For all of you who used codeblocks as an IDE for CP: there is no codeblocks on IOI now.
There was no announcements about this and in Belarus, we learned about it by accident, so I'm writing this blog for you to know.
| # | User | Rating |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| # | User | Contrib. |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 151 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
For all of you who used codeblocks as an IDE for CP: there is no codeblocks on IOI now.
There was no announcements about this and in Belarus, we learned about it by accident, so I'm writing this blog for you to know.

Hello, Codeforces!
I am very glad to invite you to the Codeforces Round #861 (Div. 2), which will take place in Mar/29/2023 12:05 (Moscow time). This round will be rated for the participants with rating lower than 2100.
My sincere thanks to:
Wind_Eagle, BaluconisTima, kartel, gepardo and 244mhq for the tasks ideas, and also BaluconisTima, 244mhq, VEGAnn, Vladik and andrew for preparing the tasks.
vilcheuski and programmer228 the rest of the author team, without whom this round would not have happened.
BaluconisTima for the splendacious pictures, which complement each problem.
MikeMirzayanov for Codeforces and Polygon platforms.
You for participating in this round.
You will have 2 hours and 30 minutes for solving 6 tasks, one of which will be divided into easy and hard verions. The round is based on the problems from the Belarusian National Olympiad. We kindly ask all Belarusian students who participated in this olympiad, to refrain from taking part in this round and discussing the problems publicly before the round ends.
I hope you will enjoy the round!
Round testers (will be available later): Ormlis, 4qqqq, nnv-nick, olya.masaeva, Makcum888.
Preliminary score distribution: 750-1000-1500-2000-2500-3250.
UPD: the round was rebalanced. You will have 2 hours for solving 5 tasks, one of which will be divided into easy, medium and hard verions.
Score distribution: 750-1000-1500-1750-(1750+1000+750).
Editorial: https://codeforces.com/blog/entry/114523
Winners:
Div. 1 + Div. 2:
2) maspy
3) happylmb
Div. 2:
1) happylmb
2) Cherished
3) 2021_yes
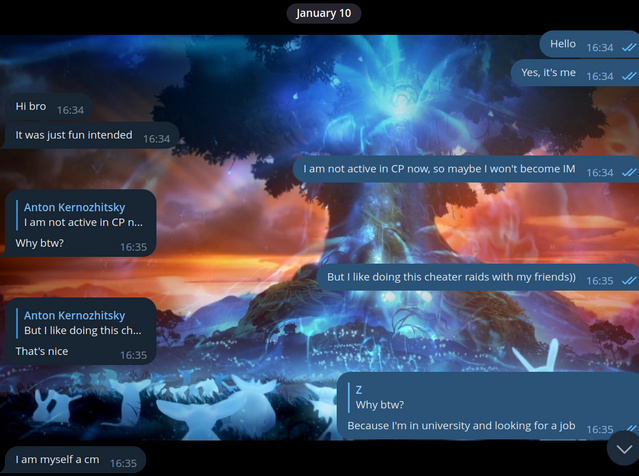
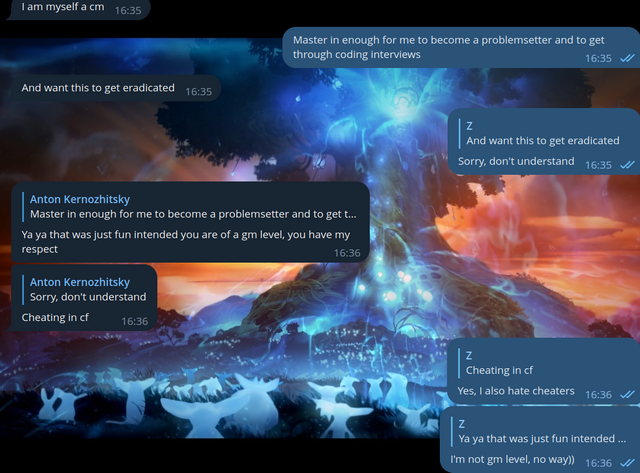
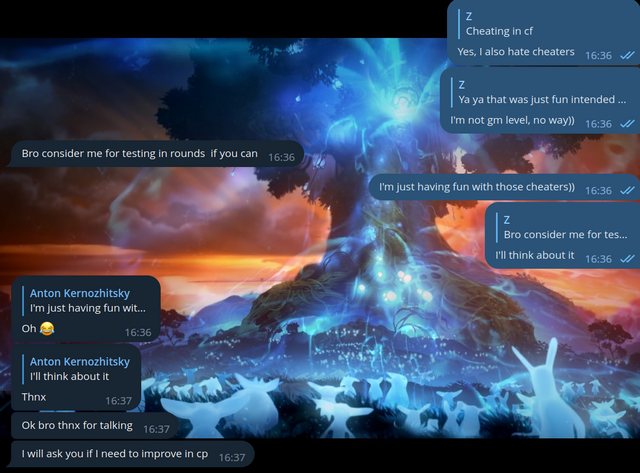
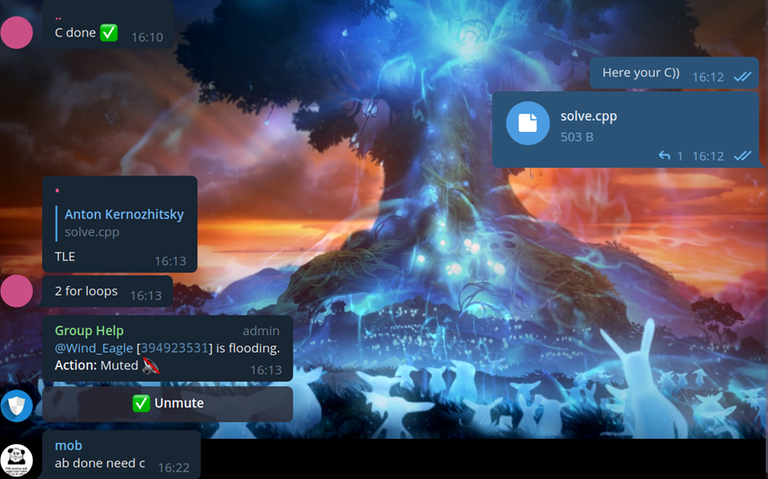
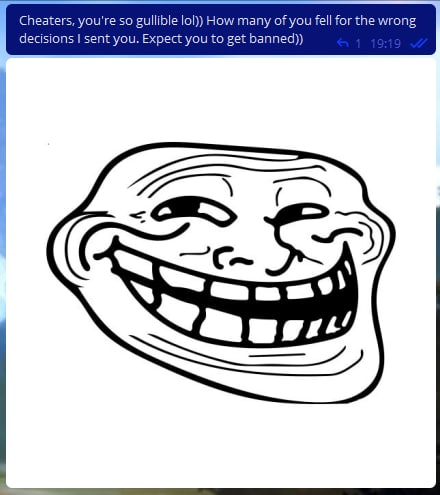
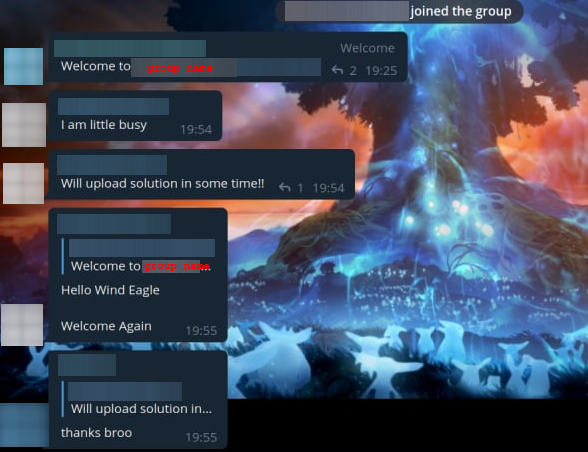
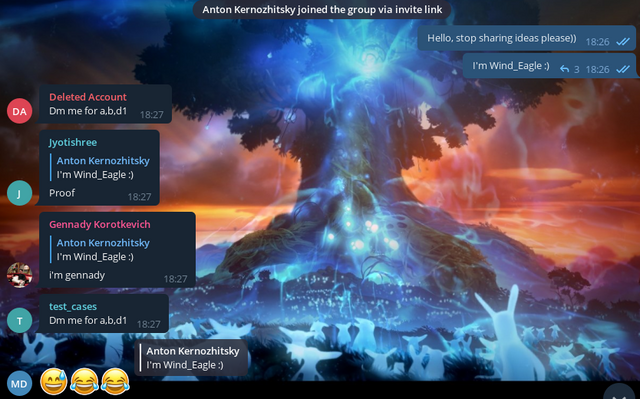
Hello, Codeforces! Codeforces #843 (Div. 2) round took place not so long ago, and I was one of its authors. When an hour had passed since the contest had started, I (you could say, by tradition) decided to enter the groups with cheaters and make fun of them once again.
And one more thing before we begin. peltorator has launched a cool blog contest, I encourage everyone to participate: blog.
Next. COOLMAARK, thanks for writing about the cheaters group, but it was better to do it not in the comments to the announcement, for not to advertise the group.
