)
- 2012-2013 Summer Petrozavodsk Camp, Andrew Stankevich Contest 42 (ASC 42)
- 2012-2013 Winter Petrozavodsk Camp, Andrew Stankevich Contest 43 (ASC 43)
- 2013-2014 Summer Petrozavodsk Camp, Andrew Stankevich Contest 44 (ASC 44)
- 2013-2014 Winter Petrozavodsk Camp, Andrew Stankevich Contest 45 (ASC 45)
- 2014-2015 Summer Petrozavodsk Camp, Andrew Stankevich Contest 46 (ASC 46)
- UPD 2014-2015 Winter Petrozavodsk Camp, Andrew Stankevich Contest 47 (ASC 47)
Hello, Codeforces!
Recently I joined the team of Codeforces developers. Today I want to tell you about first major feature implemented by me.
Now in your social profile (http://codeforces.com/settings/social) you can enter an organization you want to represent.
It can be university, college, school or any other organization. If you want to enter school, lyceum or gymnasium, please add a city to avoid any ambiguousness. For example: instead of PhTL #1 please enter Saratov, PhTL #1.
When you are filling the Organization field, please, use autocomplition and follow the tips. Or it will become a mess. And we will have to clean it up with TRUNCATE TABLE.
It is possible that one organization can have different names. Especially it is true for universities. You should try to avoid too short names, because they can lead to ambiguousness. For example: SSU can stand for Saratov State Universiry, Samara State University or Syktyvkar State University.
But long names are not very good too. Can you imagine how it will look if tourist will decide to enter the full name of his university: Saint Petersburg State University of Information Technologies, Mechanics and Optics? : )
As it is with countries, you will be able to see rating of organiztion and rating of users inside particular organization.
With best regards, Ivan
