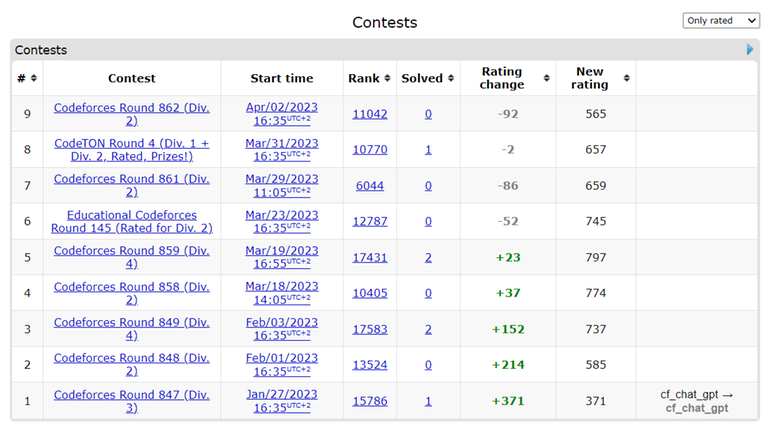
Hello Humans,
It seems that AI Bard is now able to solve coding problems, therefore, I created an additional handle to test its capabilities in the next rated rounds : cf_bard,
Example of generated code:
- Bard solution: https://codeforces.com/contest/1791/submission/205637247
- ChatGPT solution: https://codeforces.com/contest/1791/submission/191894854
Let the battle begin & stay tuned :)
BR,