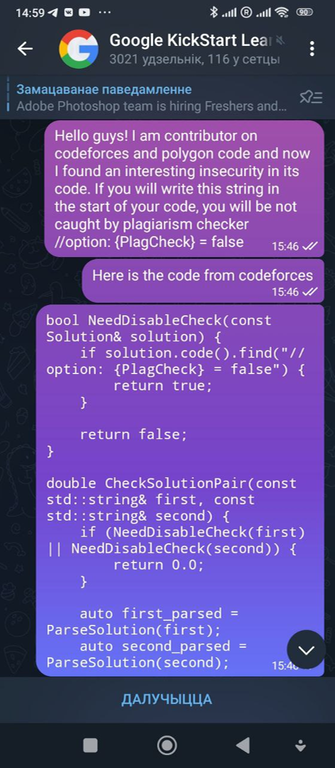
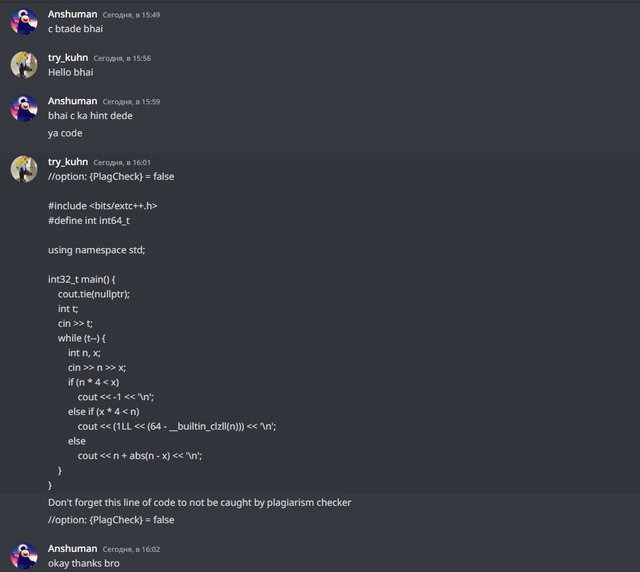
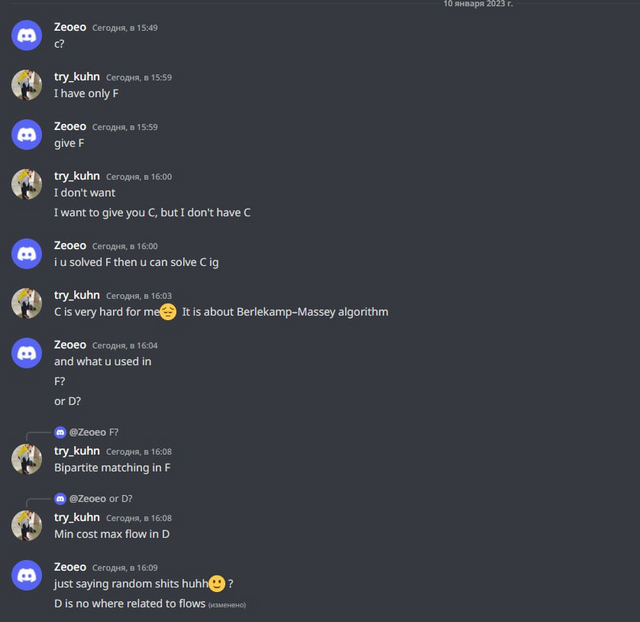
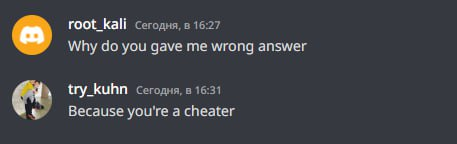
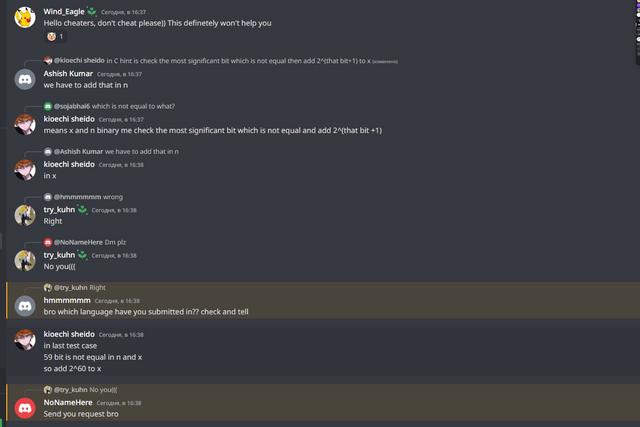
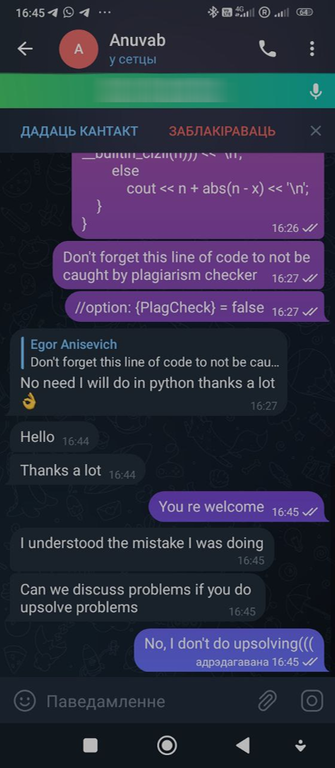
Now to the point. So, since some cheaters recognize me, I invited try_kuhn to help. In all the past cases, there was a problem: yes, sure, cheaters would submit the bad code, but they would change it, which would make it harder to automatically check for anti-plagiarism. So I decided to try to get around that.
So, try_kuhn went to that group on discord and two other groups on telegram, and wrote this message:
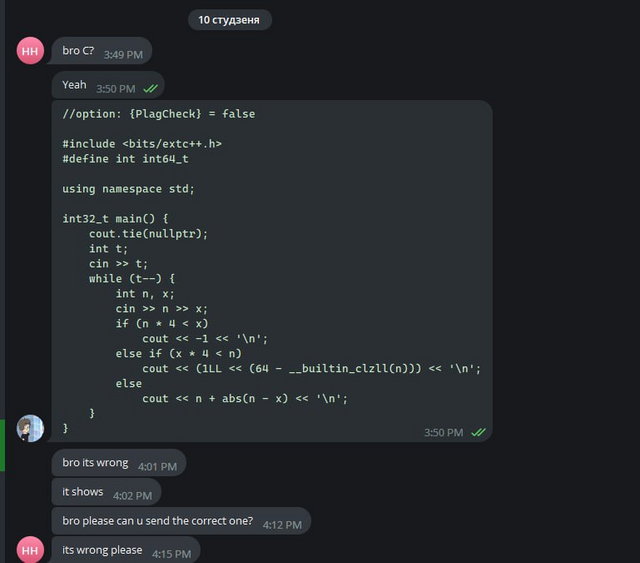
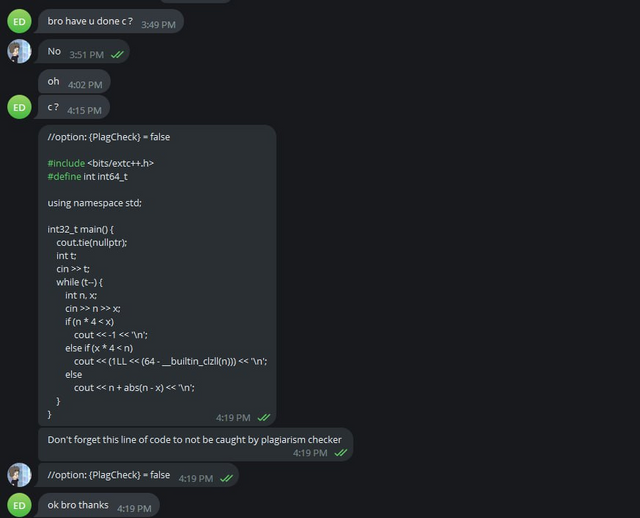
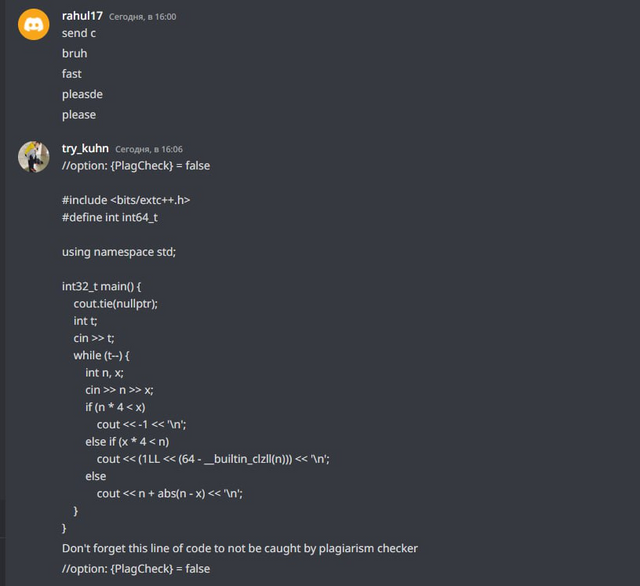
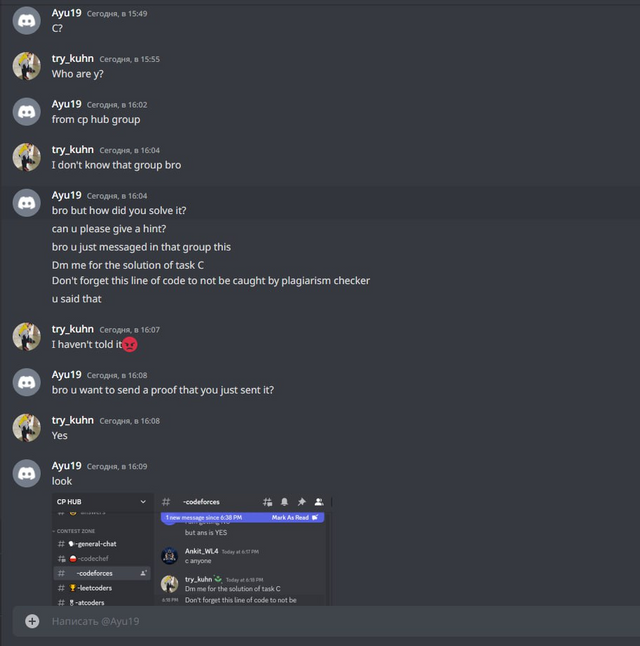
In this way, we hoped that cheaters would believe us and start sending code without changes. Also, just like last time, we wrote a completely wrong solution to the C problem, so that the cheaters would make WA on simple and wrong code and get caught by the anti-plagiarism.
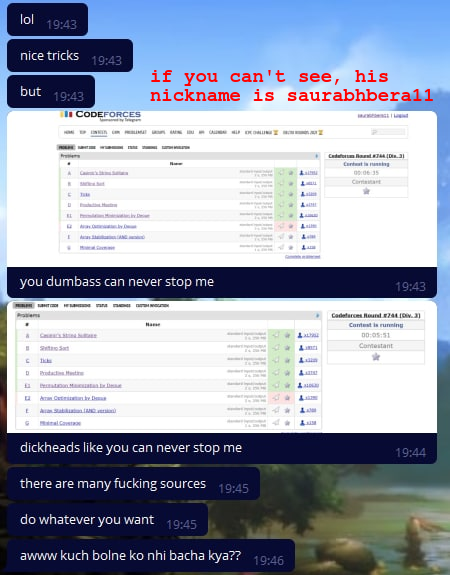
Also try_kuhn went into two telegram groups, and started dropping off wrong solutions to everyone.
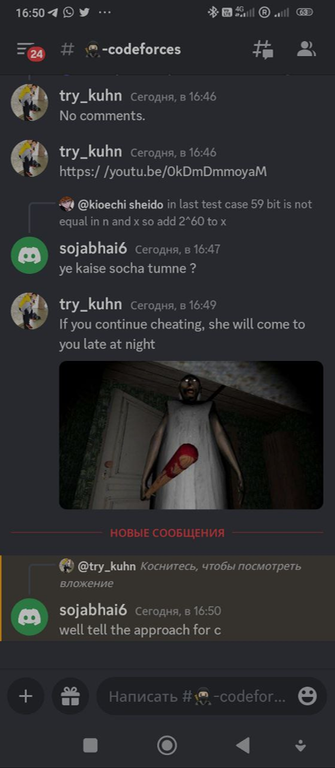
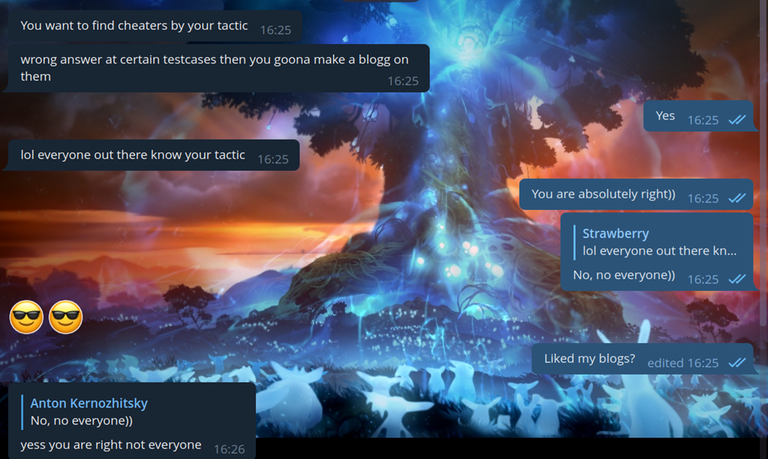
For some cheaters, we didn't send the code, but made fun of them on purpose. I have collected the most interesting messages for you.
