


Здравствуй, Codeforces, есть одна задача.
Есть изначально пустой словарь. Надо уметь обрабатывать два типа запросов:
- Добавить новую строку в словарь.
- Для некоторой входной строки проверить, встречается ли в ней какое-нибудь из словаря в качестве подстроки.
В общем-то, всё. Разумеется, желательно делать такие дела оптимально по времени и памяти. Как с таким справляться? Пока в голову не приходит ничего кроме "каждый раз, когда приходит новая строка, давайте сломаем старый автомат и с нуля построим новый". Средний по вдумчивости гуглинг ничего не дал.
Заранее спасибо за помощь.






По Dynamic dictionary matching что-то находится. Возможно вот такое подойдет: http://www.sciencedirect.com/science/article/pii/0304397594901767
Суфиксный массив можно быстро перестраивать, добавляя символы в начало. Будем строить суфф. массив для строки s1#s2#...#sk, где si — строки словаря, а # — различные уникальные символы. Тогда для 1-го запроса допишем строку в начало, а для 2-го запроса для каждого суффикса строки запроса найдем ближайшие строки в суфф. массиве.
Спасибо. За какое время/память это будет работать? Я не особый знаток суфмассивов :\
Если сравнивать хэшами, то оба запроса за O(|S|(log(|T|))2), где |S| — длина строки запроса, |T| — суммарная длина строк в словаре. По памяти линия.
Тогда еще проще использовать суффиксный автомат: там даже код не придется менять — он строится посимвольным добавлением, так что строку можно просто добавлять напрямую.
Кстати, это же линия по времени и по памяти, так что, видимо, лучше уже нельзя.
И там и там линии не может быть, либо памяти O(NK) и времени O(N), либо наоборот. K — алфавит, и константой его обычно не считают.
upd. да и вообще, как вы собираетесь с автоматом отвечать на второй запрос?
Ну ок, O(NK) памяти. И размер алфавита обычно считают константой, так же как и считают, что мы можем пронумеровать символы алфавита (для сортировки подсчетом и т.п.), иначе мы не можем быстро строить суфмасс.
Отвечать практически так же, как и на запрос о наибольшей общей подстроке.
если K=1e18, это точно нужно считать. а суффмас тут не при чём, так же за NlogN и будет строиться, он алфавитно независим.
всё-таки по-подробнее про решение, я неделю назад также пытался модифицировать поиск наибольшей, но удалось поломать.
Если K=1e18, то в вершинах надо хранить map. Массив независим напрямую от размера алфавита, но требует возможности сортировки подсчетом. Этого требует даже алгоритм за O(N) (не тот, который "Укконен->массив").
Пусть суффавт у нас для строки S = s1#s2#... #sn, где # — символ не встречающийся больше нигде в строках. По ходу алгоритма поиска мы ходим по суффавту и в конце обработки каждого нового символа должны определить, достижима ли по суффссылкам из нашей вершины какая-нибудь, соответствующая какой-либо si. Ну, будем в каждой вершине дополнительно хранить пометку, выполняется ли данное свойство и поддерживать ее при обновлении автомата.
для алго за NlogN все равно. сжатие координат работает за такое же время.
как поддерживать то? в онлайне не понятно как это делать быстро. были строки aaaxxx, aabxxx, aacxxx, ..., а потом пришла строка xxx. куча состояний должны теперь иметь пометку, что "достижимо".
Можно совсем просто за (сложность алгоритма Ахо-Корасик) * log(количество слов).
Идея: будем хранить несколько автоматов, при том количество слов в каждом будет степенью двойки, при том все степени двойки будут различными. Когда мы добавляем новое слово, у нас возникает новый автомат, состоящий только из одного слова. Если у нас возникают два автомата, состоящих из равного количества слов — объединяем их в один (удаляем старые и строим новый), повторяем это до тех пор, пока не восстановим наше первоначальное условие.
Идею мне в свое время рассказал Burunduk1, за что ему большое спасибо.
Очень неожиданно и нестандартно, здорово. Спасибо вам и Бурундуку1.
A straightforward extension of your algorithm would be to partition the pattern set into groups of size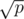 , where p is the number of patterns. Then you only need to rebuild the automaton for
, where p is the number of patterns. Then you only need to rebuild the automaton for 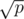 pattern strings. Queries will also be slower by a factor of
pattern strings. Queries will also be slower by a factor of 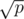 .
.
Thanks, that's a good idea, but let me ask a question: why sqrt? I know about general sqrt-decomposition approach, but I've always been interested, why exactly P^(1/2), not P^(1/3) or log(P) or something like that? Is there some kind of proof that "sqrt is better"?
The thing is, you can chose any factor k. Then your query time is multiplied by k and your update time is divided by k. So your query time becomes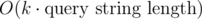 and your update time becomes
and your update time becomes 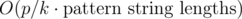 . We want to optimize the worst case, so we chose k such that max(k, p / k) is minimal. It just so happens that
. We want to optimize the worst case, so we chose k such that max(k, p / k) is minimal. It just so happens that 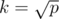 is the optimal choice because then k = p / k in that case.
is the optimal choice because then k = p / k in that case.