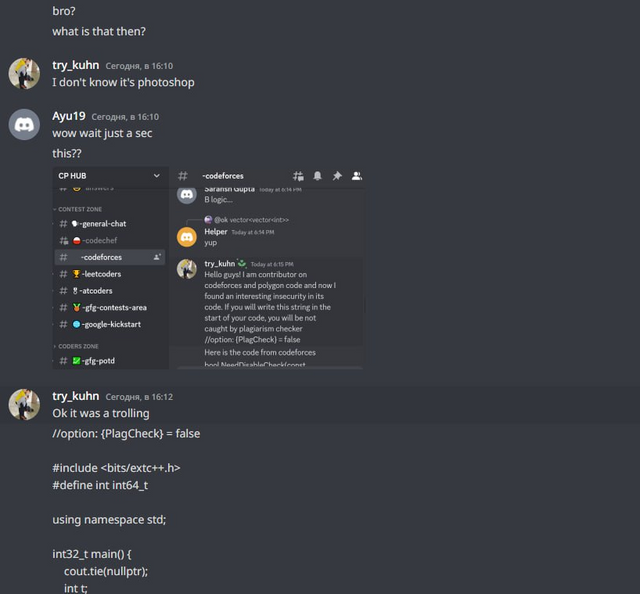
Here we decided to make a maximum absurdity in this correspondence:
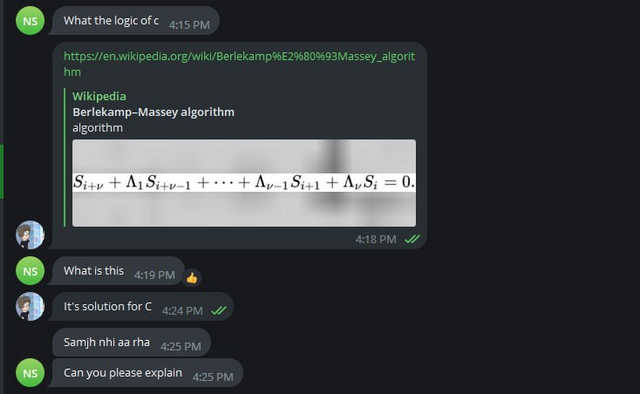
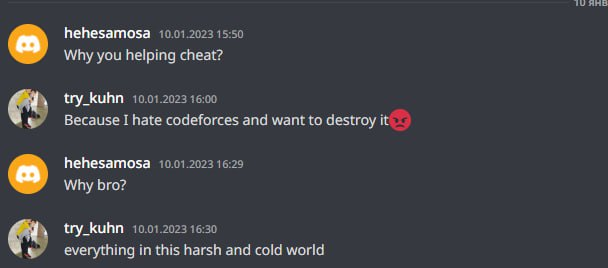
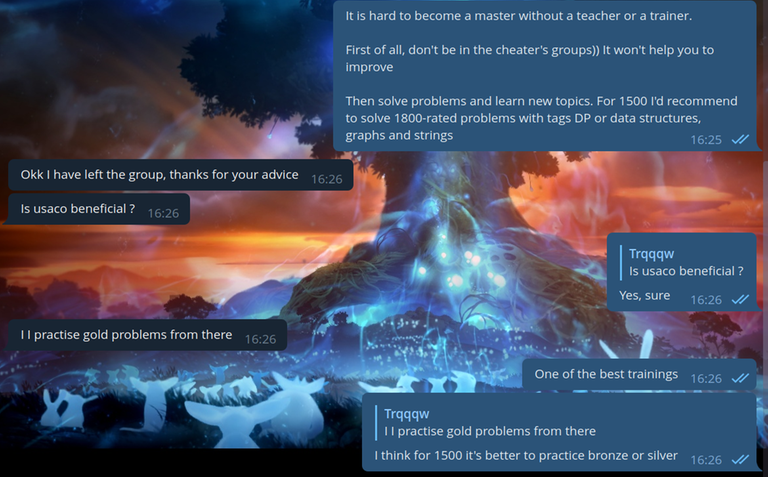
I believe that my trolling should not only help to ban cheaters, but also help them learn sports programming. So we thought it would be a good idea to make cheaters at least learn the algorithms:
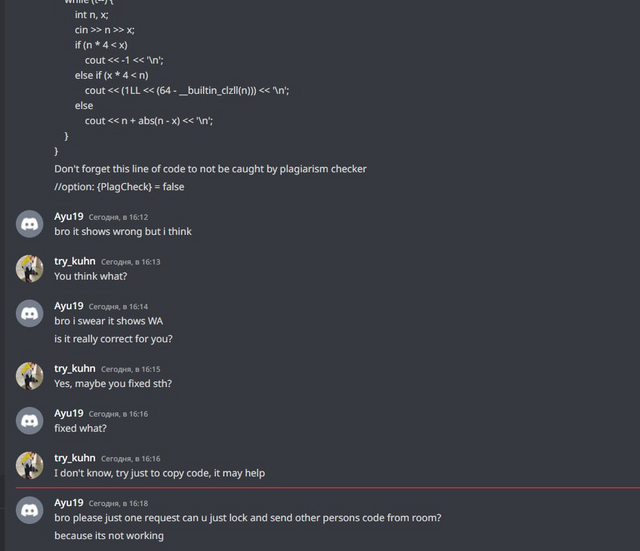
To be honest, in this case we even overcomplicated the algorithm. I even feel a little sorry for this cheater. He's obviously not a very high ranker, and here's something like this:
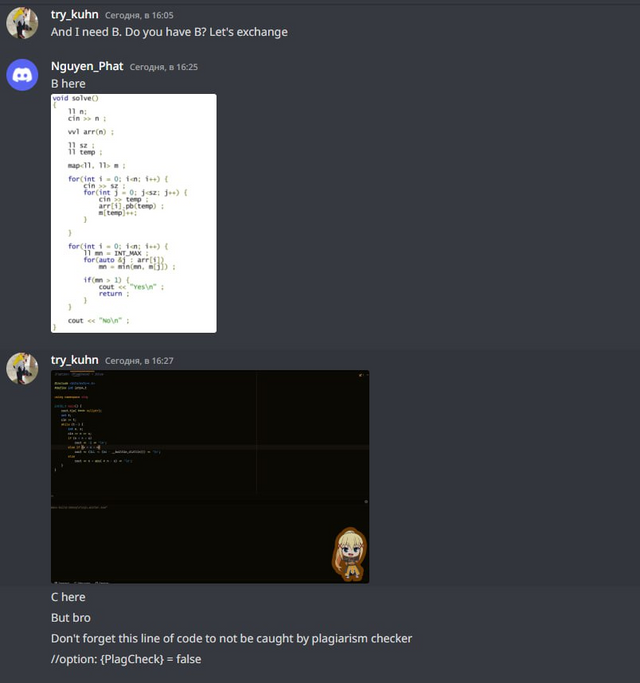
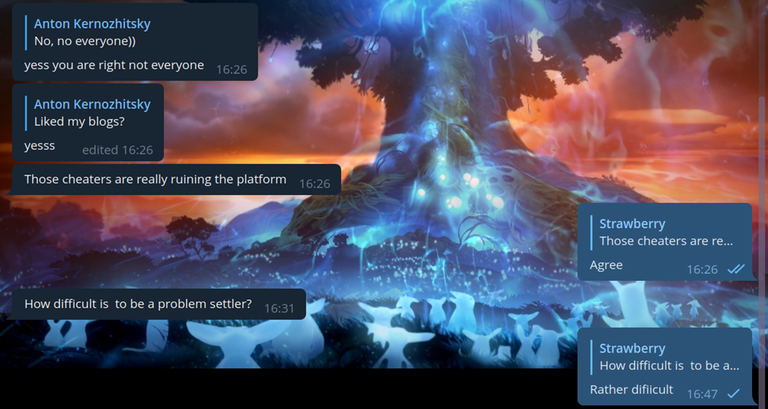
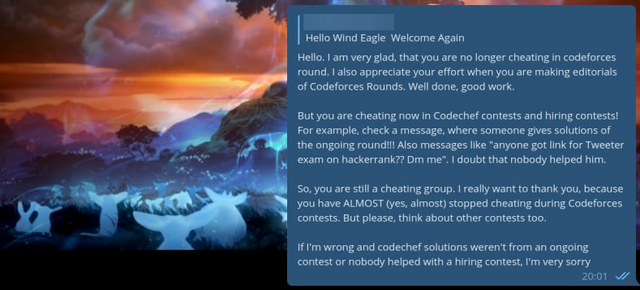
And I would like to refer to the last blog. I'm often reminded of a screenshot from a previous blog about cheaters, so let it be similar here:
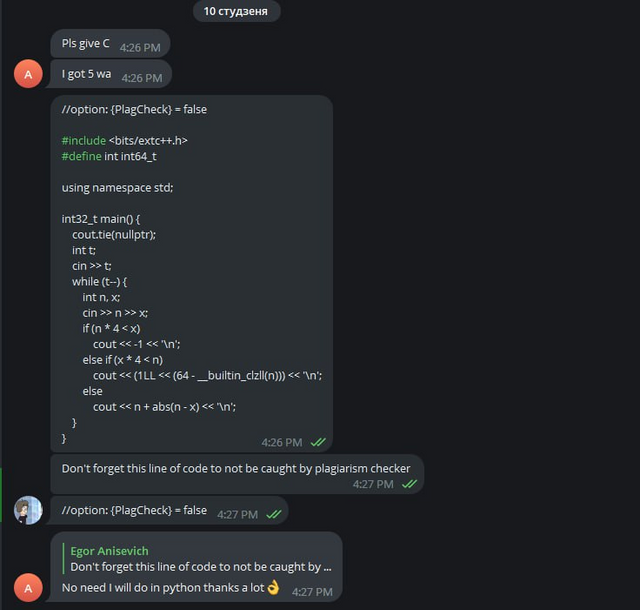
In the last blog, I also decided to exchange solutions with cheaters, but we cheated each other: I sent him the wrong code, and he sent me the wrong code. This time, it looks like it was just me who wasn't honest:
I knew that cheaters convert C++ code to assembly language to bypass the anti-plagiarism check — but this cheater was even trickier.
It seemed to us that cheating all cheaters is somehow too much, and we decided to confess:
Well, at least it's honest:
Somone the group turned out to be either not a cheater, or a very conscientious cheater. Either way, they decided to make fun of him:
Where without the cheaters, who are trying to make money:
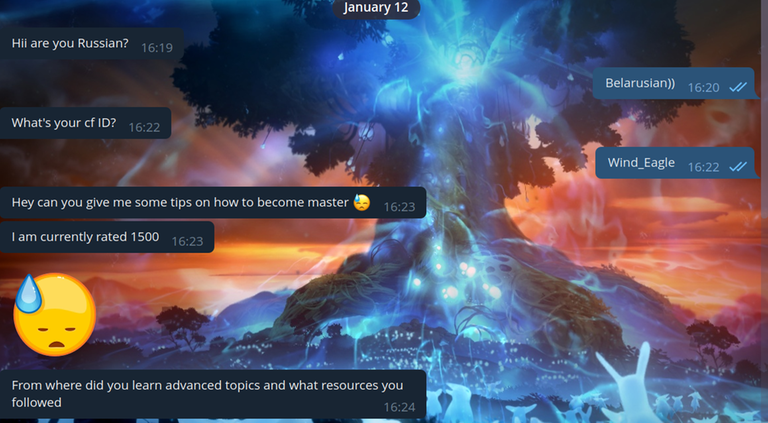
I never cease to be amazed at how people recognize me, even though I am not the one who writes messages in these groups! I decided to write to this person and talk to him by myself:
Finally, I decided to show up in their group:
A couple more funny correspondences happened:
All in all, it was an interesting adventure. In conclusion: cheaters, I do not really understand why do you do it. Well, look: there's nothing in it from a practical point of view. The rating on codeforces has no effect on the job search. Honestly, no employer needs that number in your profile. It also will not give you success in the contests if it is obtained dishonestly. And if you're doing it just to look cool, that's not clear to me either. Yes, maybe some people will be impressed, but if the truth comes out, I think no one will believe you in the future. Moreover, you will understand by yourself that this is not fair.
Thanks for reading this blog!
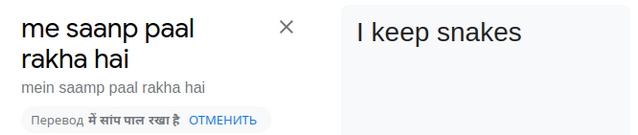
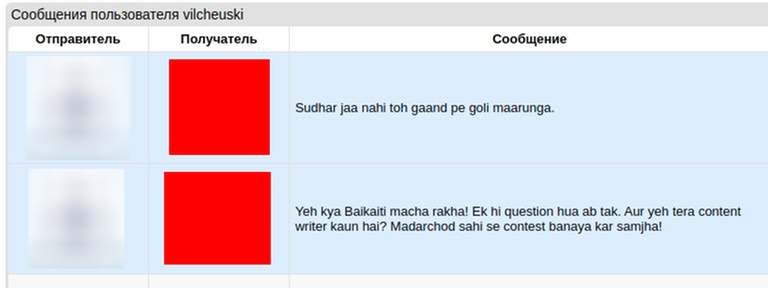
P.S. If you read this blog and understand the phrases that cheaters wrote to me in a language other than English, please post the translation of the phrases in the comments. Google translator didn't help:

Hello, Codeforces!
I am very glad to invite you to the Codeforces Round #843 (Div. 2), which will take place in Jan/10/2023 14:15 (Moscow time). This round will be rated for the participants with rating lower than 2100.
My sincere thanks to:
Wind_Eagle, BaluconisTima, kartel и Aleks5d for the tasks ideas, and also Wind_Eagle, BaluconisTima, kartel, VEGAnn и Vladik for preparing the tasks.
andrew, gepardo, 244mhq, vilcheuski the rest of the author team, without whom this round would not have happened.
BaluconisTima for the splendacious pictures, which complement each problem.
MikeMirzayanov for Codeforces and Polygon platforms.
You for participating in this round.
You will have 2 hours and 30 minutes for solving 6 tasks, one of which will be divided into easy and hard verions. The round is based on the problems from the first day of Belarusian Regional olympiad. We kindly ask all Belarusian pupils who participated in this olympiad, to refrain from taking part in this round and discussing the problems publicly before the round ends.
I hope you will enjoy the round!
Round testers (not complete list): MathBoy, FairyWinx, nnv-nick, K1ppy, olya.masaeva, Septimelon, PavelKorchagin, 4qqqq, kova1.
Score distribution: (500+1000)-1000-1500-2000-2000-2500.
UPD. Score distribution was changed: (500+500)-1000-1500-2000-2250-3000.
UPD2: Congratulations to the winners!
Vote for your favourite task!
Task А: Gardener and the Capybaras
Task B: Gardener and the Array
UPD3: Finally, here is the editorial: press here
Divide and conquer. Dynamic connectivity offline and DP optimization. Divide and conquer by queries.
Hello, Codeforces! I have wanted to write an educational blog for a long time, but I couldn't find a topic for it. And recently I remembered that Codeforces doesn't have a good blog on one of my favorite topics: the "divide and conquer" technique. So I want to talk about it. The outline will be something like this:
1) Divide and conquer. What this technique is and what it is for. Example.
2) Dynamic connectivity offline with divide and conquer. Divide and conquer dp optimization.
3) Let me tell you about a method I invented myself: divide and conquer by queries. In this case, we divide not only the array, but also the queries into groups.
So, here we go.
First, about what this technique is. The point is about the following: let's say we have an array. Then, if we know how to calculate the answer for two parts of it, and if we know how to get the answer for the whole array from the answers of two parts, we can apply the divide and conquer technique. Let me show you the simplest example: merge sort.
In merge sort we have an array of $$$n$$$ elements, for simplicity, numbers. To sort the subarray $$$[l ... r]$$$, we sort the subarrays $$$[l ... m]$$$ and $$$[m + 1 ... r]$$$, where $$$l \le m \le r$$$, then merge the two sorted arrays into one. Let's see how to do this in the easiest way.
In fact, let us have two arrays. We know that they are sorted, for example, by non-decreasing. Then to merge the two arrays into one, we can apply the following algorithm:
1) If the first array is empty, add the second array to the array with the result and quit. 2) If the second array is empty, add the first array to the array with the result and quit. 3) If both arrays are not empty, then take the smallest of the first two elements of the arrays, add it to the answer and remove it from the original array.
Of course, we should not remove from the beginning of the array, but it is much better to store a pointer to the current element we are considering. If you write in C++, I recommend using the std::merge function instead of this handwritten algorithm. Still, sometimes it is useful to understand how it works.
Now we will act recursively: write a function sort(l, r) that sorts the segment from l to r:
sort(l, r):
if l == r:
return
m = (l + r) / 2
sort(l, m)
sort(m + 1, r)
merge(l, m, m + 1, r)
So now let's estimate the running time of such sorting. It seems logical to divide the array roughly in half, that is, $$$m = \lfloor \frac{l + r}{2} \rfloor $$$. Let's see how many operations our algorithm can perform. For simplicity, let's put the number of array elements $$$n = 2^k$$$. Then it is clear that combining subarrays of size $$$1$$$ will take a total of $$$O(n)$$$ operations, combining subarrays of size $$$2$$$ will take $$$O(n)$$$ operations, then $$$4$$$, $$$8$$$, and so on.
From this you can see that the algorithm will perform $$$O(n)$$$ actions when combining each of the "layers", and since there are $$$k$$$ such layers, it works for $$$O(nk) = O(n \log n)$$$ in total. This construction resembles a segment tree. In fact, it almost is. For example, if in a segment tree each vertex has a subarray corresponding to that vertex, then the amount of memory spent on it will be $$$O (n \log n)$$$, and so will the construction time (you can prove it by yourself as an exercise).
Some other algorithms, such as dynamic connectivity offline, are also based on the divide and conquer method. The task is to handle such requests offline:
1) Add an edge to the graph.
2) Remove an edge from the graph.
3) Check if two vertices lie in the same connected component.
This topic may be a bit complicated for beginners, so if it is difficult, you can skip it. Since I could not quickly find English-language materials on this method, I will describe it here, although it is quite well known.
The problem is not very difficult to solve using SQRT decomposition, but I will tell the solution in $$$O(q \log n \log q)$$$.
Suppose the graph has $$$n$$$ vertices and $$$q$$$ queries, moreover, the graph is initially empty. If this is not the case, then simply add first type queries to the beginning.
Now let's define for each edge a lifetime: a continuous interval of request numbers during which the edge exists. Each check request corresponds to some time: essentially, just its input number.
Now let us build such a segment tree: it will store the numbers of edges. Initially this segment tree is empty. Now for an edge with lifetime [l ... r] write this addition to the segment tree:
add(v, tl, tr, l, r):
if l > r:
return
if tl == l && tr == r:
tree[v].insert(edge)
return
tm = (tl + tr) / 2
add(v * 2, tl, tm, l, min(r, tm))
add(v * 2 + 1, tm + 1, tr, max(l, tm + 1), r)
That is, we wrote a segment tree that is very similar to the one that assigns to a segment, only without the lazy propagation. So what did we end up with? You can see that now the segment [l ... r] turns out to be divided into $$$O(\log n)$$$ segments from the segment tree. Let us now run the DFS in this way:
dfs(v, tl, tr):
if tl == tr:
answer_query(tl)
return
tm = (tl + tr) / 2
edge_set.insert_edges(tree[v])
dfs(v * 2, tl, tm)
dfs(v * 2 + 1, tm + 1, tr)
edge_set.erase_edges(tree[v])
Now notice that when we have come to the leaf corresponding to the segment [w ... w], the $$$edge$$$_$$$set$$$ will contain those and only those edges that were "alive" at time $$$w$$$, so in fact we will get the list of edges that were at time $$$w$$$.
So, if we know how to quickly respond using a list of edges, we would have a ready solution. Unfortunately, we can only add edges to a regular DSU, and with this solution we still need to remove them. That is why we need to use a persistent DSU. Don't be afraid, it isn't complicated. Let's write a regular DSU with, for example, rank heuristics, or size heuristics. Then every time an edge is added, it just changes the immediate ancestor of one of the vertices, and changes the rank/size of the subtree of one of the vertices. Let's add to a special array after each added edge information about which vertex and what changes were made. Then we can cancel the last added edge for $$$O(1)$$$. In principle, this is enough for us.
The asymptotic evaluation is now clear: adding one edge to the segment tree takes $$$O(\log q)$$$ operations, and the whole dfs will take $$$O(q \cdot t_1 + S \cdot t_2)$$$, where $$$t_1$$$ is time to respond to the request, $$$S$$$ is the total number of edges stored in the segment tree, and $$$t_2$$$ is time to add and remove one edge. Given that $$$t_1 = O(\log n)$$$, $$$S = O(q \log q)$$$, and $$$t_2 = O(\log n)$$$, we come to the required asymptotics.