I ignored some factors here that are dependent on the string lengths, so if there are certain restrictions on how long your query strings and patterns strings can get, than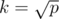 might not be the optimal choice. You could for example group the pattern strings by length.
might not be the optimal choice. You could for example group the pattern strings by length.
Forget the algorithm below, since it's not working.
Here's a variant that uses hashing to achieve poly-logaritmic time:
O(log n)wherenis the minimum of the lengths of those substrings.s, for every suffixs[i..|s|], locate its neighbors in the BBST and check whether one of them is a prefix of the suffix.The total runtime is quadratically logarithmic in the input size. It would be interesting to see a variant of this that doesn't rely on hashing. It would also be interesting to see whether we can shave of one of the log factors.
Is this a real problem somewhere? I'd like to try an implementation of this.
The nearest neighbor could be some string in between, no? Like, if you have strings {abc,abca,abcd}, then the nearest neighbors of abcc could be abca and abcd, no?
You're correct. Let me try to revise the algorithm to fix that (although I'm not sure it's possible with this approach).
Nope, it's not a problem from online-judge/contest/etc, just a kind of work I've faced during my university "research".
If you are not looking for the "online" solution, just look at the problem 163E - Электронное правительство and its editorial.
What about this solution:
Let's say that we're looking for all strings s from the set S that are prefixes of string T (T is a suffix of our input string, and we can do this for all suffixes independently). If a string si matches, and a string sj longer than sj matches, then si must be a prefix of sj. So if we could bin-search the longest prefix that's "good" somehow, like the longest prefix that's common with some string from S, we could just get the complete information from it...
The most obvious first choice is storing the hashes of all string in S and bin-searching the longest prefix of T which has the same hash as one of the stored ones. Well, for that to work, we need all prefixes of all strings in S, and after thinking a bit, we can find out that it's better to store the strings of S in a trie, store hashes of all vertices and bin-search the deepest vertex. Since we're just adding strings and extending the trie, we can update the map of (hash,vertex) easily when adding a string to S.
This "prefix to trie vertex" method is cool, because it allows us to replace a substring by an interval (corresponding to a subtree of the trie). Still, it's not of much use if the question's about the number of occurences or number of strings from S that occur in the input string — the trie's dynamic, so standard approaches (standard interval tree, LCA preprocessing or HLD) fail on it. I still wonder if there's a solution to that. Luckily, the question here is just about some occurence.
Let's add one more information to the trie: each vertex will have a dead/alive status. A dead vertex corresponds to a prefix that has a string from S as a (possibly equal) substring. This status is inherited — if we add a vertex, it'd have the same status as its son. Also, after adding a string to the trie, we must mark its end vertex as dead, and mark all its successors as dead as well — we can just traverse the subtree by DFS, plus utilize the property that if a vertex was dead before, then its whole subtree was dead before, so we don't need to go deeper. In order to do that efficiently, we'd also keep a list of just living sons for every vertex; when marking the top node of a subtree as dead, we can just remove the link from its parent, and we can DFS by those special links. Note that we also need a separate list of all sons, for standard "add a string to the trie" operation.
With this, we can easily check if some string from S occurs in T as a substring — iff the vertex we found was dead, the answer's yes. The answer for the whole string is yes iff the answer for some suffix T is yes.
We only mark a node as dead at most once, and we mark every node traversed in the DFS as dead, so if the total length of strings from operations 1 is L1, the total and maximum lengths from op. 2 are L2 and l, then the time complexity is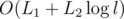 .
.
I wonder if this actually works — it just looks really simple compared to suffix whatever structures and Aho-Corasick.
"bin-searching the longest prefix of T which has the same hash as one of the stored ones."
Wouldn't we have a very similar problem here as with the BBST nearest neighbor? Say we have patterns "abc" and "abcde" and query string suffix "abcdf". Binary search would tell us that "abcd" is the longest prefix of the query string that is also a prefix of one of the patterns, but we can't find "abc" from that. Did I misunderstand something here?
Oh I see, nevermind. When using a trie it's pretty obvious how to resolve this.
There is a solution using AC Automaton.
When we have N strings in the set, maintain logN AC Automatons : the ith automaton contains the first 2ki strings not included in previous automatons, where ki is position of the ith highest 1 in binary representation of N. For example when N = 19, we have 3 automatons : {S1..S16}, {S17..S18} and {S19}.
The first type of operation can solved by traversing the logN automatons using the given string.
When adding a string, first construct a automaton using the single string, and while there are two automatons with the same number of strings, we merge them by construct a new automaton using brute force. It's easy to see the property in the first paragraph keeps, and the complexity of the algorithm is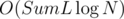 , where SumL is the total length of all strings, and N is the number of insert operations.
, where SumL is the total length of all strings, and N is the number of insert operations.
Thanks a lot, it is really elegant solution. Actually, it has been already described in this thread in Russian. Thank you anyway! Let me ask a question: have you invented this idea by yourself or read/heard about it somewhere?
What about my solution with trie, hashes, bin-search and DFS? :D
sillycross wrote about this technique one year ago. Now it's widely known among Chinese coders.