A task on this topic: https://codeforces.com/problemset/problem/813/F
Now briefly mention DP optimization divide and conquer. It allows you to reduce the running time of some DPs under certain conditions. You can read about it in English, for example, here: https://cp-algorithms.com/dynamic_programming/divide-and-conquer-dp.html
A task on this topic: https://codeforces.com/problemset/problem/868/F
Now let's get to the fun part: divide and conquer by queries. I came up with this method on my own while solving a problem (more on that later). I don't know if I'm the first person to come up with this method, but honestly, I haven't seen it before. If it's been described somewhere before me, please write me a comment about it.
This method is somewhat similar to the segment tree that stores queries, but it seems to me somewhat easier to write and understand.
Let's solve the following problem: https://codeforces.com/problemset/problem/763/E
Let's proceed this way: first we build a divide-and-conquer on an array. We can use it to construct a DSU for each segment in question, and we can also find the answer at the prefix and suffix of each segment: indeed, this is just the number of different connectivity components on the segment. We can do this by adding one vertex at a time to the DSU.
But how do we respond to requests? This is where divide and conquer by queries comes into play. When considering segment [l ... r], let us answer only such queries [ql ... qr] that $$$ql \le m < qr$$$, that is, only such queries whose left bound lies on segment [l ... m] and whose right bound lies on segment [m + 1 ... r]. Clearly, other queries will be considered either in [l ... m] or in [m + 1 ... r].
Now it becomes easy to answer such queries: we can take two DSUs, connect them into one, and add edges on the boundaries. Since $$$k$$$ is small, there will be few such edges.
Thus, we got a pretty fast and nice solution to this problem. You can see that it doesn't use a query-based segment tree.
Finally, let's look at another problem that can be solved using this method: https://codeforces.com/gym/101590/problem/D
Unfortunately, it only has a Russian statement, so I'll tell you what you need to do:
An array of $$$n$$$ triples of numbers is given, as well as the number $$$D$$$. Also given $$$q$$$ of queries with segments $$$l_i$$$ and $$$r_i$$$. You need to choose one number from each triplet on the segment, so that the sum is as large as possible, but divisible by $$$D$$$. For example, if the triples (1, 2, 3), (4, 5, 6) and (1, 7, 8) are given, and $$$D = 8$$$, then you can choose $$$3$$$, $$$6$$$ and $$$7$$$.
$$$n \le 50,000, q \le 300,000, D \le 50$$$.
From this problem it is clear why a segment tree is not always better. In fact, let's try to write a segment tree, each vertex of which will have a DP on that segment. But then let's estimate the running time. Clearly, the DP will be one-dimensional: $$$dp[r]$$$, where $$$r$$$ from the word remainder. It is not difficult to calculate for each remainder what the maximal sum will be.
But here's the problem: when it comes to the segment tree, it turns out that the union of two DPs works for $$$O(D ^ 2)$$$, and the segment tree simply will not pass!
But here we can apply divide and conquer to the queries: we will separately calculate DPs for the left half, and separately calculate DPs for the right half. We will store DPs for each suffix of the left half and for each prefix of the right half (remember, DPs are arrays of $$$D$$$ numbers). We will answer only those queries that intersect both segments. To do this, simply take the DP of the corresponding suffix, and the DP of the corresponding prefix, and go through the remainder $$$r$$$ of the prefix (the remainder of the suffix will equal $$$D - r$$$). Thus, we got the solution for $$$O(q \cdot D + n \cdot \log n \cdot D)$$$.
I hope you enjoyed this blog. This is my first educational blog, and I have tried to write as clearly as possible. If you still have questions, feel free to leave them in the comments.
Hello, Codeforces! I have a small question.
Recently I have seen some codes that use assembly, for example, this: code.
Of course, I understand, that this is done to cheat plagiarism checker. But shouldn't assembly code be not allowed? According to the codeforces rules, "it is forbidden to obfuscate the solution code as well as create obstacles for its reading and understanding. That is, it is forbidden to use any special techniques aimed at making the code difficult to read and understand the principle of its work."
Does this rule really work nowadays?
Hello, Codeforces! I, like many of you, read blogs periodically. Lately, blogs from low-rated users who ask me how to raise their ratings have been catching my attention. I want to tell you a little bit about my opinion on these blogs.
So what do these blogs look like? Usually this is a blog with a title something like "I need help right now!" or "How to improve my rating, help me!" When you open this blog, you see the most detailed description of the problem, such as: "I have solved 500 problems, but no improvement" or "I have solved 100 problems with rating >= 1500, but my rating is not increasing". And in the comments they usually write "you haven't solved enough, solve more" or "solve more difficult problems". In my opinion, this is incorrect and misleads such users.
So, imagine that you do not know anything at all about sports programming, or even about the basics of Olympic math. You at best (because many people don't even do that) have learned a programming language at a basic level (really, who needs templates and classes), such as C++. And so, you decide to become a sports programmer to get a job interview enjoy solving interesting problems. Imagine yourself as this person. Can you? No, imagine please, it's important.
When you have imagined this, imagine now that you have no friends at all who know what programming is. "Programming, huh? Is that edible?" Well, I'm kidding, of course, but it could very well be that no one around you is into programming. So, now there is a question. How to improve?" "What's a stupid question?" — you ask, "of course, just go and solve problems!" Just everything, and maybe some ladder (which I don't know much about). So, I declare: in my opinion, this is very bad advice, which will only harm someone who starts his way in sports programming. You have imagined yourself as a beginner, haven't you? Now think about it: if you only know high school math, can you solve D2A? If you think you can, I'll let you in on a secret: if you are not a born genius in sports programming, you probably can't.
Let me tell you a little about why. As can be seen from my profile, I'm from Belarus, from the city of Mogilev. In this glorious city there is a glorious gymnasium number two, where my wonderful EIK teacher teaches. She has many Olympiadists, both beginners and very experienced, like Dmi34, and a bunch of experienced, among them, for example, me, as well as another international master and international grandmaster. And I can tell you: if you take the beginners now, I'm not sure that they could solve even D2A in the first year at once. I'll explain why.
The whole point is that even D2A should actually be approached gradually (unless, of course, you have experience in math olympiads, say — then solving D2A in general is not a bad idea). Back to our mental experiment — take any random D2A from the last two years.
Totally randomly I chose round 672 and Problem A from it (1420A - Cubes Sorting). Think about it: How easy is it for someone who only knows school math to solve this problem? For example, in our university department we have a small section (for one or two lectures) devoted to permutations, and from this knowledge it is easy to solve this problem. But if you only know school math (and you have an ordinary, unremarkable school), then solving such a problem will obviously not be that easy. Actually, understanding that an unsorted array can be sorted by a bubble sort in n * (n-1) / 2 operations is not that hard, if you reason logically. As I see it, it is harder to show that for an unsorted array this does not hold.
Or round 697, problem A (1475A - Odd Divisor). Of course, this problem can be solved by simply writing out all the numbers on a piece of paper and finding a pattern. But here you need to know what is decomposition of a number into prime factors, know that it is singular, and so on. Thinking back to the greedy algorithms, I can mention the problem from round 765, problem A (again chosen at random) (1625A - Ancient Civilization).
My point is this. You need to know mathematics for sports programming. Now imagine: someone has solved, say, 100 problems A. Consider that most of them do not contain any new and interesting ideas at all, but just, as they say, ad-hoc. So what will one learn from these problems? I'm not sure, but it seems to me that simply nothing! One will remember twenty ideas, but the twenty-first will still be different. Going back to our imaginary newcomer: he has no one to ask, no one to ask to explain. No one to explain the standard ideas and approaches. So what does he have to do but cheat to write blogs?
The situation with problems B, C, and D is even worse. To solve them, you usually need to already know the standard ideas. The problem is that in order to practice these standard ideas, you need to solve problems on these standard ideas, not immediately D2C — D2D. Imagine if you were learning a segment tree right away from a 3000 difficulty problem. That's not very good.
To conclude the first part of the blog: Codeforces — is definitely not a place for beginners to practice. While more experienced users can practice here, it is hardly suitable for beginners. What to do, I do not know, and why I do not know, I will explain later.
Now let's move on to the second part. Now I want to explain why I think the Codeforces complexity approach is a bad idea.
Let's take a look at a few (again, totally randomly chosen tasks). Let me tell you right away: this will be my subjective opinion. Let's look at problems 858B (858B - Which floor?) and 996B (996B - World Cup). I consider the first one very simple for its complexity, and the second one — very difficult. I solved both problems long ago, but I only remember that when I was a pro, I solved the first one, although with difficulty, but when I was a candidate master, the second one was very difficult for me — I don't even remember if I solved it or not!
This is not to say that the tagging system on Codeforces is not very good, and often confusing. For example, in the DP topic you may come across a prefix-sum problem, and in many tasks the tags are put on the principle "here is a problem on ST/DP/bit operations. But it can be solved with flows. Let's put the tags: graphs, flows. Oh! You can also use ternary search! So let's do it!" So tags really don't always reflect the topic of the problem.
My point is this. You have to train by theme (but tags are also broken), not by difficulty. Especially when you're not that experienced yet. Don't be afraid that you can't do ad-hoc tasks — the main thing is to be good with standard ideas.
Many commenters who write "solve more problems" have, in my opinion, simply (and that's okay) forgotten what it's like to be gray or green. And that's okay: I don't remember solving while I was down, either. But looking at the way my instructor has been giving exclusively standard problems and approaches for a year or two, I'm starting to realize that she's probably doing it right.
Going back to our example — how would such a person know which topics are standard and which are not? At most he can only know the names of the topics. And by the way, apparently, this explains so many gray people who learn the Cartesian tree and Mo algorithm — they don't quite understand what things are needed at what level. And why don't they understand? In my opinion simply because there is no one to explain. So if you're a newbie/pupil and you're reading this, know — you need to learn approaches, not algorithms. And algorithms are better not to learn, but to understand. You should probably learn an algorithm when you encounter a problem at least once/twice in which you can bring the solution to completion, completely and independently, if someone had written the algorithm for you. That is, you have thought up all the steps, all the math, reduced the problem to a well-known algorithm — then you can open it and try to understand it. By the way, if you can't understand it, you can learn it for now — it seems okay to me. You can go back later for understanding (when you have more experience). When I was an expert, I didn't understand the segment tree (really, I was a high school student then, and not even a senior).
So, smoothly passing to the main idea of this blog — I can't imagine how you can practice without a coach. Of course, when all the basic ideas are studied, and the algorithms are perfected, you can move without a coach. But, say, to an expert or even to a candidate master will be much harder without a coach. I know that there are a lot of people who have studied on their own, and reached the heights. It seems to me that you — this is more of an exception to the rule than the rule. I'm very glad that you're doing well. But personally, I realize that without a coach, my progress would have been much slower.
I know that if people who came here to train for interviews. Guys, this is not the place for that at all. That's what LeetCode was invented for — there's a bunch of great problems to prepare for, I've solved a dozen or two myself.
Lastly: in my opinion, Codeforces should decide: should it still be a training ground for beginners, or should it only be a training ground for more senior ranks? Because if it's supposed to be a training ground for greys/greens as well, it doesn't seem to be. Because Educational rounds aren't Educational at all, they're regular Div. 2 rounds, which are only slightly more standard in terms of ideas and approaches. Even Div. 3 rounds, which are designed for greys and greens, have recently started to contain ad-hoc rather than standard tasks again. I understand that this is done for ranking consistency. But let there really be simple tasks for newcomers. In the Edu section there are problems on standard algorithms — believe me, learning these algorithms won't do much good for gray or green.
Therefore, if one wants to create a more favorable environment for beginners, make separate, perhaps unrated, practice rounds. I understand that a lot of effort is put into each Codeforces round by the authors, coordinators, and organizers (myself the author of two rounds and co-author of another one). Maybe that's why Codeforces will probably remain what it is. And you know what? I'm only going to be glad. Surely (but I don't know for sure), there are plenty of places for newbies to train. Let Codeforces remain as great as it is now, with ad-hoc challenges. In my opinion, that's what makes the rounds so interesting and exciting (just please don't make all the tasks on one topic. I won't give you examples, but there are some. Believe me, it's not cool).
Thank you Codeforces for being there!
Hello, Codeforces! Codeforces #765 (Div. 2) took place not so long ago, and one of its authors was me. When an hour had passed since the contest started, I decided to remember the old days and start making fun of the cheaters.
To that end, I decided to take a look at the old cheater groups and see how they were doing.
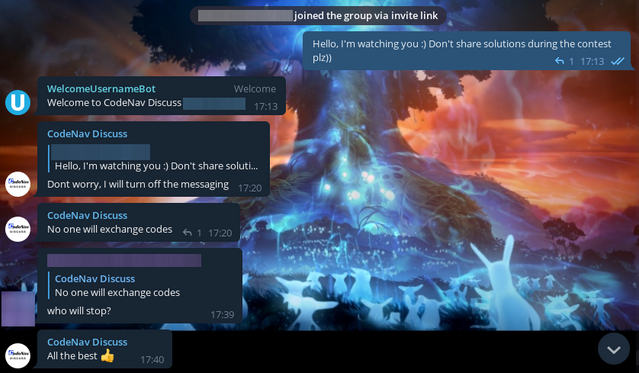
The first group I looked into — is the group where the admin is actively fighting against cheaters. So, there really weren't any cheaters on the round. I think that's a success.
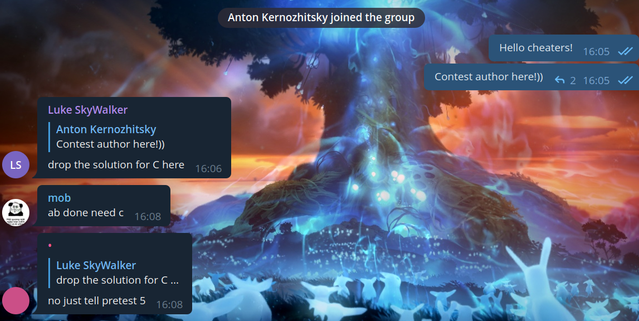
The second group I checked out — it's a group with 2.5k users. I decided that just going in there would be too boring, so I decided to write there that I was a contest author. Here's the reaction of the users:
Can you imagine?! I write that I am the author of the contest, and I am offered to leak the solution to problem C.
As in the last blog, I wrote a completely wrong solution to Problem C so that cheaters would send it and get WA, and then they would get banned by the anti-plagiarism system.
That's the solution:
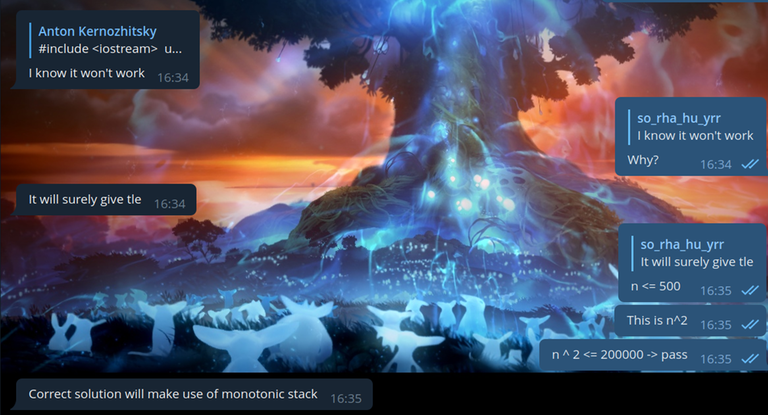
I just dropped this code into the general group:
There are two interesting things here. First — some cheater wrote that "this code takes TL because it has two nested loops". Apparently cheaters don't know how to measure a time limit of a solution, and just think that two nested loops is bad. They probably just learned that it doesn't work in many problems, so they don't even think about writing it. By the way, that problem was $$$n \le 500$$$.
The second — I was banned from this group. Whatever.
But before that, a man wrote to me... You can read our correspondence yourself.
Then I decided to find a new group. And I found a group with... 7.5k people! I was so surprised! I decided to write there that I had the solution to Problem C.
I've had a lot more cheaters writing to me than I ever expected! By my calculations, I had about 20 people write to me, though usually not more than ten.
At first, I was just sending out solutions via private messages. From time to time people would asked me how much it costs, but I told them that I was giving them away for free.
But then a man wrote to me and asked me what my nickname on CF. I told him honestly that I am Wind_Eagle. And he asked me... what's the best way to train. I told him honestly. You can read what I advised him.
But I stopped communicating when I realized what he was really into sports programming for.
Then an apologetic cheater texted me... He apologized for cheating and promised not to do it again.
Then, of course, they started writing about how my solution was wrong. I, of course, replied that it was their problem.
Now I show you the funniest screenshots that I was able to make:
And the conclusion, as usual, is the same: cheating — this is a much bigger problem than it seems.
P.S. By the way, we got a couple of personal messages on Codeforces during the round:
P.P.S. Cheaters, be afraid — maybe I'll come to your groups again!
Training on the tasks of he second stage of the Republican Olympiad in Informatics in Mogilev region
Hello, Codeforces! Today there was the second stage of the Republican Olympiad in Informatics in Mogilev region (Belarus). And I, as the author of this contest, decided to share this contest with you.
I have posted this contest in the gym by the link: https://codeforces.com/gym/103464
Contest rules: contest has 4 tasks for 5 hours, and it has IOI format, i.e., scores and subgroups. As for the difficulty of the contest, I think it will be interesting for people with a rating of 2000 and below, because the most difficult problem in it is not above the level of D2D — D2E.
There is no editorial yet.
Hello, Codeforces! A month ago I have wrote my blog about cheaters. Under that blog, a number of suggestions have accumulated, and there is a number of interesting ideas that could be applied to sabotage a group of cheaters.
I've often seen comments along the lines of:
Well, doing what Ari suggested wasn't really what I wanted to do, but it was worth checking out what would happen if the wrong solutions were sent. I asked some famous user what would happen if I sent the wrong solutions to cheaters. He told me that someone had done this before and that he was quickly debunked.
I wondered whether I could cheat cheaters without getting caught. But for this, I had to do something. As you may remember from the last blog, I had already been featured in various cheater groups. So I needed an assistant to correspond with cheaters instead of me. That helper turned out to be Dmi34. Thanks a lot to him, without him this blog wouldn't have come out! We were on Discord and I told him what to do. He also helped me with writing code, but more on that later. By the way, don't scold him for his knowledge of English. His first language is Russian, after all.
My first idea was to create a group on CF and invite all cheaters there. Then I decided, that it's not a good idea. That's because it's almost impossible to get cheaters into a group on CF because they would probably realize that it would be a bad idea to leak their nickname. Yes, and how to lure them there? They obviously don't need trainings and training tasks.
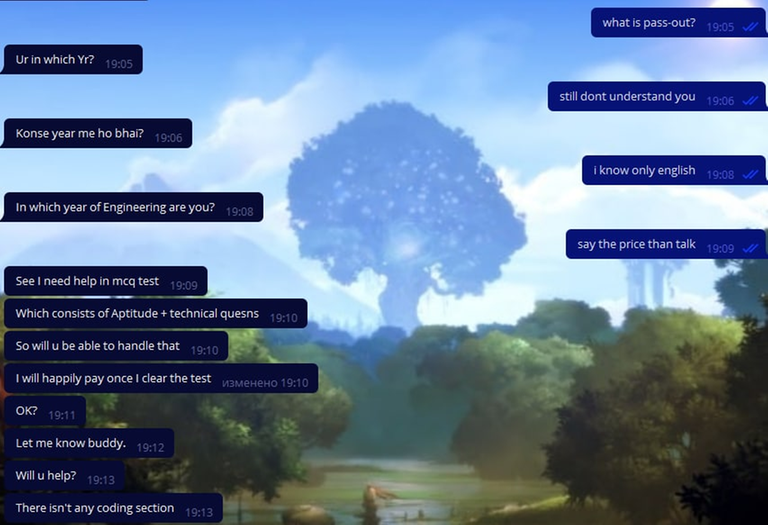
So, I decided to stop at dropping the wrong solutions. Since I had been told that it could not be done, I wondered: why could it not be done? As it seemed to me, I found the answer. It was that the cheaters can't be sure that they have the right solution. So we did the following.
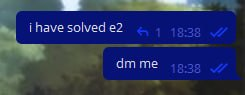
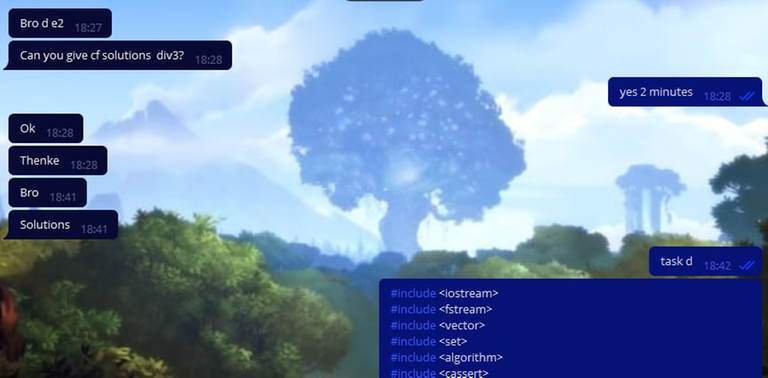
Dmi34 started to solve the problems in the round (don't worry, he's not a ranked participant since he's a candidate master), he solved problems A, B, D and E1. After that, we decided to do wrong solutions to problems D and E2. But we had to do it very carefully, because it was impossible to give them even the slightest hint about the solution. Then we did the following: I wrote the wrong solution for D, which takes both WA and TL (although cheaters often don't understand the difference between the $$$O(n \cdot log(n))$$$ and $$$O(n^2)$$$ solutions). And Dmi34 wrote a brute-force solution on E2, which obviously didn't work.
Links to these codes, they will help you catch cheaters:
So, Dmi34 wrote in the chat:
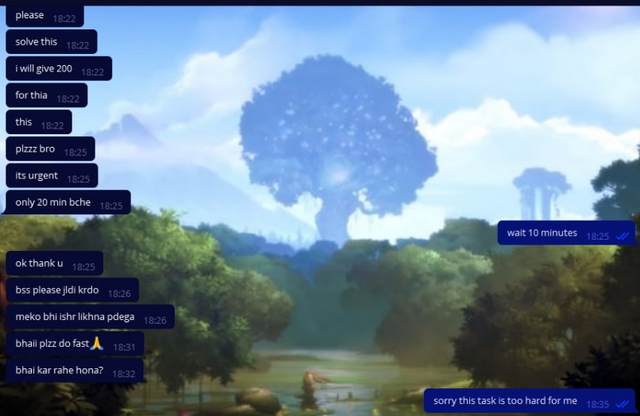
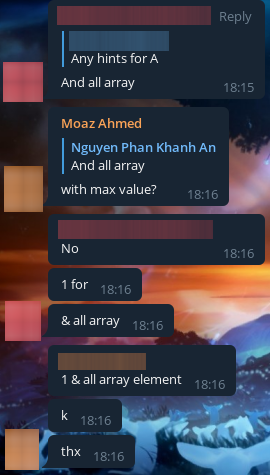
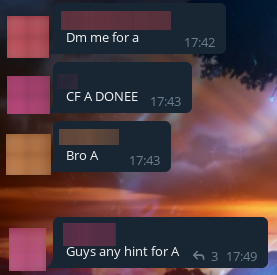
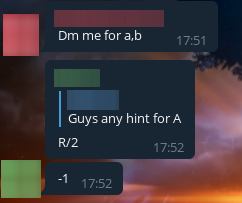
And a wave of cheaters went down! Everyone wanted to know the solutions! We made them wait for a while, and then we started sending them these solutions after all. Here are the funniest and most interesting screenshots of their requests.
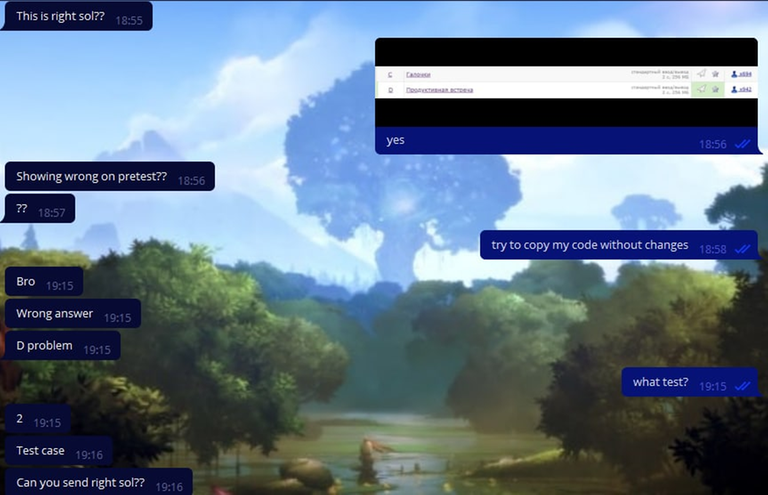
We even had two people write to us asking for help with their admissions tests! I'll show you screenshots of one of them.
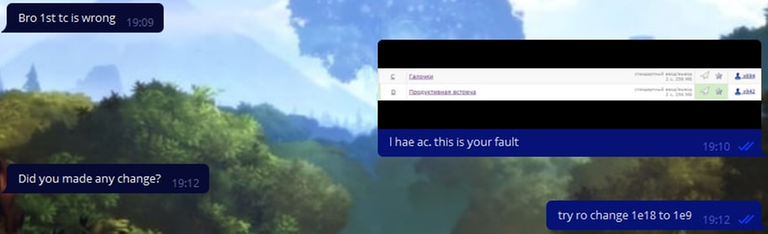
They soon started to suspect something, but we dispelled their doubts with a screenshot: the rectangle is green, my solution works, look for a bug yourself.
By the way, the cheaters took quite a while to respond. Apparently this is because they were changing the codes to avoid getting caught by anti-plagiarism. However, we still forced them to throw our code unchanged:
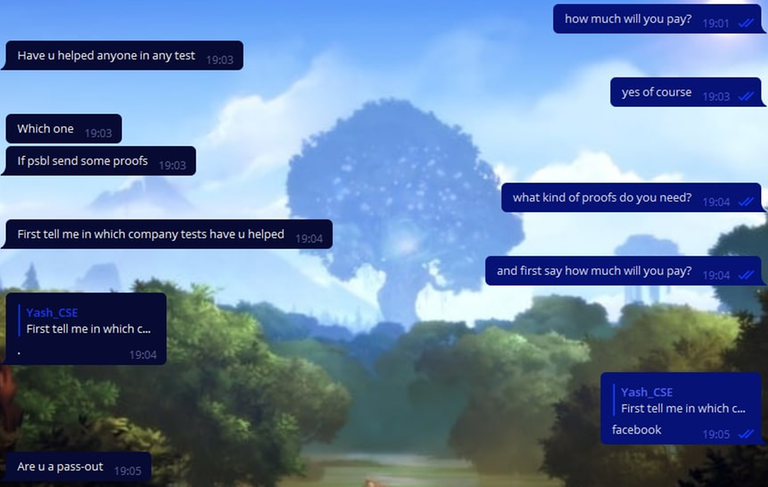
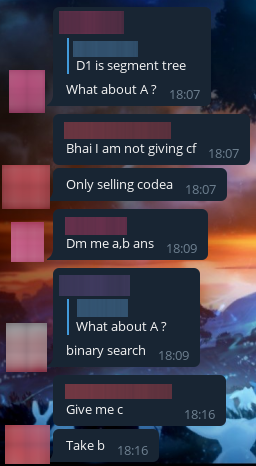
Soon some cheater wrote that he had a solution to the C problem. We messaged him that we want it, but he didn't reply to us. Soon we still find out how much the solution to the problem costs.
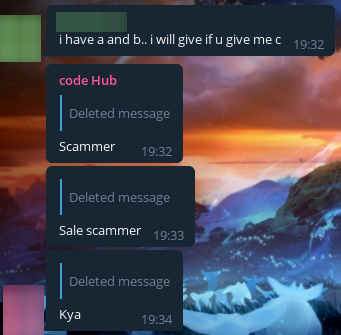
Also, some cheater wrote to us, asking us to exchange the solution to problem C for problem E2. To my deepest shame (sarcasm), we agreed, and dropped him the wrong code, and got his code in return.
Here's his solution. By the way, it doesn't seem to work:
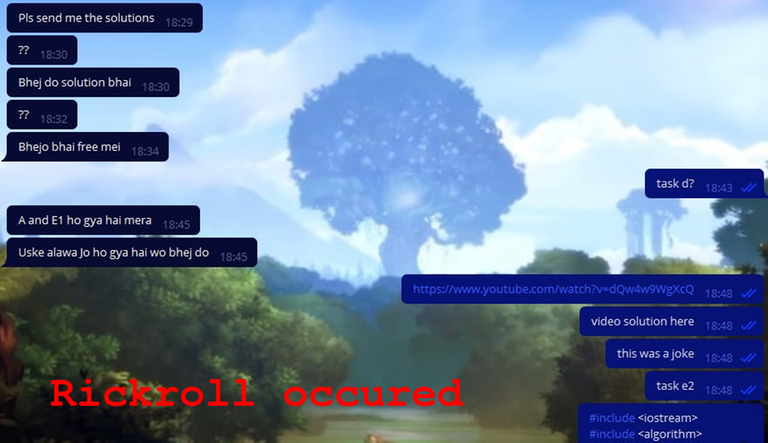
After having a lot of fun, we decided to admit that they were just being trolled, and threw them funny messages. I thought they would react to it, but almost everyone was cool with it. Amazing calm!
What's funny, Dmi34 kept getting messages asking him for the solutions! Didn't it get to them even after reporting that they were being trolled? It feels like they just don't read the conversation!
The funniest cheater we have found:
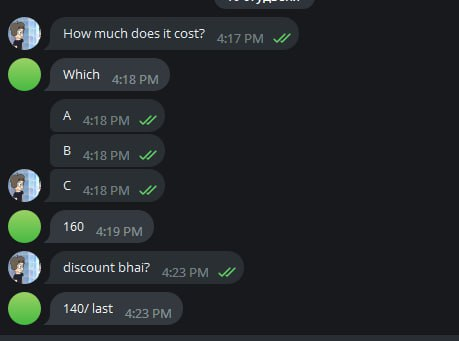
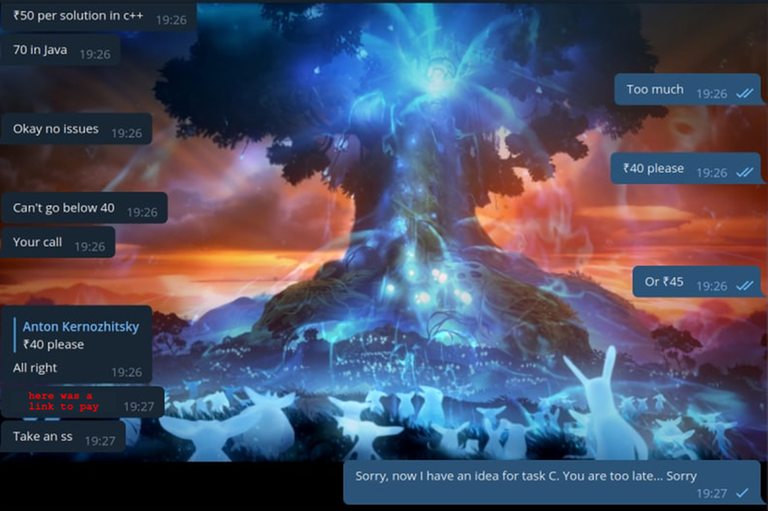
Next, I personally joined another group with cheaters. I don't want to advertise them, but their admin wrote a comment under my last blog, you can check it out if you're interested. To my surprise, they... Really banned from texting during the contest! As soon as I joined, the bot wrote a message saying that Wind_Eagle had joined the chat... And I immediately (!) got a message from some cheater who offered me to buy the solution to his problem C. I asked how much the solution cost. So, now, without looking in the spoiler, try to guess how much it costs, and then stop by and check yourself.
I haggled for decency. When he said he was ready to sell, I wanted to write that I didn't need it, because I supposedly just thought up the solution to the problem. But he texted me his wallet number. I will not show it, I do not remember it and his number deleted, because it is too much. However, the cheater himself, I put him on blacklist so he wouldn't write to me again.
Speaking of cost. Remember that group that asked for help with the test? Well, helping on a hiring test costs a mystical <<200>> (I suspect rupees).
Now it's worth telling about my correspondence with the admin of this group. Why tell me about it though, read it for yourself.
So, what can be learned from this blog? First of all, cheater catching enthusiasts — your turn! You can see the codes I sent them, and if you want, you can look for cheaters. Second, I showed you how much the solution costs and how actively they sell. And third, I showed that the tests for joining the company are also being bought and sold, which was particularly disappointing to me.
So what conclusion can be drawn from all of this? This. Cheating — it's not just cheating, it's also a business! So, like any semi-legal business, it is extremely difficult to eradicate.
P.S. Dear cheaters, please forgive me for the inconvenience! I did not want to hurt you too much, in the end, you will get back your rating in a couple of contests. All our wrong solutions you got as quickly as possible and for free . If I caused you any inconvenience, please forgive me! I won't do it again!
P.P.S. Thanks gepardo for checking the blog.
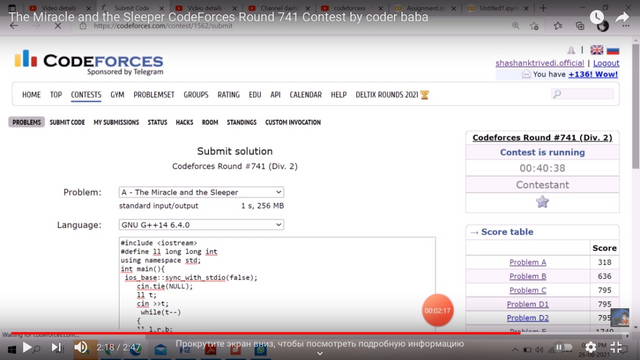
Hello, Codeforces! Not too long ago there was my second round, Codeforces #741 (Div. 2). Before it started, I wondered: surely there will be a lot of cheating on my round, just like on any other? So I decided to do something unusual.
As you know from a blog about cheaters, it's easy to find telegram/youtube channels with cheaters. So I decided to find a couple and join them...
So, the first telegram group I found was [link not available yet]. There weren't too many cheaters in it but they were, here's an example:
I joined this telegram group, and there was a meaningful dialogue:
This may seem unbelievable, but the admin of the group actually banned participants from texting for the duration of the contest! So, I've already had at least some impact on the level of cheating during my contest. By the way, this channel published a couple of videos on my 1562A, 1562B and 1562C editorials. Pretty good ones, by the way.
The second group I found was probably the largest group with cheaters on telegram: [no link yet]. I repeated the procedure:
However, this group ignored my appearance! And continued, as if nothing had happened, exchanging solutions in private messages or somewhere in discord:
A little later, they even wrote half the solution for problem 1562A:
Some famous user came to my rescue:
As you can see, the practice of swapping solutions is extremely popular in the cheat community (give me a B and I'll give you a C):
However, there are cheaters who are also scammers! Apparently, he got the solution of another cheater and he didn't sent his solution to this cheater:
And then something extremely interesting happened. I started getting personal messages from... Cheaters themselves! And they started to expose other cheaters! Apparently, they have absolutely no cohesive team.
One man (I am very grateful to him), gave me links to a couple of youtube channels, where there were cheaters. On one of them I went in the middle of the contest and also wrote in the comments, but I'll talk about that later. By the way, on one of the channels we can see the nickname of the author. A little later, when it comes to youtube channels, I'll show you who it was, and hopefully he will get banned.
So, here's what was written to me about youtube channels:
Somebody couldn't even believe that I actually authored the contest:
Unfortunately, I don't have the most interesting messages saved because I blocked this cheater for direct insults, but to summarize, there were messages like this:
After 30 minutes
After 30 minutes
And then I banned him in Telegram.
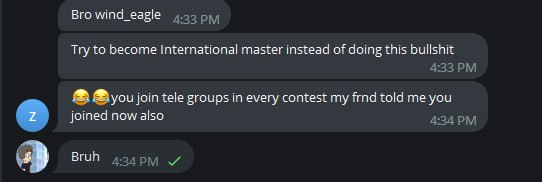
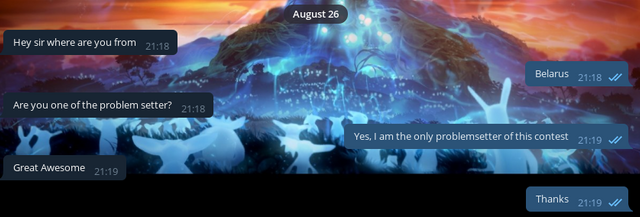
The third and final group was a relatively small group of cheaters [no link yet]. By the way, this group was suggested to me in the personal messages by one of the cheaters from the previous two groups. I repeated the procedure here. There was an unexpected meeting with a fake of a known user and also I wasn't believed that I am Wind_Eagle:
In fact, I found it interesting to watch people refuse to believe that I am really the author of the contest. They threw funny smiley faces and jokes, but they couldn't admit it. Even when I made a screenshot showing that I was in my account and could edit the announcement, they still wouldn't believe me, saying that I had edited the HTML page. So, dear cheaters! I'm real! :)
Now let's talk about youtube channels. I found two of them: [link not yet] and [link not yet]. Unfortunately, the second channel has already finished broadcasting, so I left him a funny comment:
By the way, here's a screenshot of his screen:
I hope he will get banned.
I don't have any screenshots from the first channel, unfortunately. All I can say is that I wrote a message there, "Hi, I'm Wind_Eagle. Stop the stream or you'll be banned." By the way, in the comments, unlike in telegram, the tasks were discussed much more openly, codes and ideas were exchanged there in public.
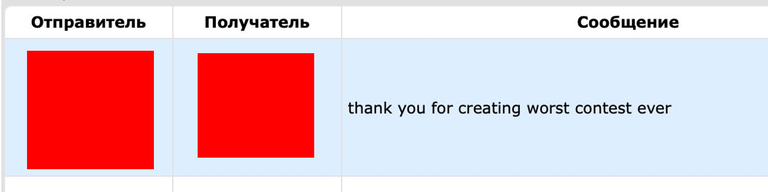
Now a little bit about the good stuff. I received quite a few messages from users of these cheat telegram groups, in which they... say thanks for the contest! I've chosen a few of the best ones:
What does one want to say as a conclusion? It's all very sad, frankly. There are not just a lot of cheaters. Not just very many. There are too many of them. I'm afraid that there is only one way to fight cheating on CF: to close such telegram/youtube channels. Otherwise there is simply no way to deal with this problem.
In conclusion I want to answer a few questions upfront:
Q: Why wouldn't you stop cheaters from doing their dirty work!
A: And how could I prevent them? Drop the wrong code? One cheater would have checked it and written about it. Incorrect codes often appear in such groups.
Q: Do you have time during the contest to do this nonsense?
A: Well, usually the writers answer the questions. But when there weren't many questions, I did messaging. I apologize if I made anyone wait a long time for an answer to a question.
P.S. Do you think I should leave links to cheater groups/channels? I'll read the comments, and if this idea will be supported, I'll post the links.
Will we, will you...
Can we, can you, can we change?
1562A - The Miracle and the Sleeper
1562D1 - Two Hundred Twenty One (easy version)
1562D2 - Two Hundred Twenty One (hard version)
Choose the way, five paths there for you to find
Turn the page, the question lies between the lines...
Hello, Codeforces!
I hoped that once there will be my second round, and finally, here it is!
I am very glad to invite you to the Codeforces Round #741 (Div. 2), which will take place in Aug/26/2021 17:35 (Moscow time). This round will be rated for the participants with rating lower than 100000110100 (2100).
My thanks to:
antontrygubO_o for rejecting problems A his great coordination of this round! Thanks!
gepardo made a lot. There wouldn't have been this contest if he didn't help me. Thanks!
EIK this is the person who taught me competitive programming — my Informatics teacher. Thanks!
MikeMirzayanov for Codeforces and Polygon platforms. Thanks!
You for participating in this round. Thanks!
You will have 2 hours and 15 minutes for solving 6 tasks, one of which will be divided into easy and hard verions.
One of the problems will be interactive. So, it is recommended to read the ultimate guide on your favourite type of problems before the round.
I hope you will enjoy the round!
Round testers: 244mhq, BigBag, Savior-of-Cross, Kuroni, programmer228, MagentaCobra, Vladik, bWayne, kassutta, asrinivasan007.
Score distribution: 500-1000-1250-(1250+1250)-2750-3500.
UPD: It was decided to add a sixth task to the round to balance the difficulty.
UPD2: Editorial is here!
UPD3: Congratulations to the winners!
Hello, Codeforces!
I am very glad to invite you to the Codeforces Round #672 (Div. 2), which will take place in Sep/24/2020 17:35 (Moscow time). This round will be rated for the participants with rating lower than 2100.
All tasks were made by me, but gepardo helped me a lot with the last two tasks, probably these tasks wouldn't have appeared if he didn't help me.
My thanks to:
antontrygubO_o for coordinating this round. With this great coordination only good tasks remained in the contest.
gepardo made a lot, there wouldn't have been this contest if he didn't help me. He not only helped me with making last two tasks, but also helped me to understand how to make tasks for Codeforces rounds. Thanks!
EIK this is the person who teached me competitive programming — my Informatics teacher. Thanks!
programmer228, Hacktafly, K1ppy inspired me to make this round, listened for the every task idea, provided feedback and testing. Thanks!
Osama_Alkhodairy, vamaddur, thenymphsofdelphi, Devil, Ari, SleepyShashwat, TechNite, Monogon, Tech.Maniac, Kavit_Kheni for testing the round and the tasks. Thanks!
MikeMirzayanov for Codeforces and Polygon platforms. Thanks!
You for participating in this round. Thanks!
You will have 2 hours for solving 5 tasks, one of which will be divided into easy and hard verions. I hope you will enjoy the round, I tried to make short statements and strong pretests interesting tasks.
Score distribution: 500 — 1000 — (1000 + 1250) — 2000 — 3000
UPD: The editorial is available. English version will be ready after the system testing is over.
UPD2: The english version of the editorial is ready.
Hello Codeforces! Recently I've become an author of a Codeforces Round #672 (Div. 2) (it will take place soon). Immedaitely after placing my contest in a timetable, I have been attacked by the messages of a following content:
"Hello, can I be a tester of your codeforces round? I want to gain experience in testing CF rounds" etc.
I want to tell you something. If you didn't know, the process of making and testing the round looks like this:
1) Author makes codeforces round. Of course, he/she also needs to test his/her round carefully.
2) When this work is done, round coordinator invites some people to test your round. Both author and coordinator can choose testers at this stage.
3) When testers looked through the round and did their work, round can be placed into the timetable. After this no testers required.
So, now, I hope, now you know that when contest is already done and scheduled, it makes no sense to write such messages to authors. By the way, this messages are not annoying. I just want you to not to waste your time.